
第三届盘古石杯 初赛 复现
月光穿过百叶窗,在书房地板上投下斑驳光影。钟无声站在智能锁前,手指轻触屏幕,几行代码在掌中屏闪过,门锁悄然开启。
他环视书房,檀木书架堆满文件夹,落地台灯将影子拉得老长。拉开抽屉时,玉兰香从窗台飘入,混合着线香余韵。钟无声翻动文件,指尖划过烫金账本时,书房门轴发出轻微响动。
贾韦码站在门口,手中还攥着车钥匙。钟无声合上账本的动作很慢,窗外巡逻车的灯光扫过波斯地毯。当喉结在贾韦码颈间滑动时,玉兰花瓣正落在血渍边缘。
书房恢复寂静,落地灯将钟无声的影子投在紧闭的智能锁上,像一幅静止的画。
在诈骗团伙中,贾韦码和钟无声是两个核心人物。贾韦码因违反保密协议,被钟无声盯上了。一天深夜,钟无声利用智能锁的漏洞,悄无声息地潜入贾韦码家中。他四处搜寻账本,但一无所获。就在他准备离开时,贾韦码回来了。钟无声一把抓住他,逼问账本的下落。贾韦码惊恐万分,最终在威胁下说出了藏匿之处。钟无声拿到账本后,为了灭口,残忍地杀害了贾韦码。随后,他带着账本消失在夜色中,留下一个血腥的现场。
挂载密钥:
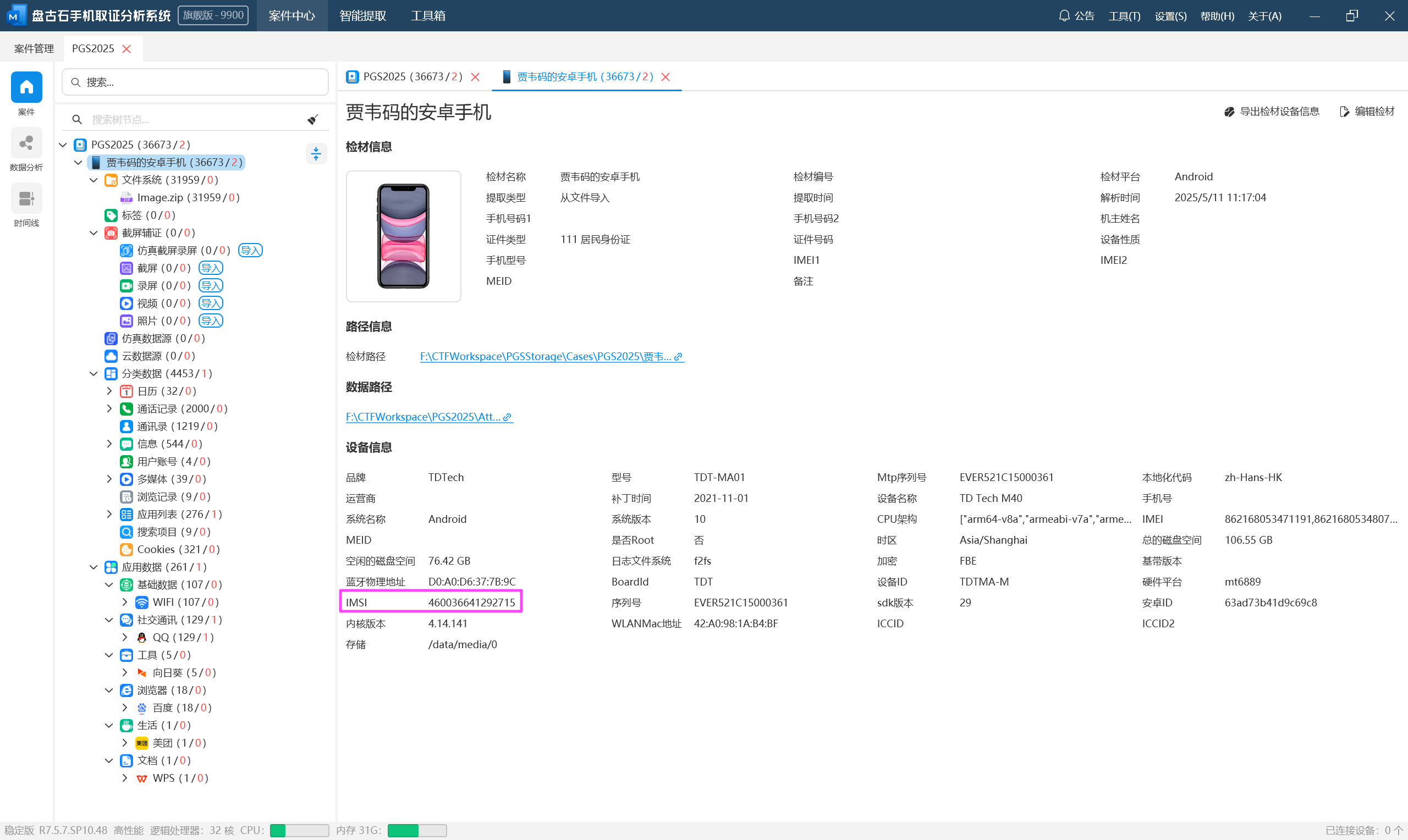
460036641292715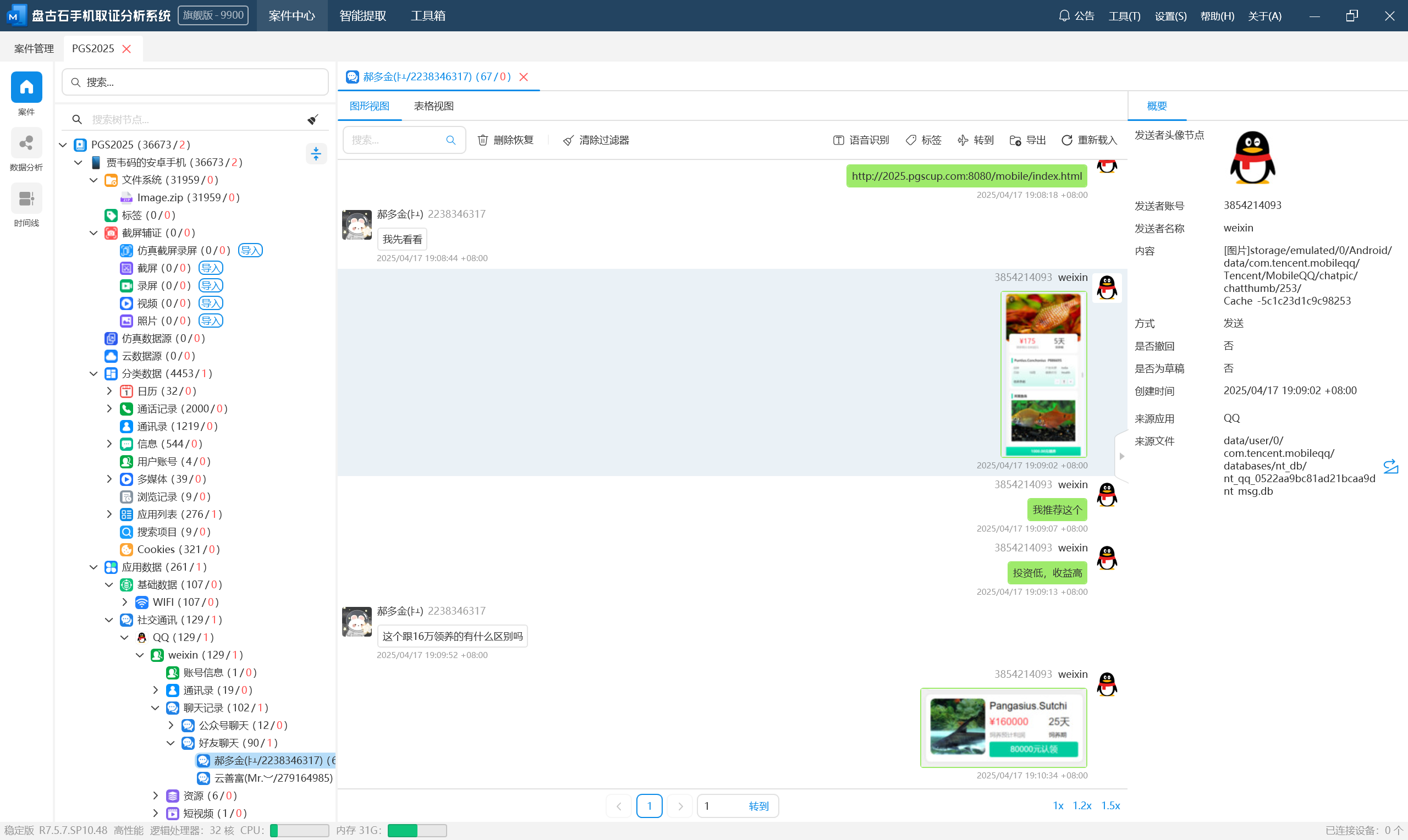
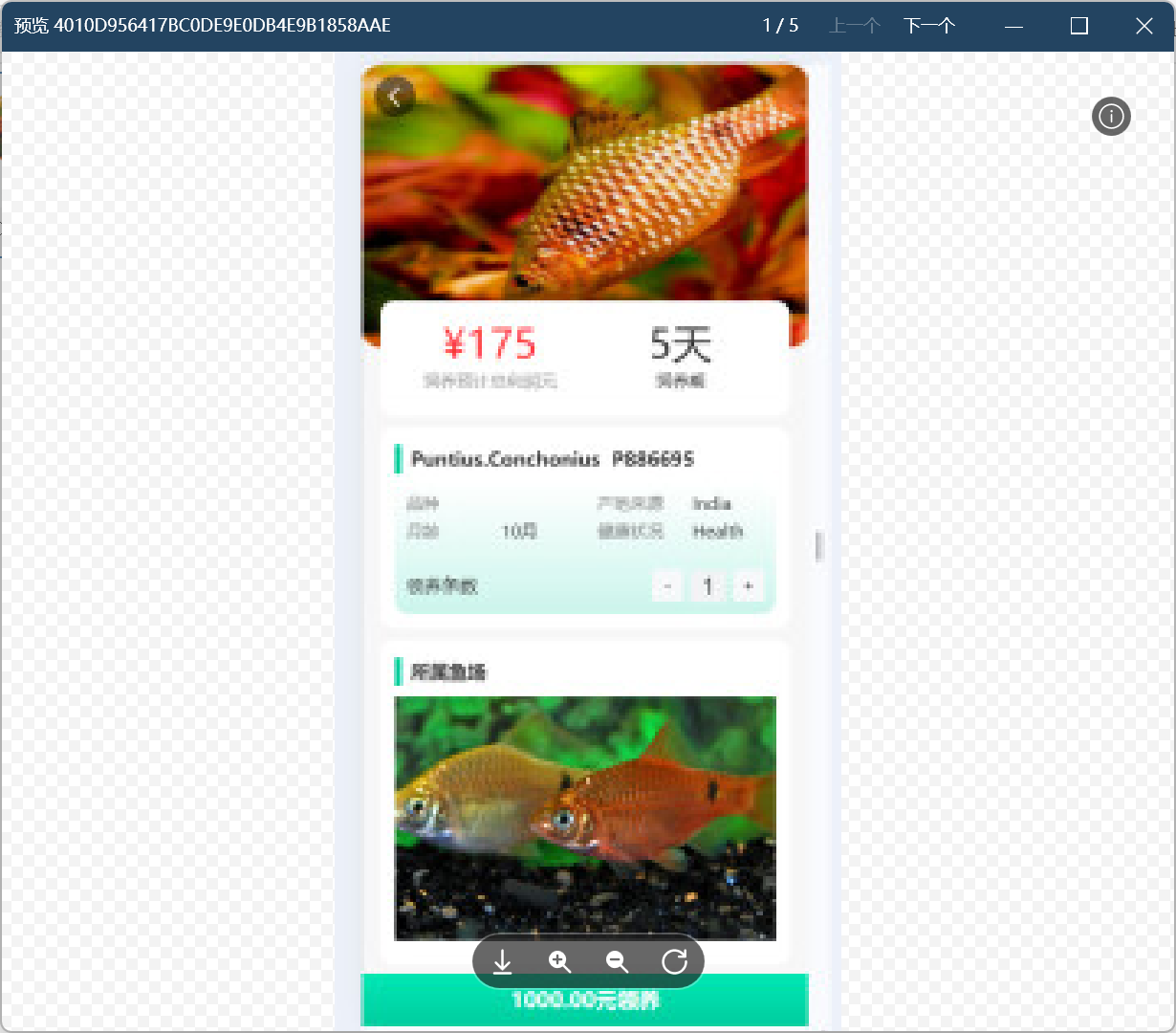
175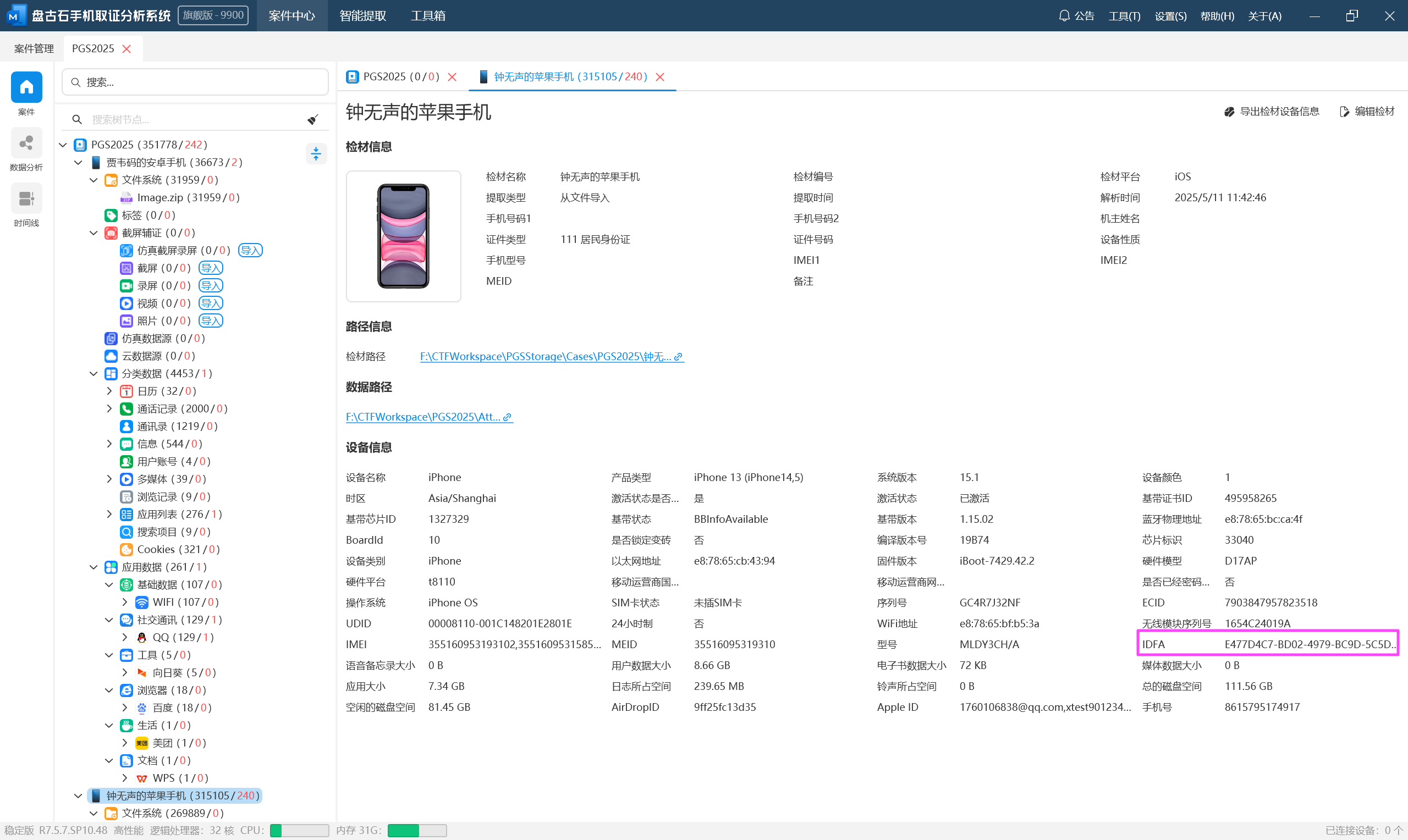
E477D4C7-BD02-4979-BC9D-5C5DE7BD1F17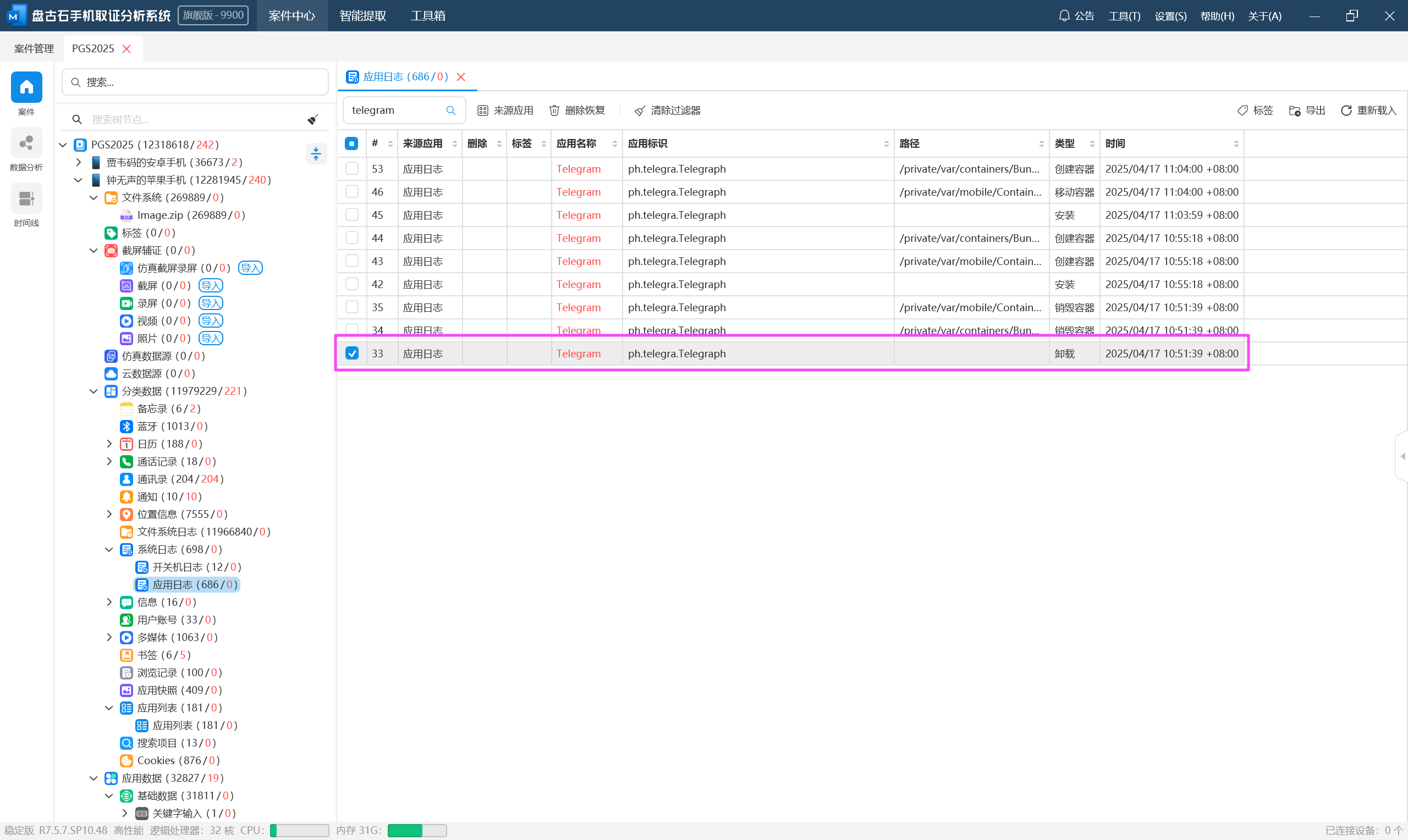
2025-04-17-10:51:39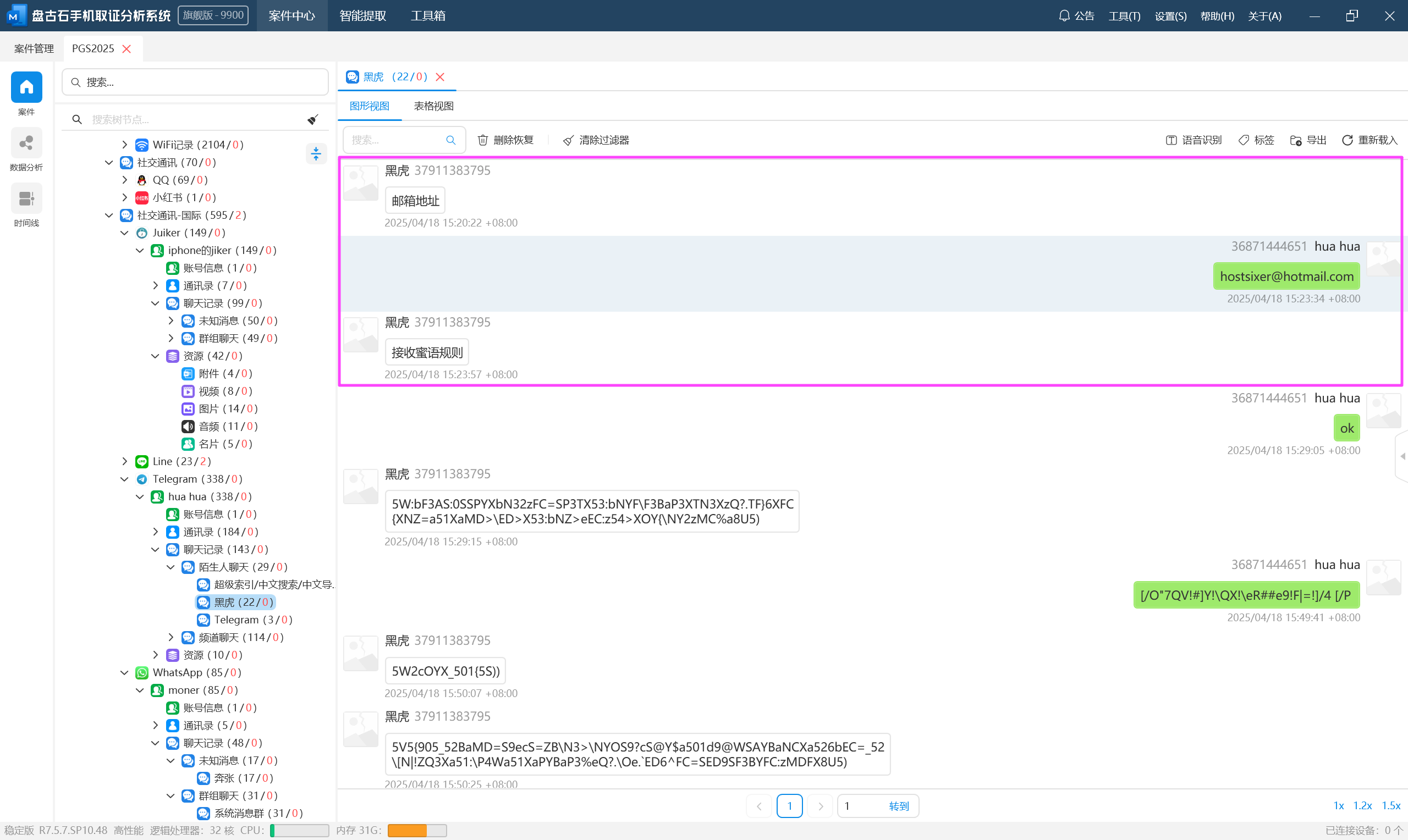
hostsixer@hotmail.com
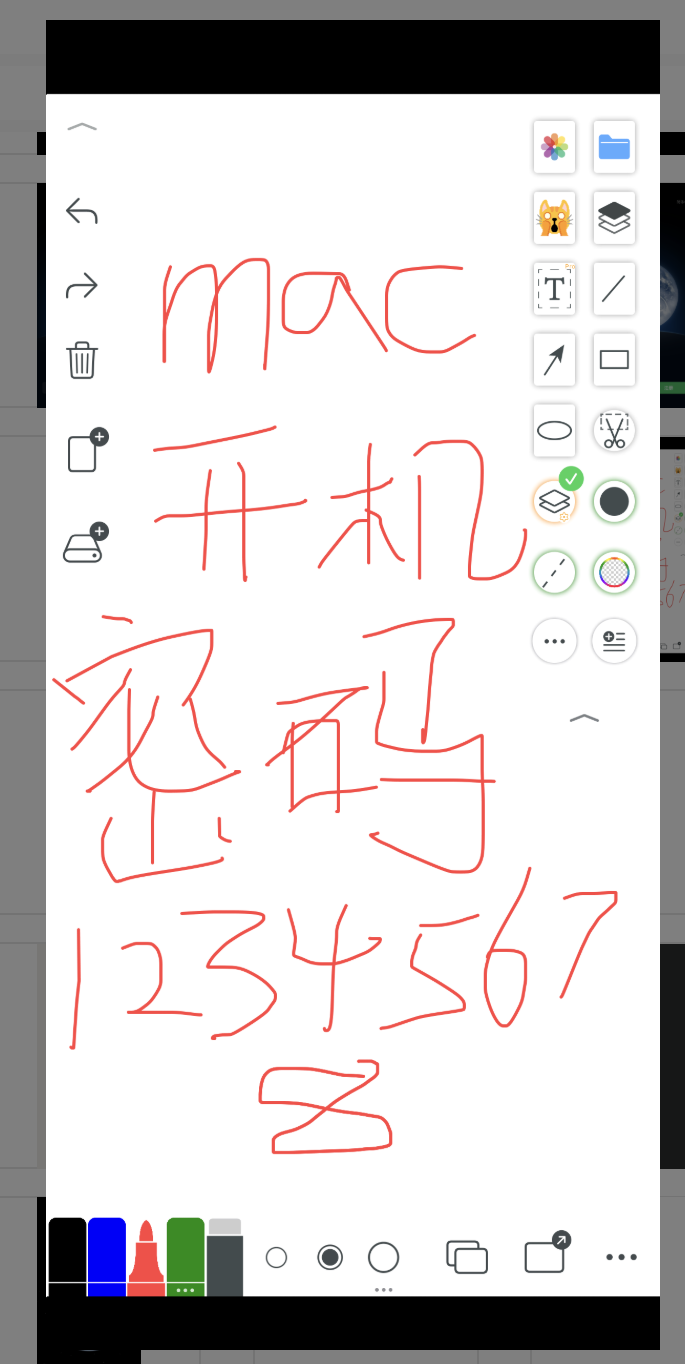
12345678
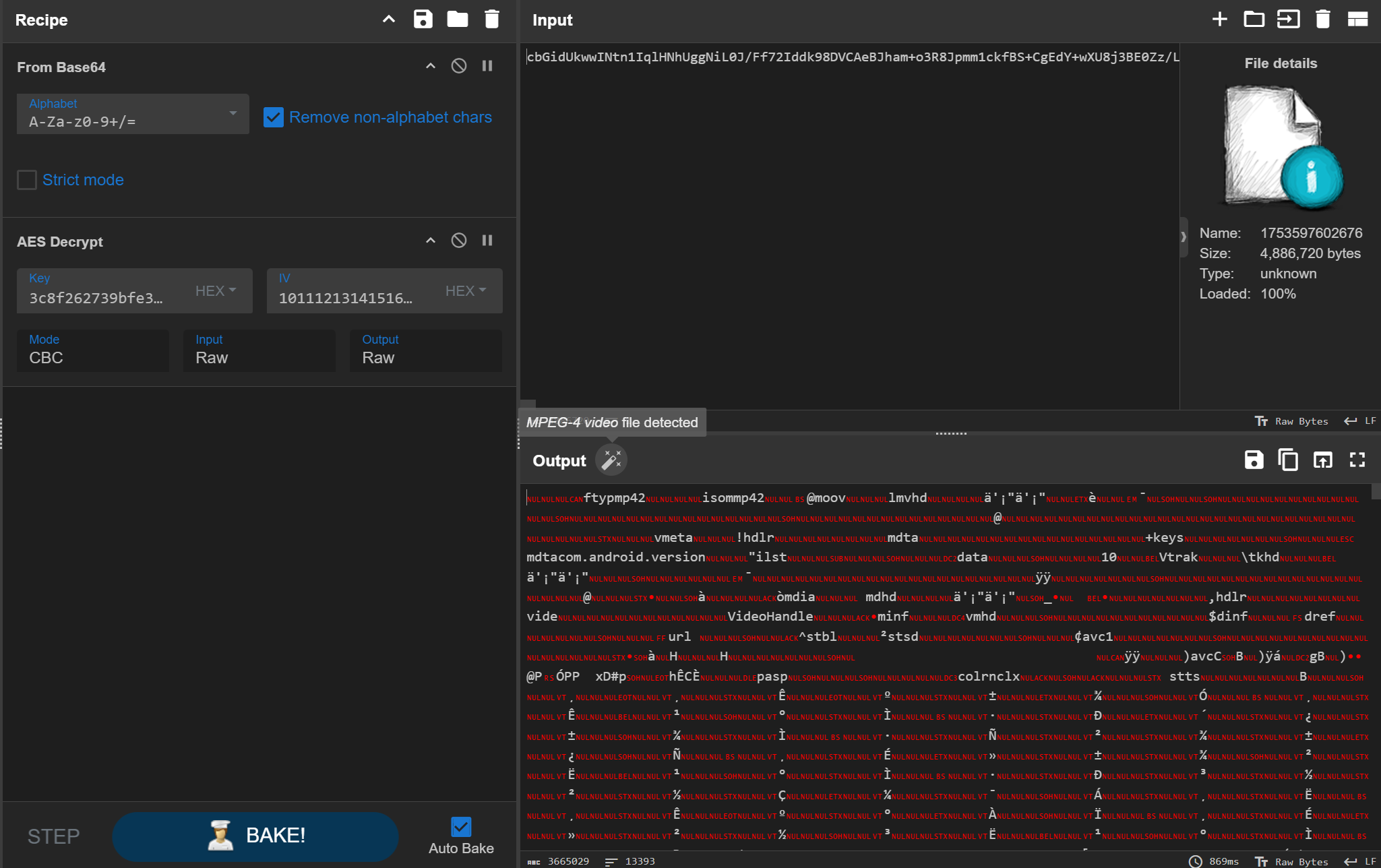
去看一下 2.mp4,发现中间有几帧弹了个图片出来,这个就是解密规则的一部分。

2.mp4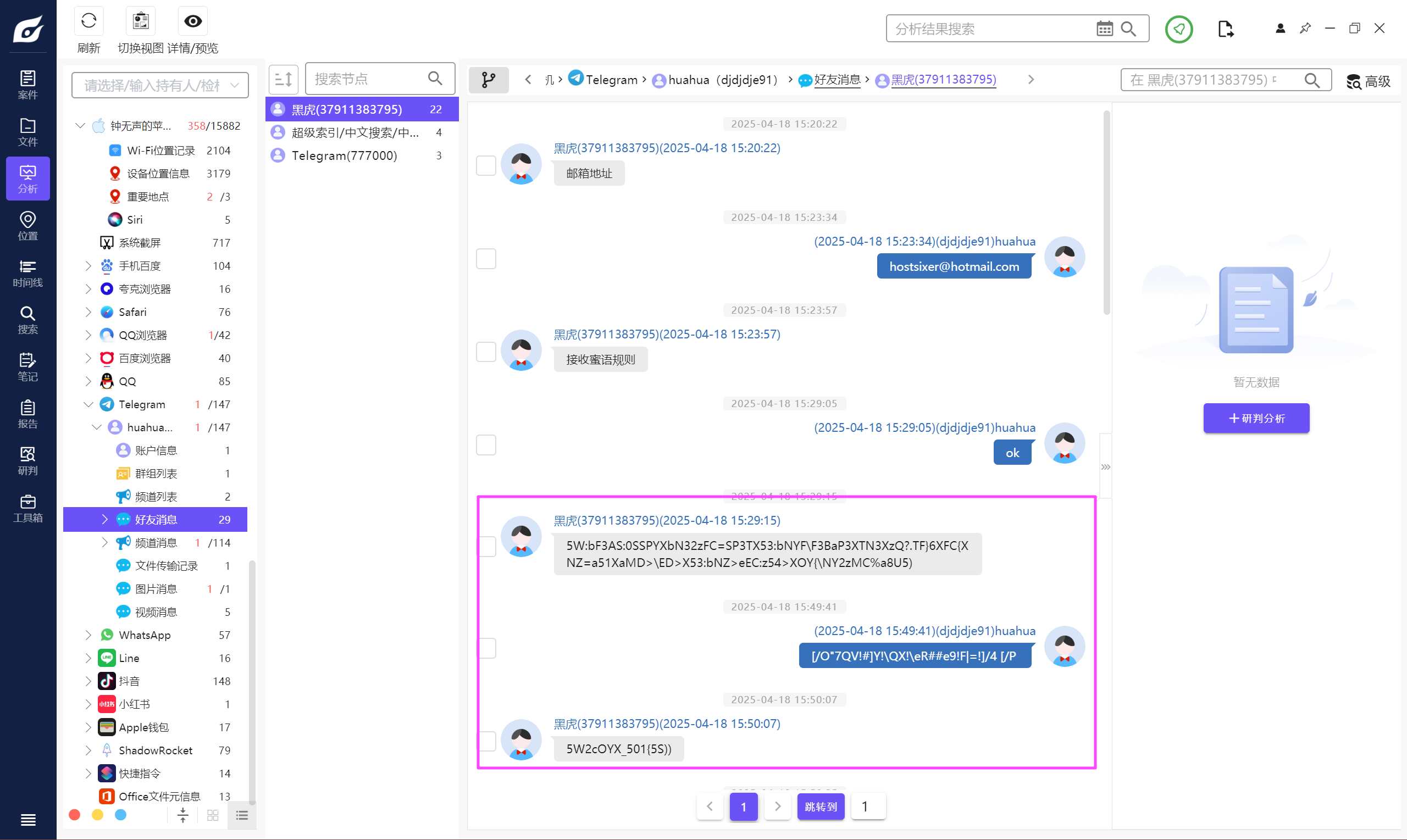
tg 的聊天似乎是某种暗号,也就是上面说的“蜜语”,可以在这个手机找到聊天话术 V2 和 V3 两个 word 文档,里面就是“蜜语”的规则,其实就是一个替换。
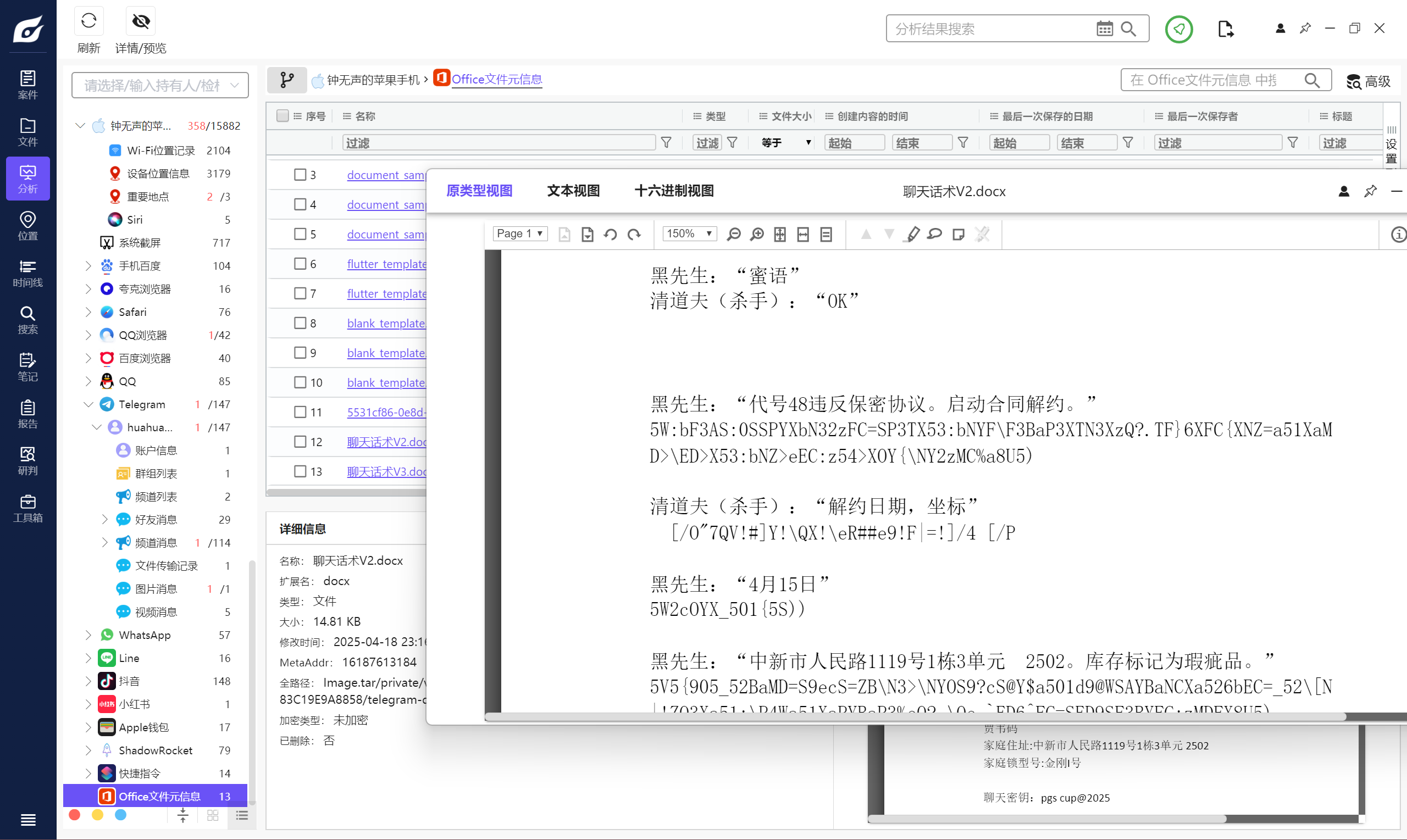
整理一下,得到解密后的聊天记录,这里为了方便看直接模拟了一下。
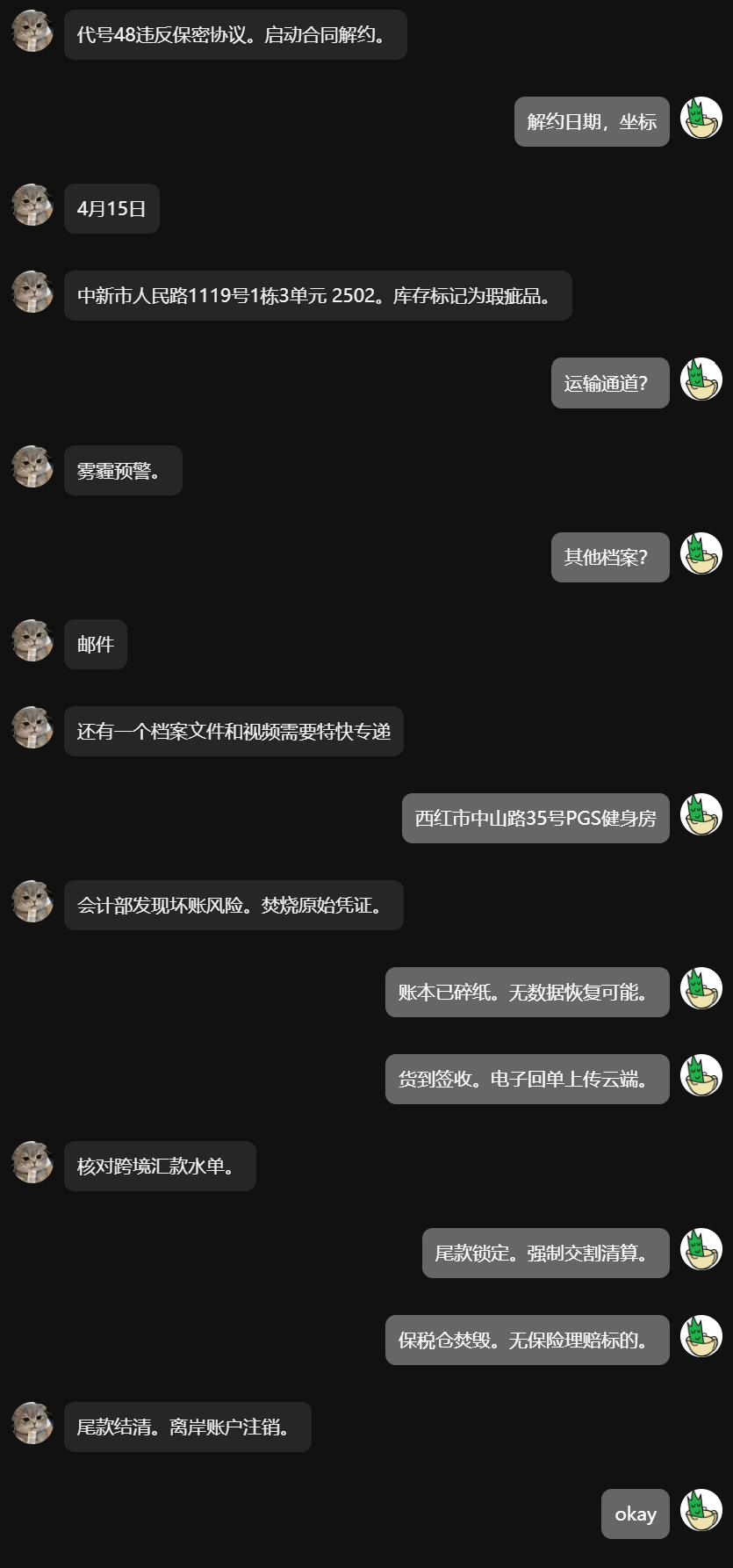
可以得知贾韦码的代号是 48。
48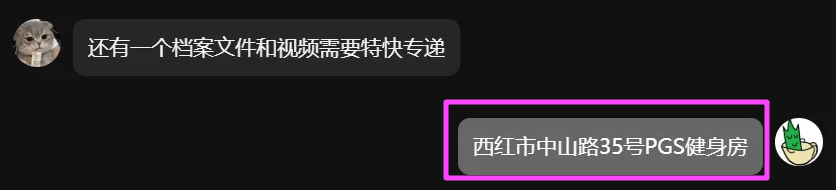
西红市中山路35号PGS健身房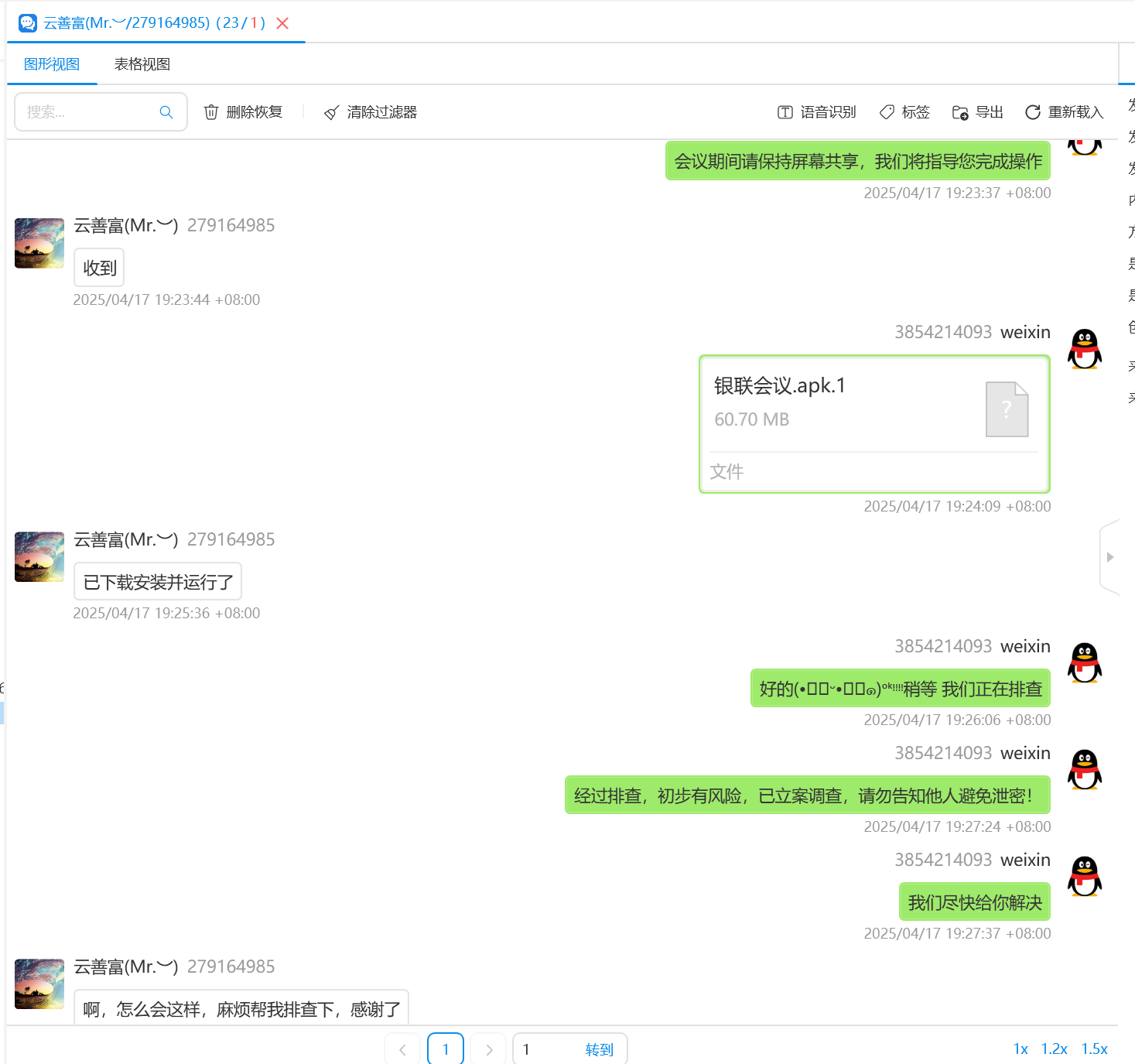
com.carriez.flutter_hbb``
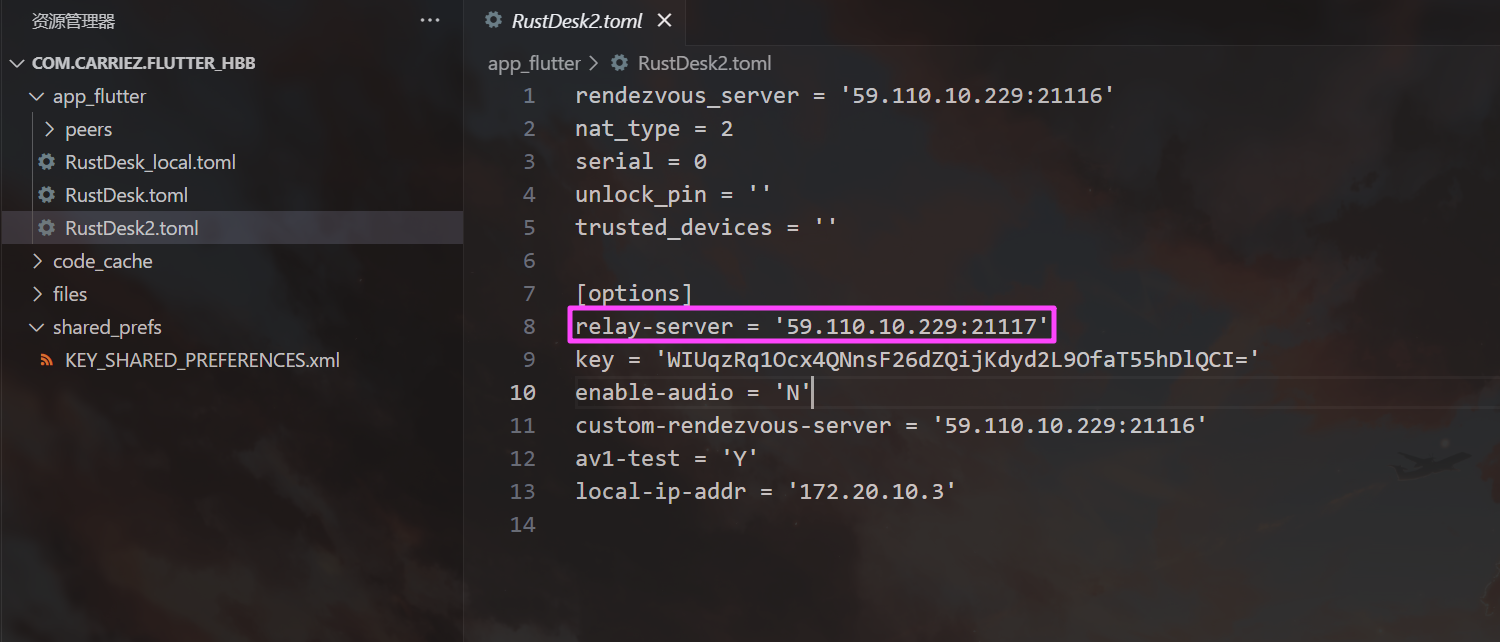
relay-server 就是我们的中转服务器。
59.110.10.229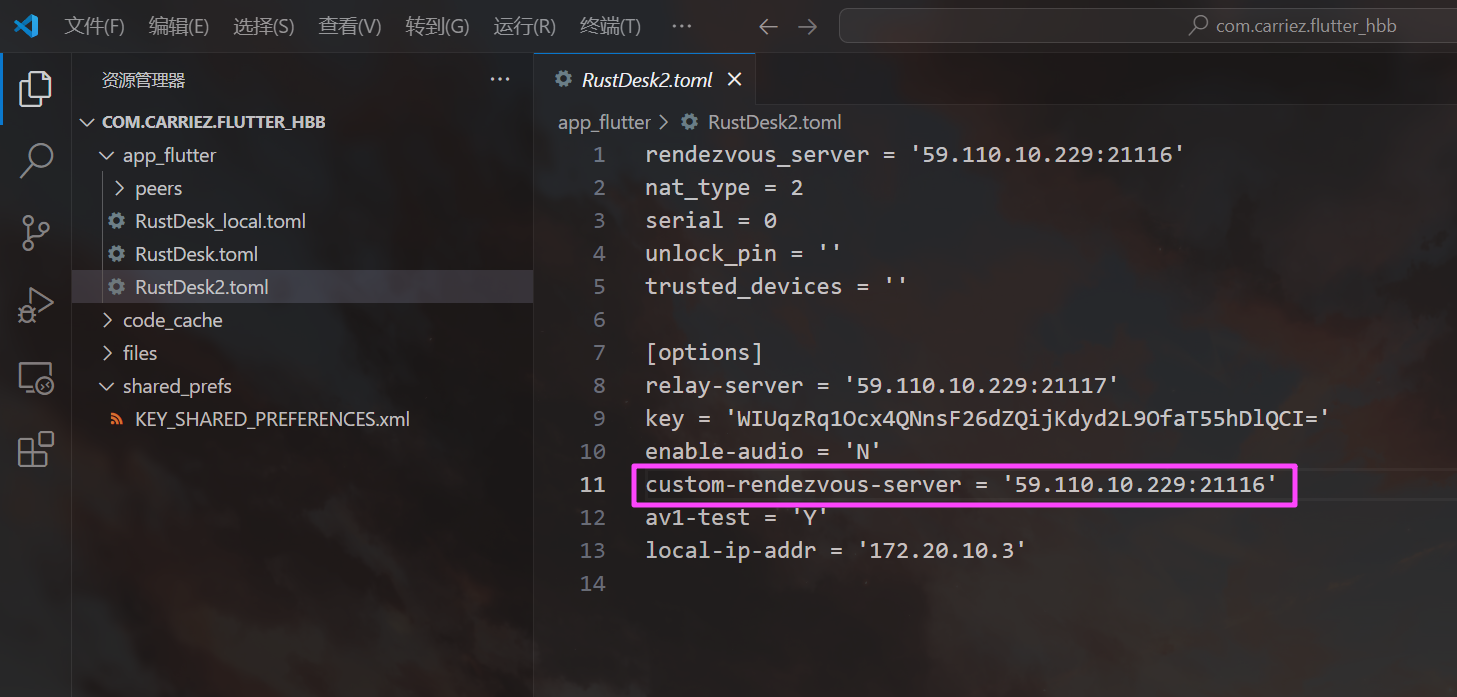
21116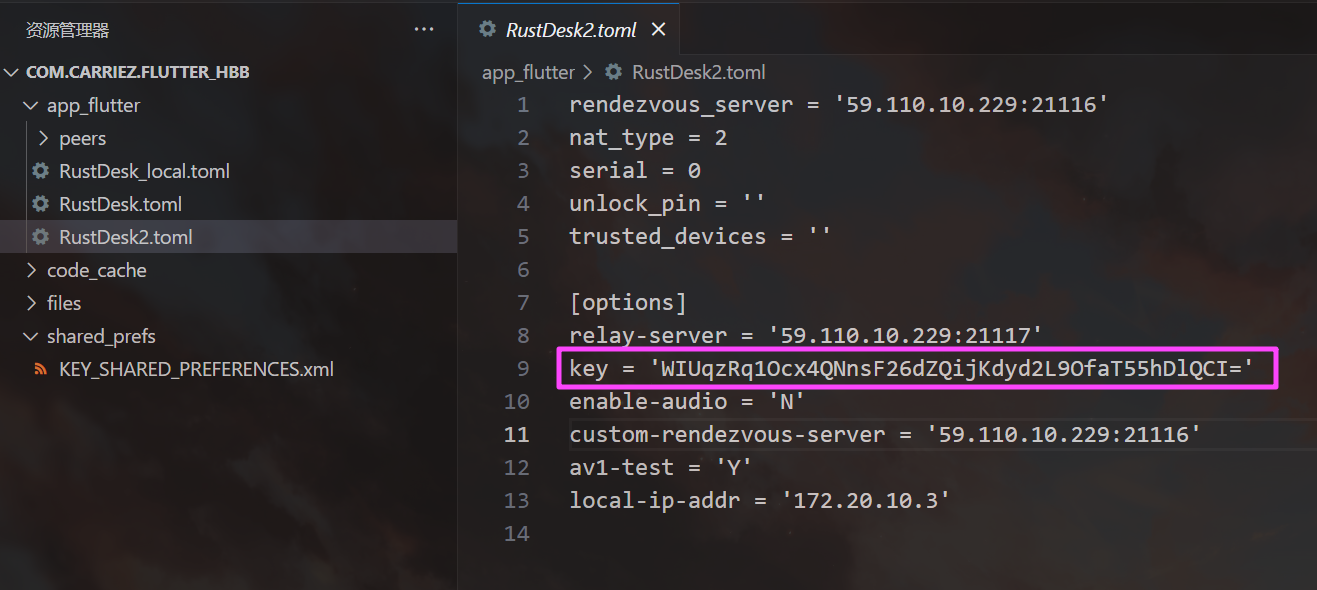
WIUqzRq1Ocx4QNnsF26dZQijKdyd2L9OfaT55hDlQCI=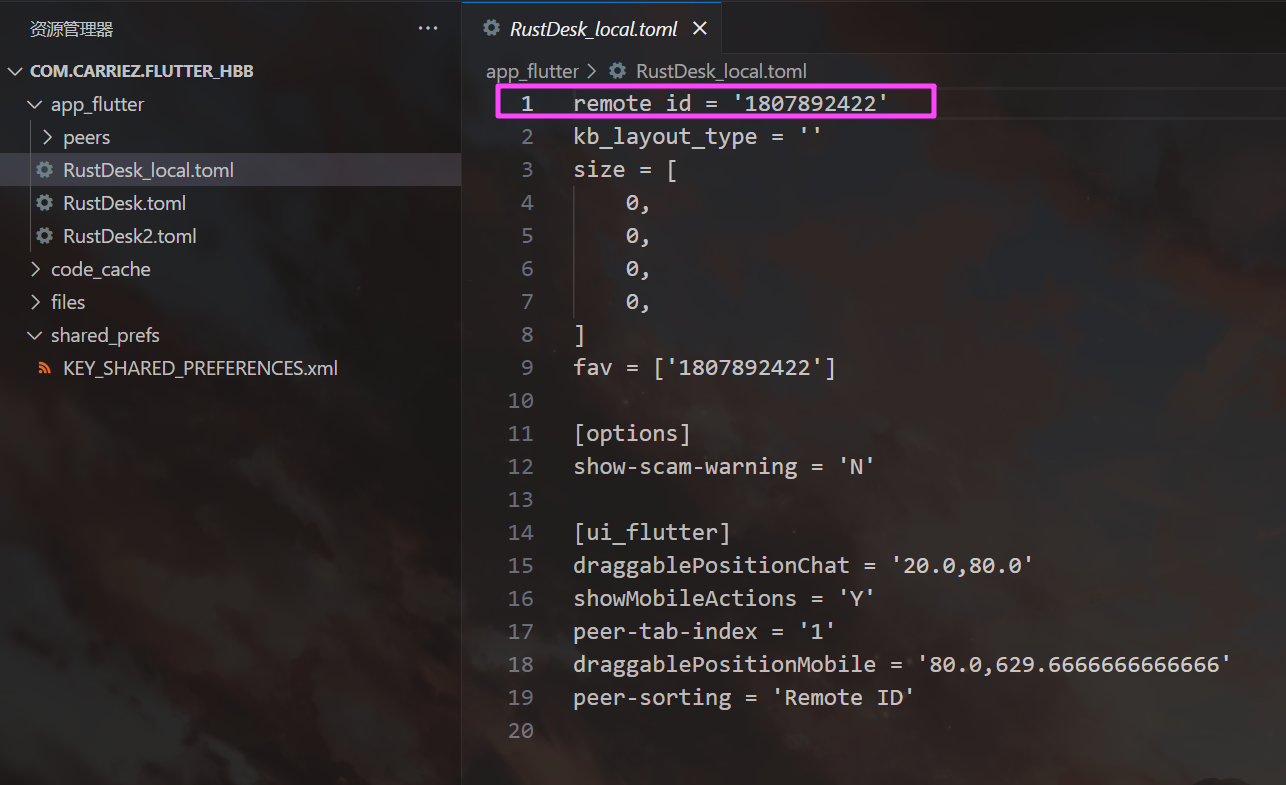
1807892422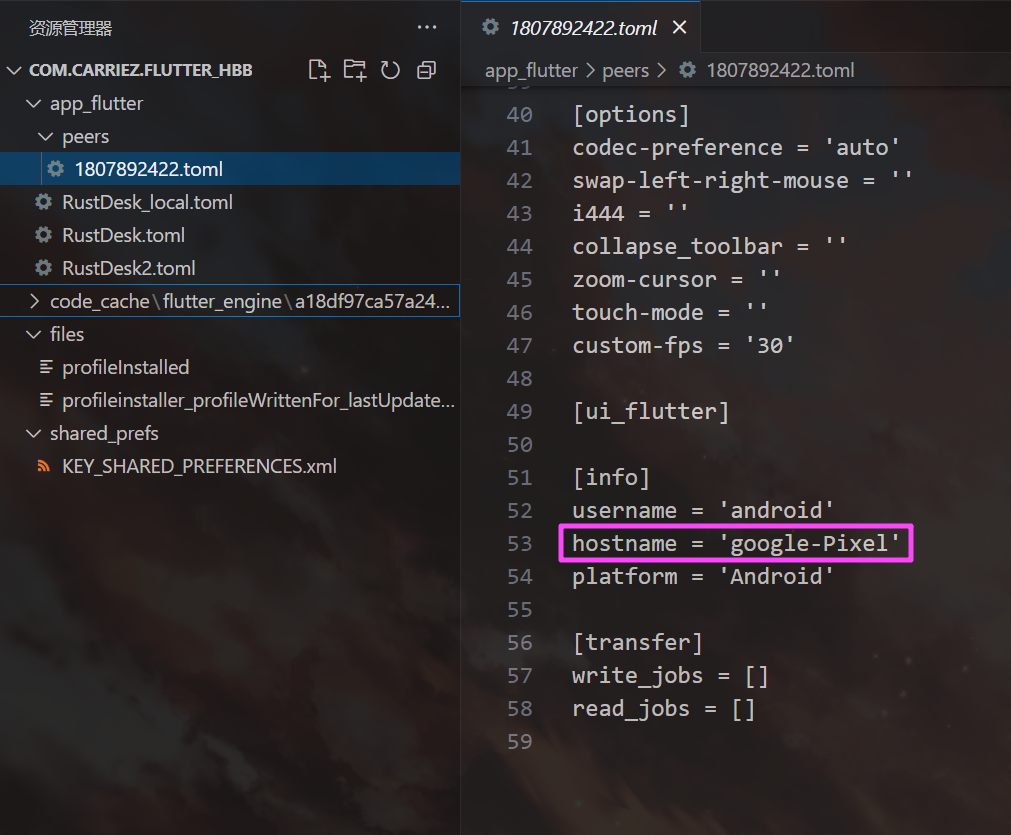
google-Pixel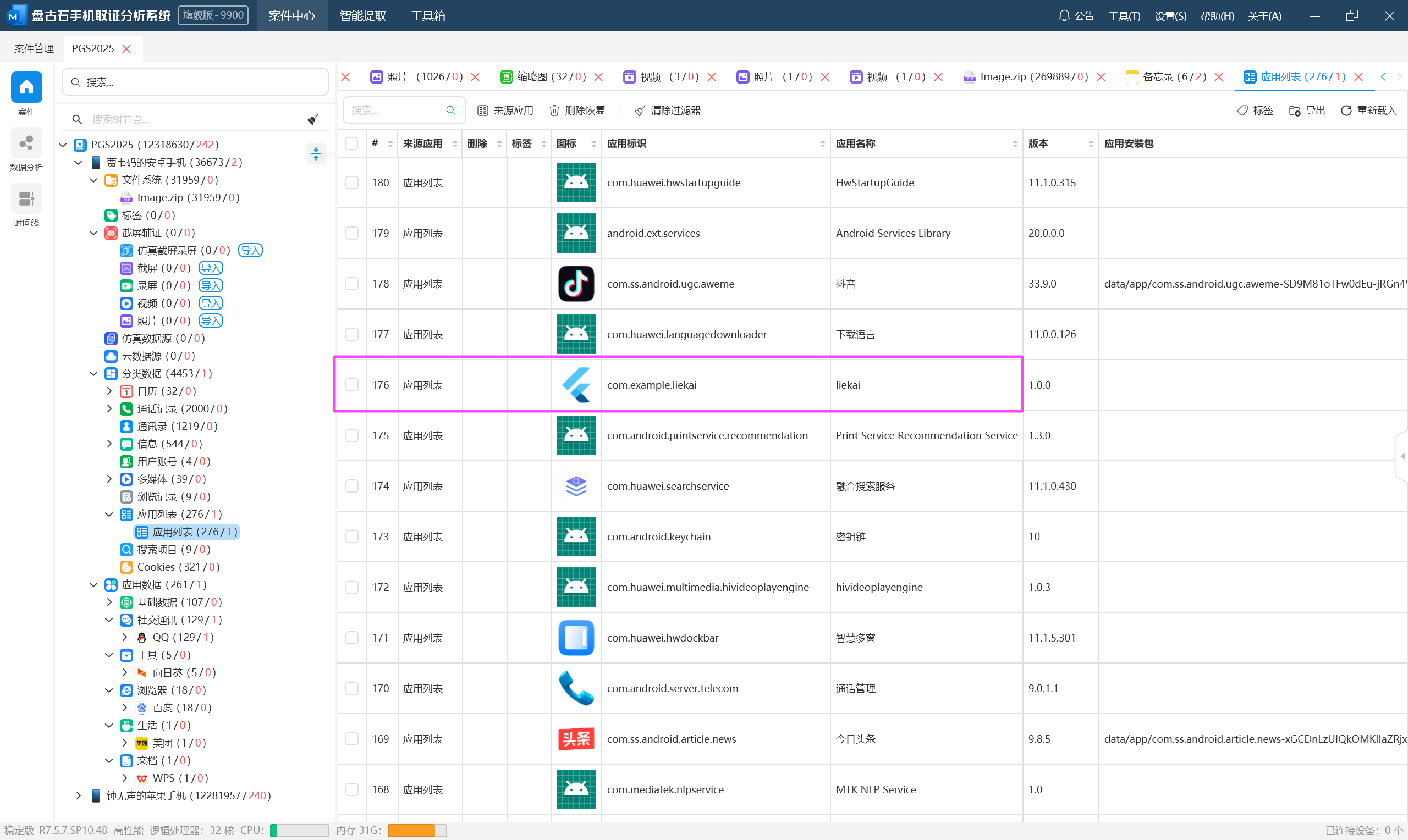
有一个可疑的应用,导出后分析就能发现这个就是监听工具。
com.example.liekai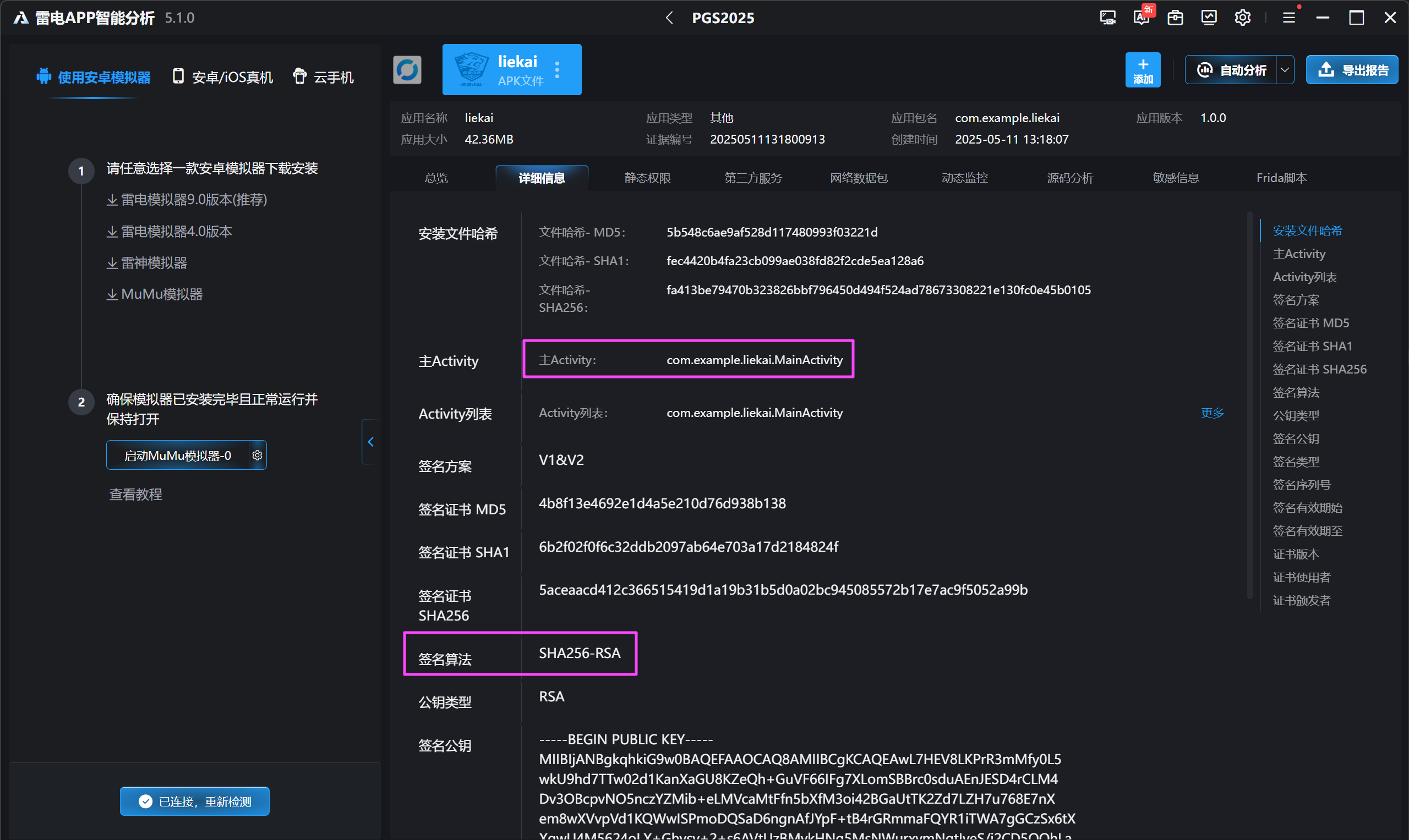
com.example.liekai.MainActivitySHA256RSA1.000[](https://github.com/worawit/blutter)
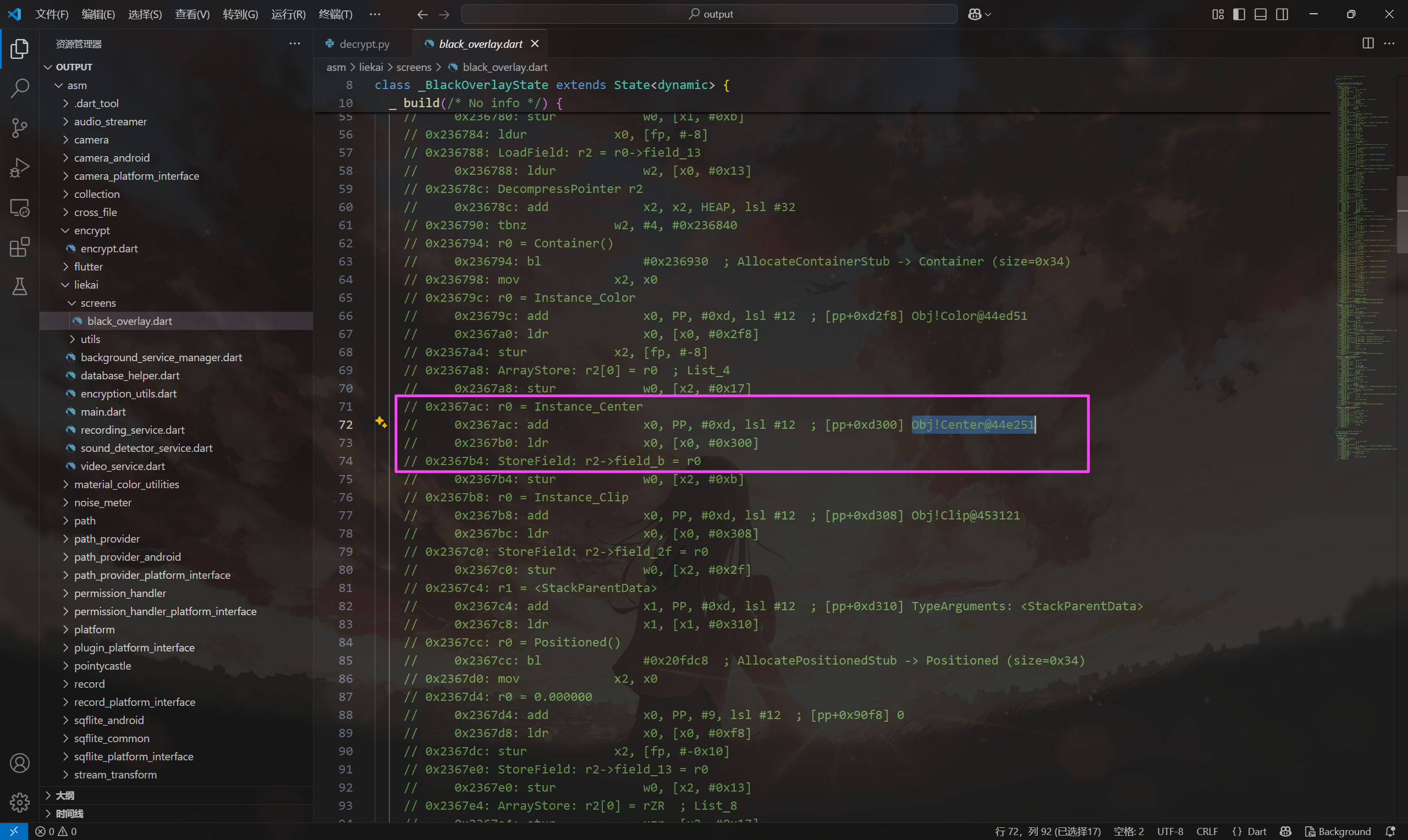
去搜一下对应的这个 Obj,能找到黑色幕布中间的字符串。
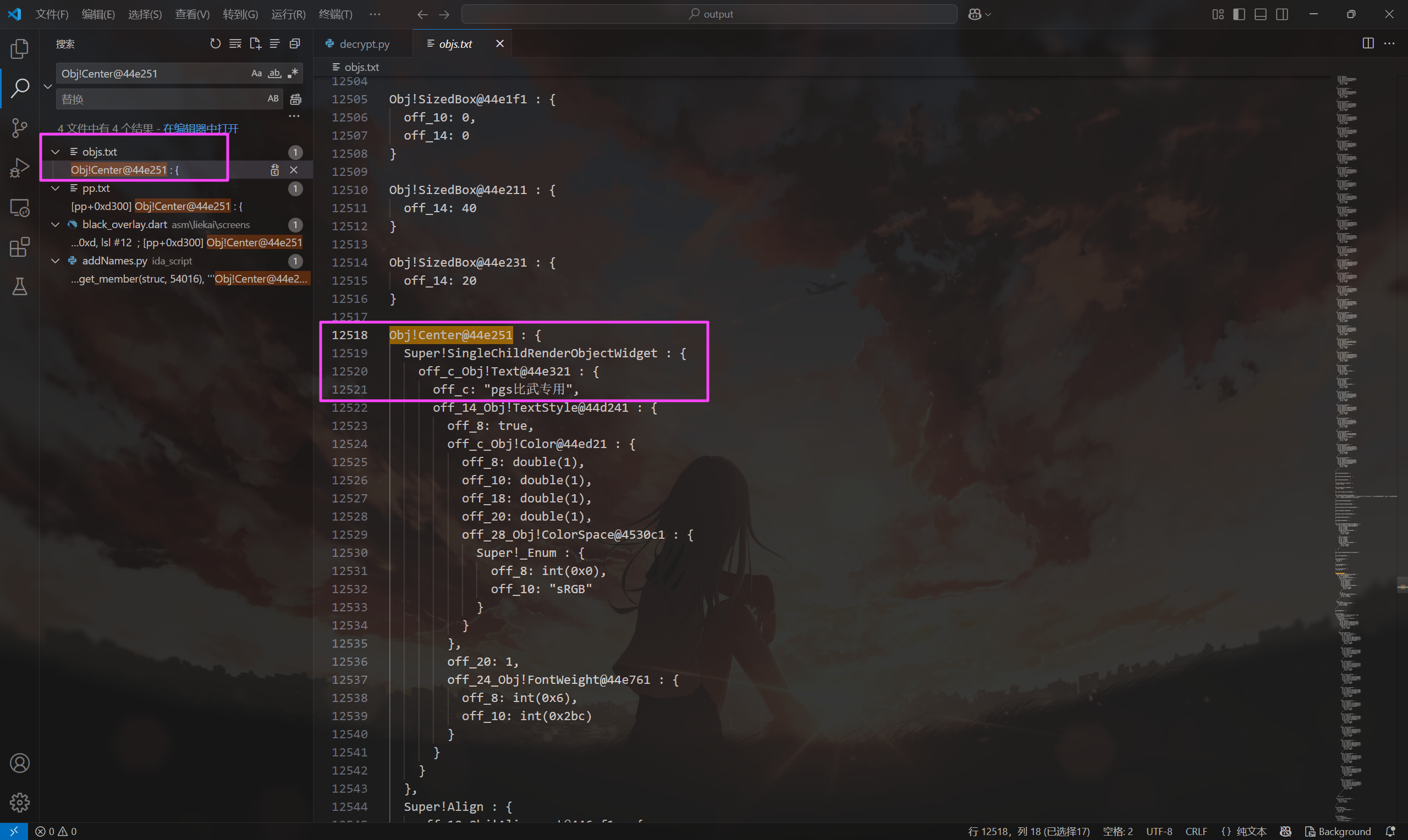
pgs比武专用
704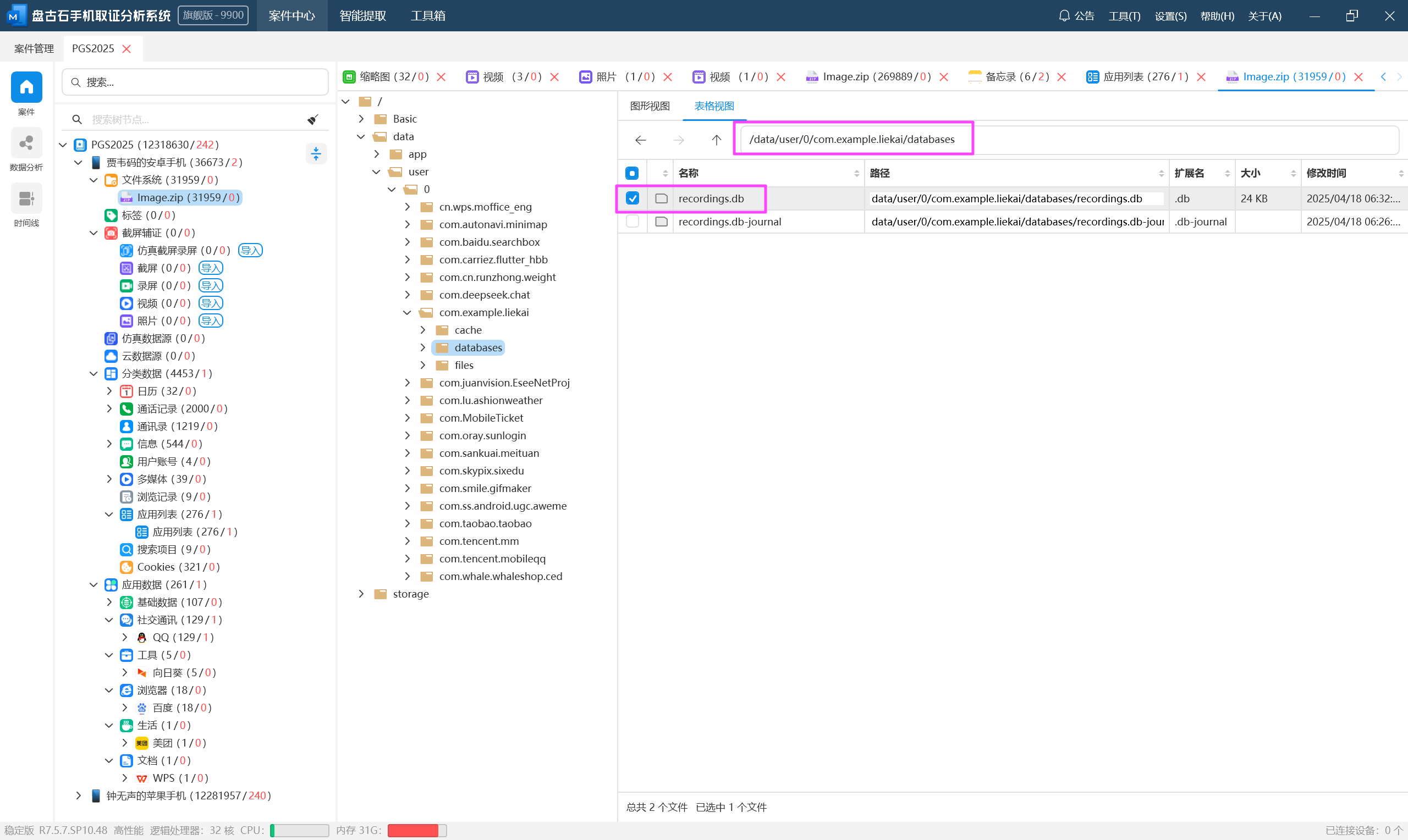
recordings.db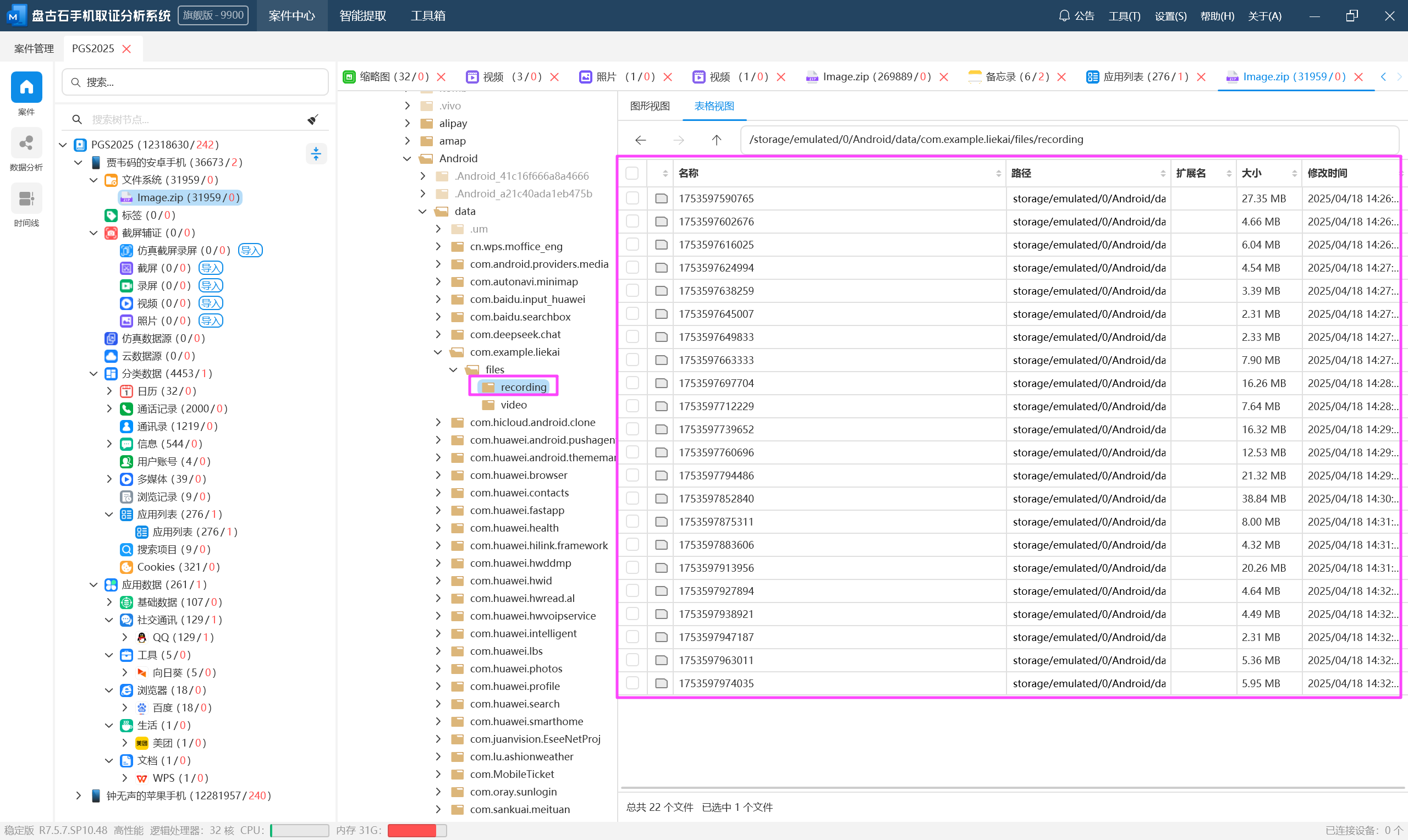
recording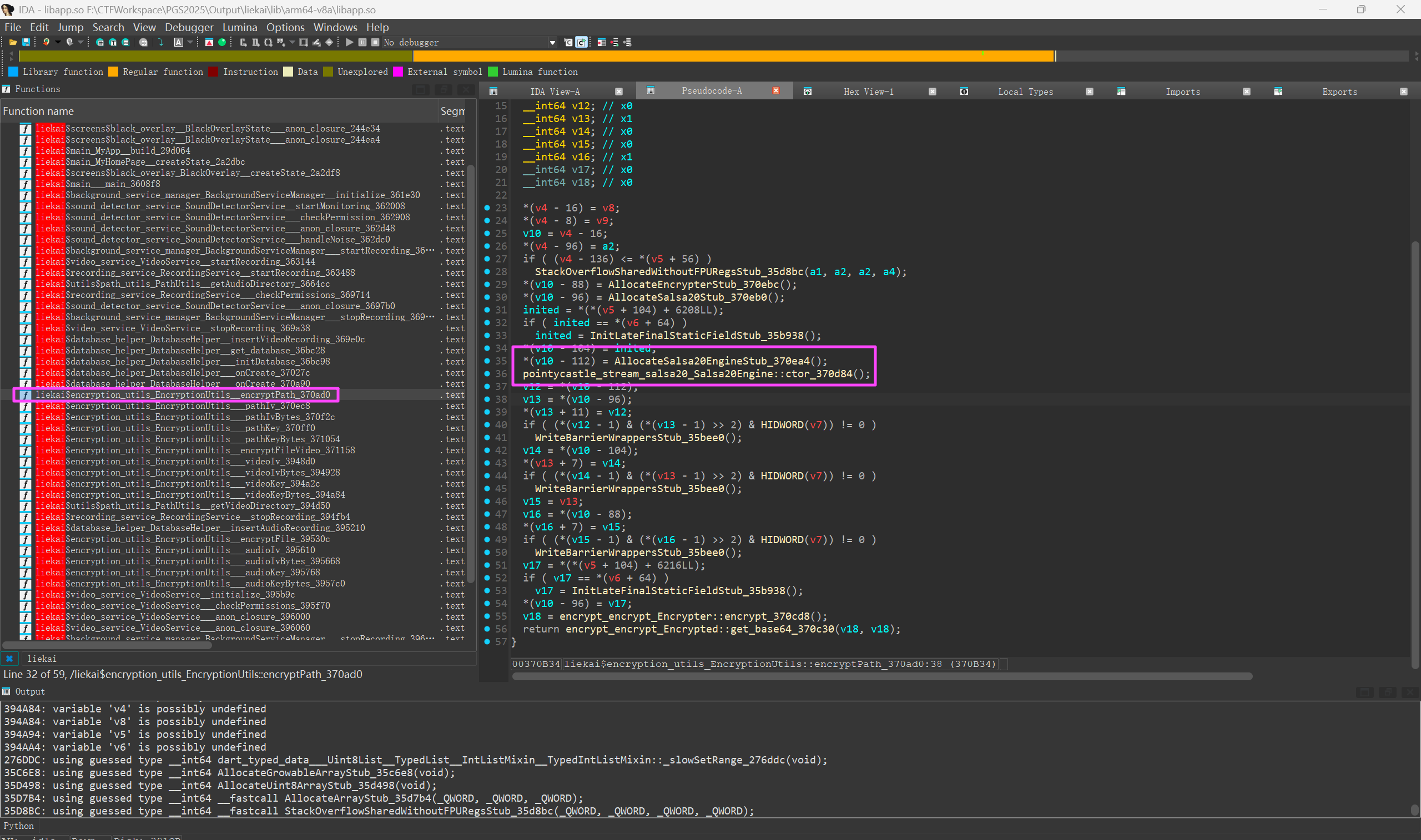
Salsa20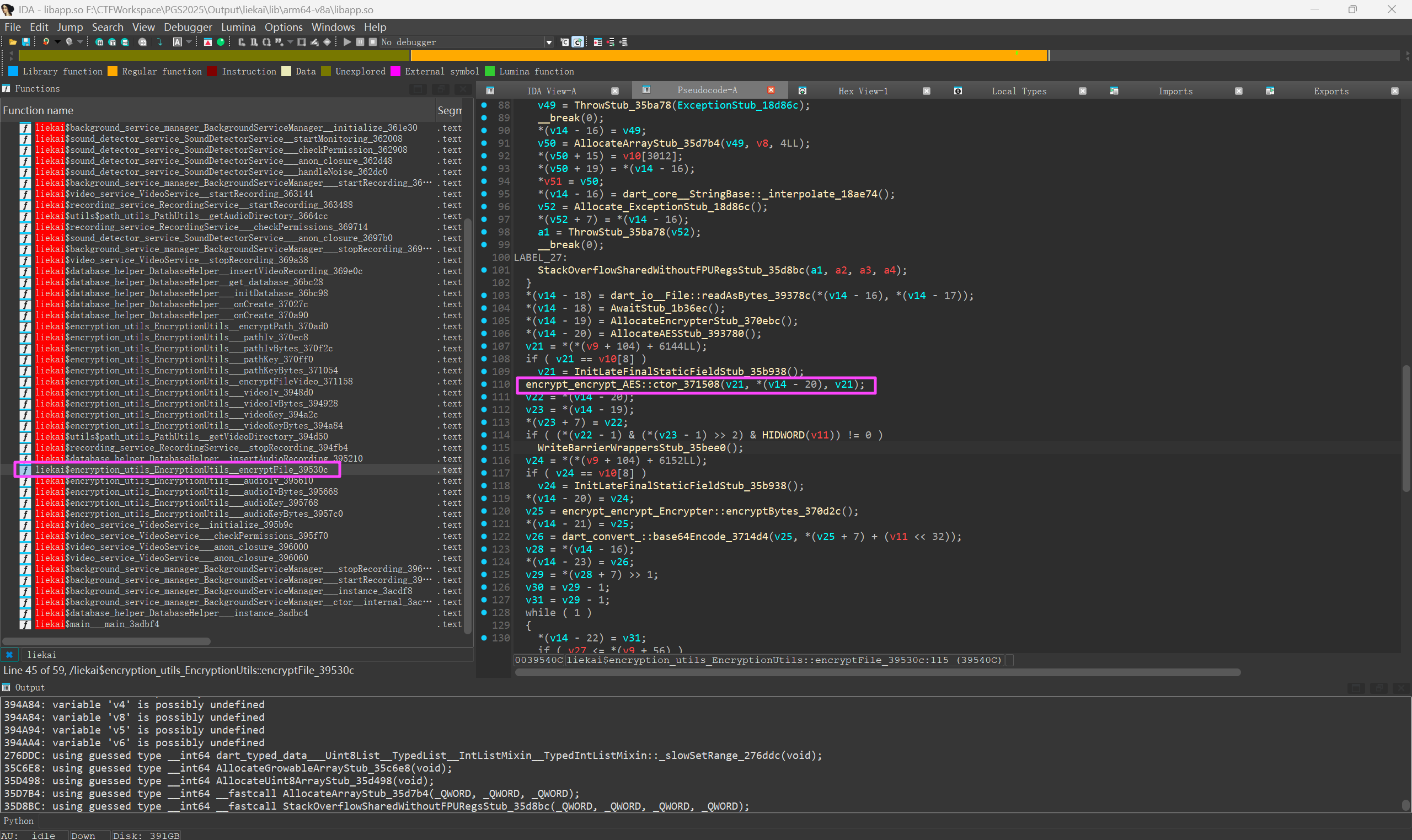
密钥长度是 32,说明这是 AES-256。
AES-256感谢川佬提供的思路
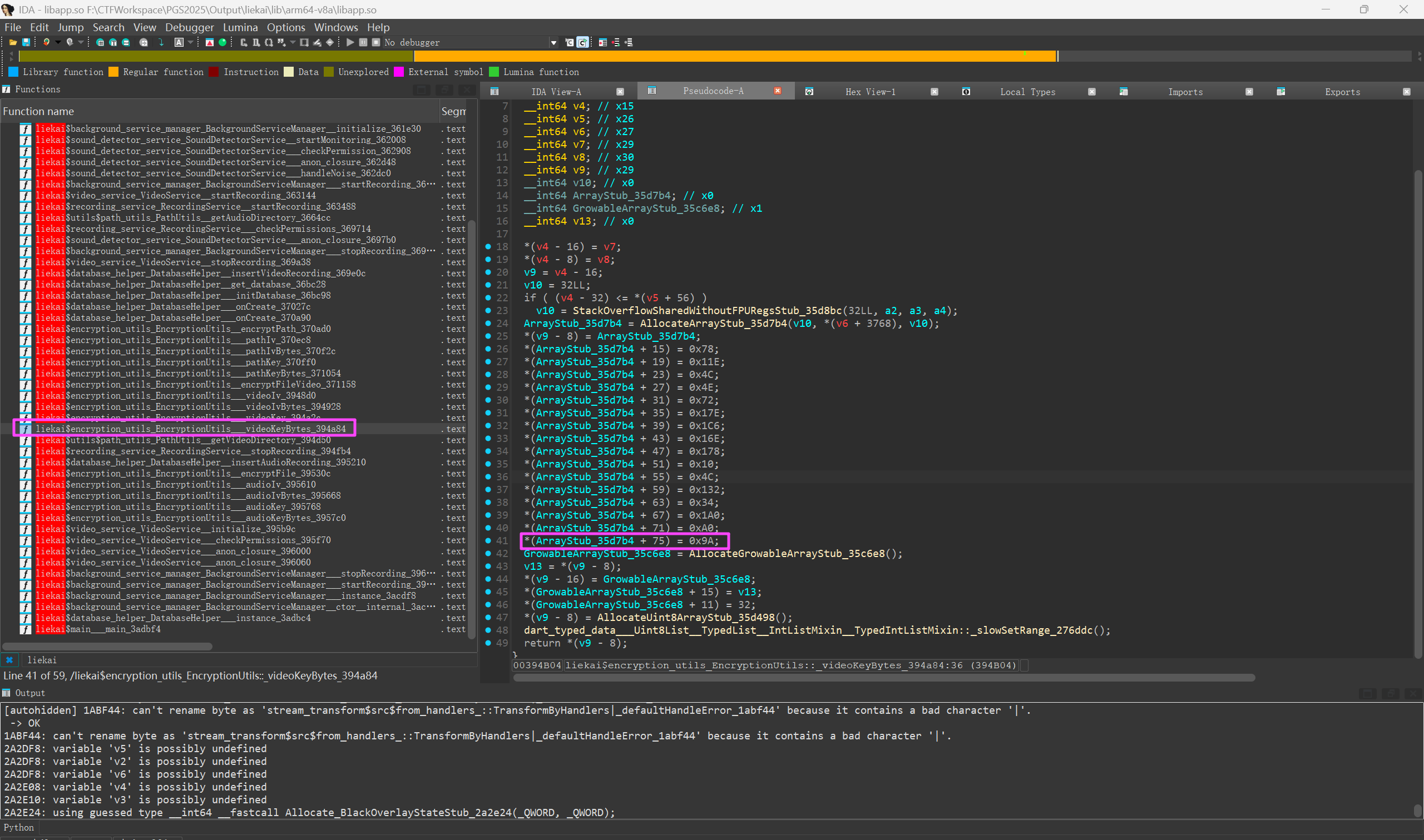
注意这个并不是最终的密钥,每个数需要按位右移一位,也就是除以 2,IV 同理

最终视频的密钥和 IV 分别是 3c8f262739bfe3b7bc0826991ad0504d 和 101112131415161718191a1b1c1d1e1f。
0x4Dkey:2b7e151628aed2a6abf7158809cf4f3c2a7d141527add1a5aaf6148708ce4e3b
IV:000102030405060708090a0b0c0d0e0f

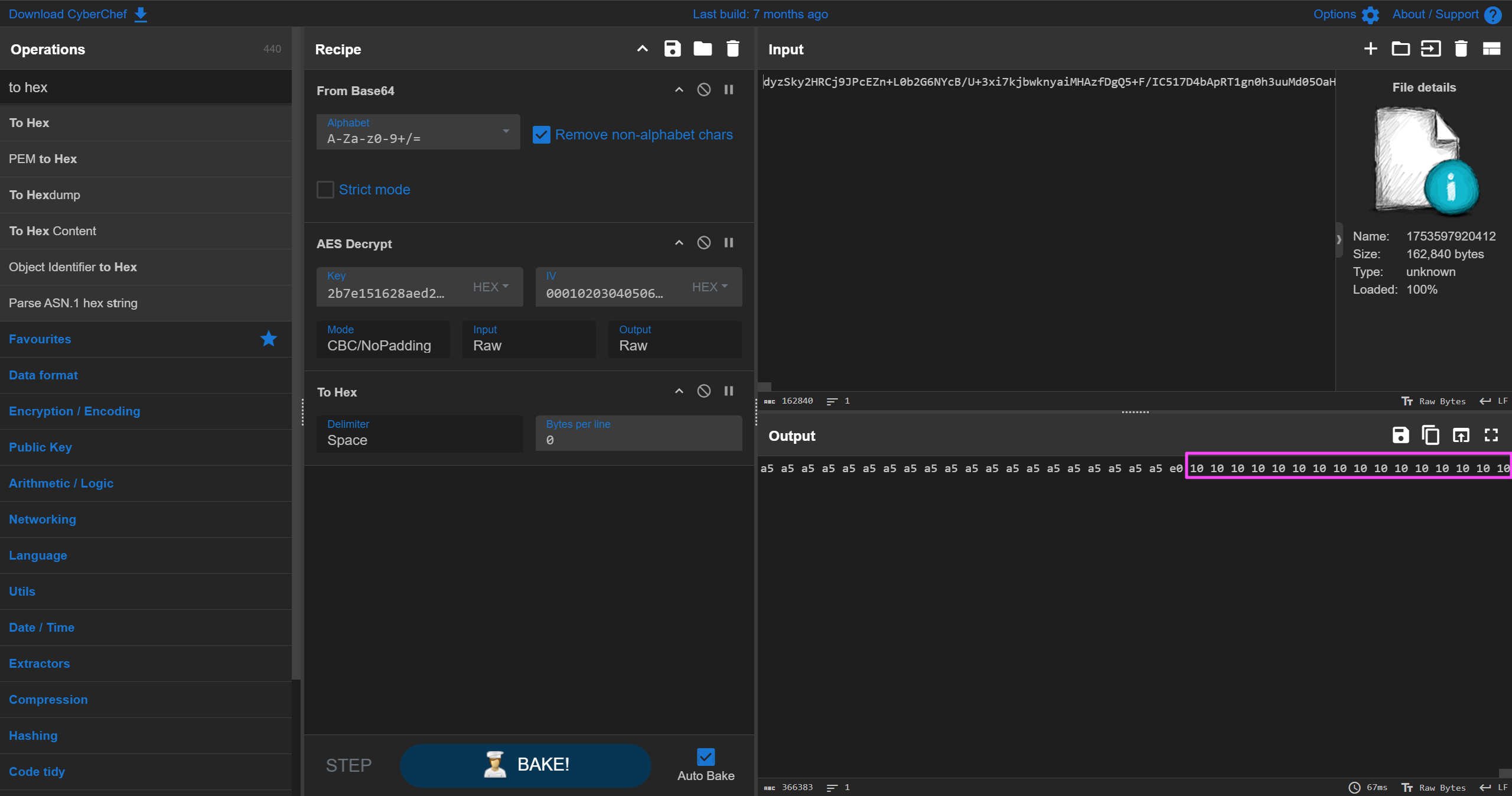
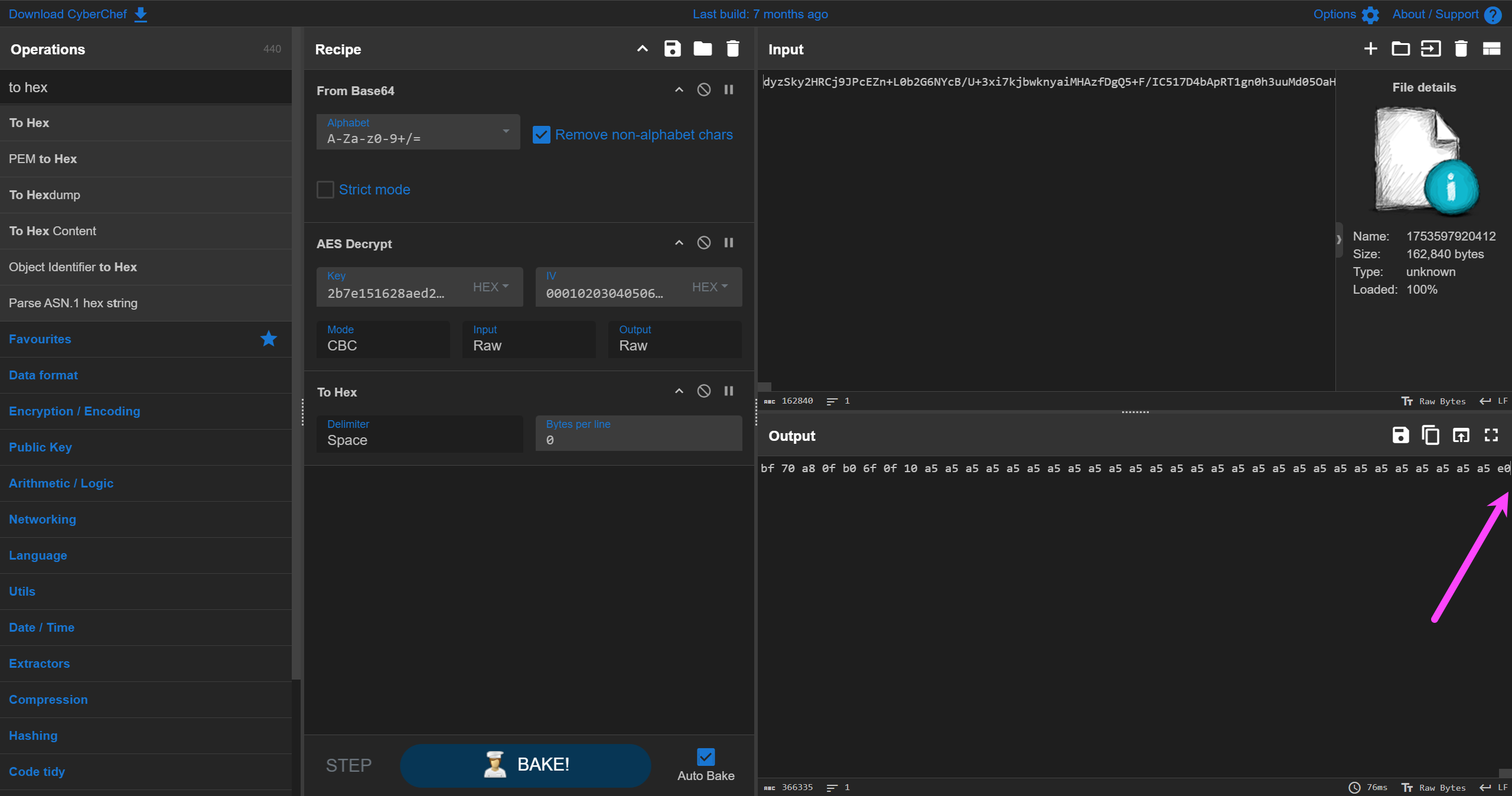
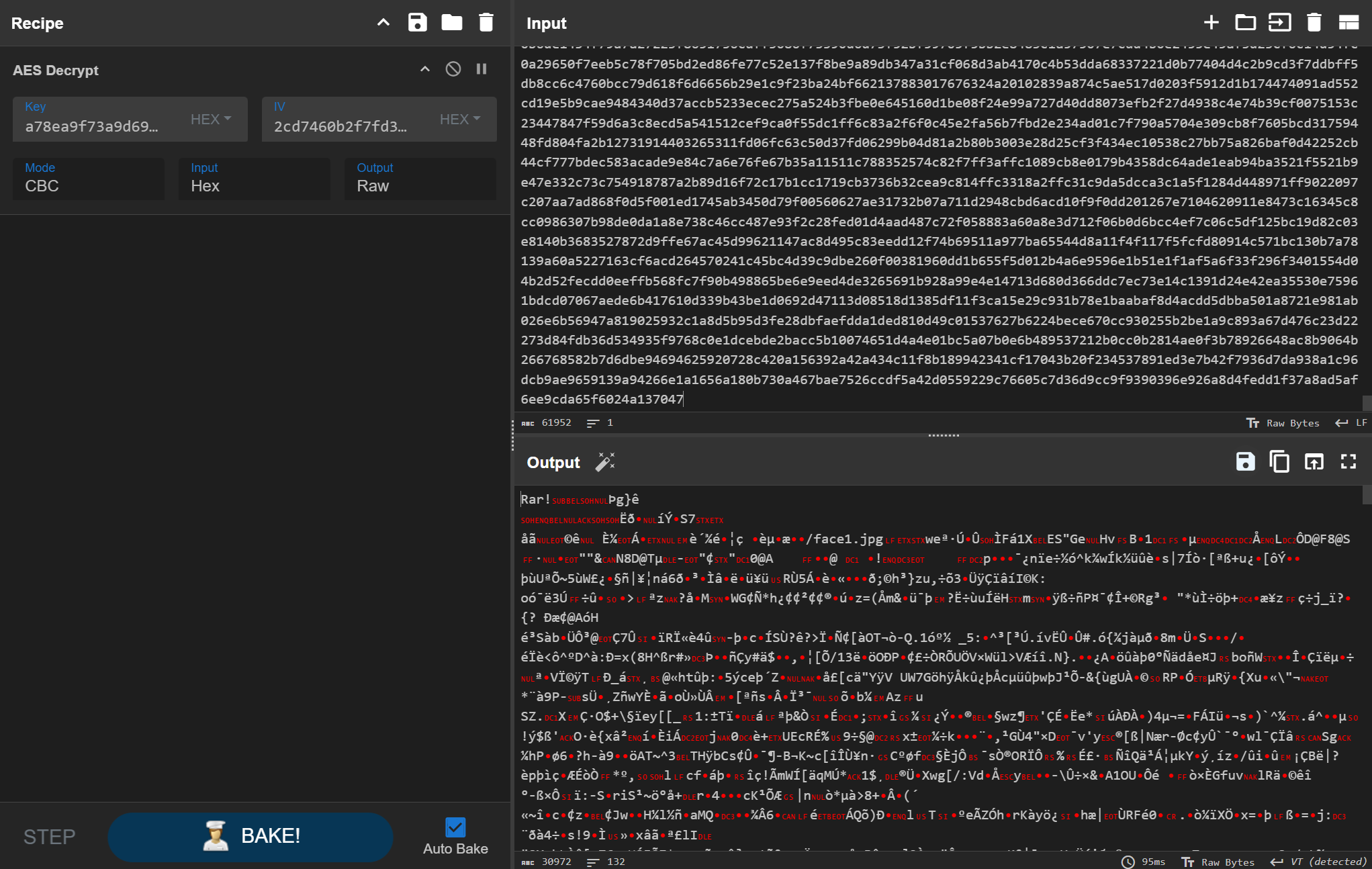
这里应该是出题人的问题,谁解密这玩意选 NoPadding 啊。
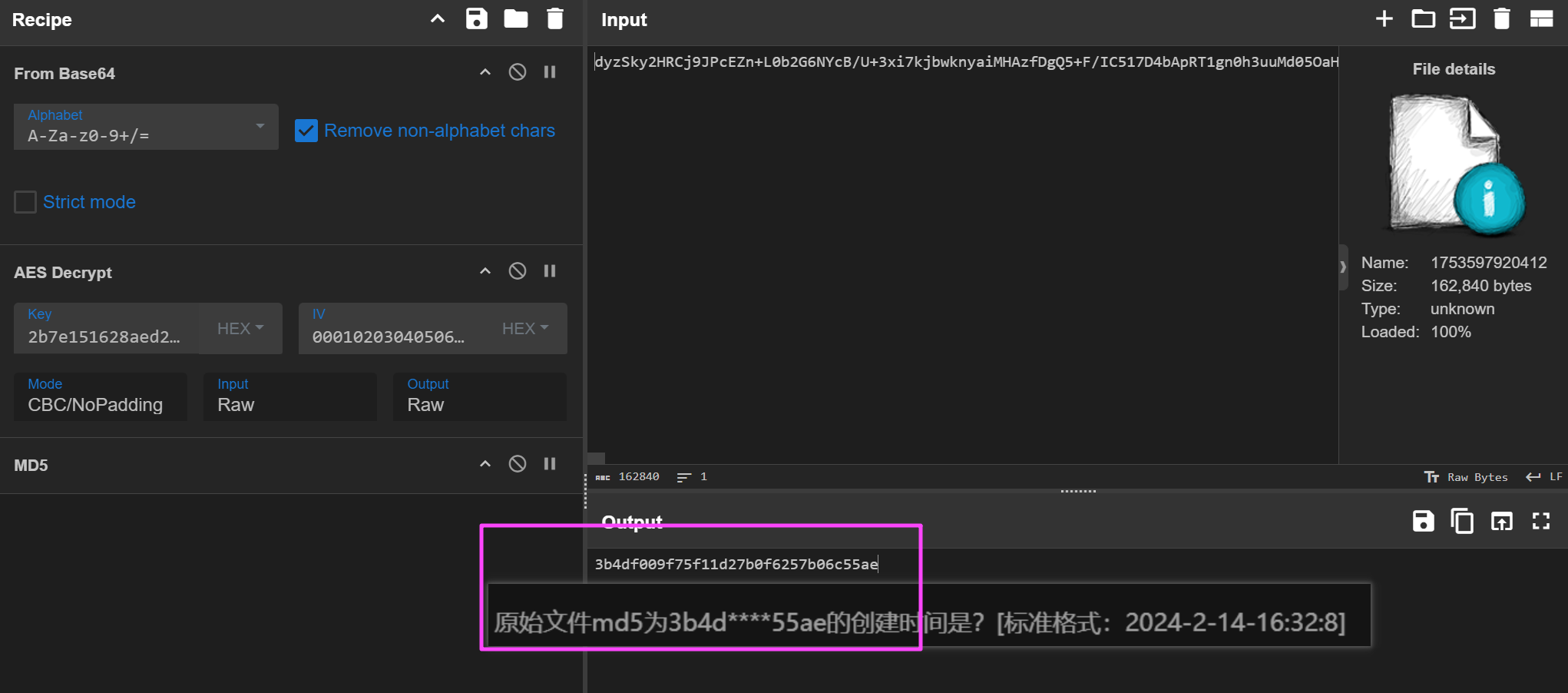
有点抽象。
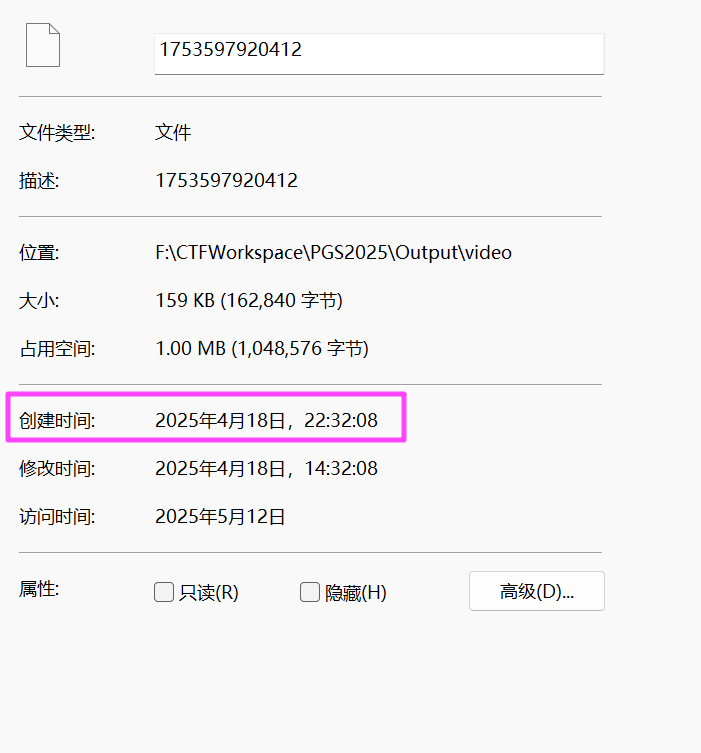
2025-4-18-22:32:8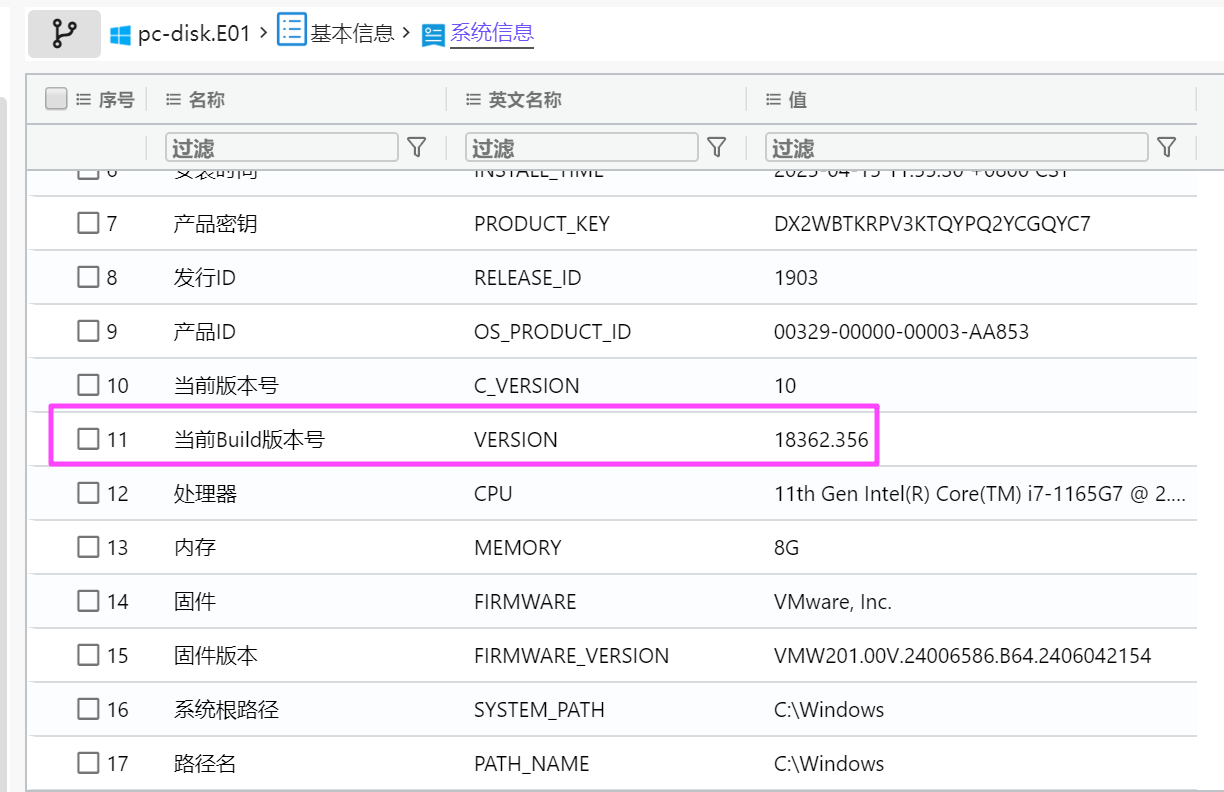
18362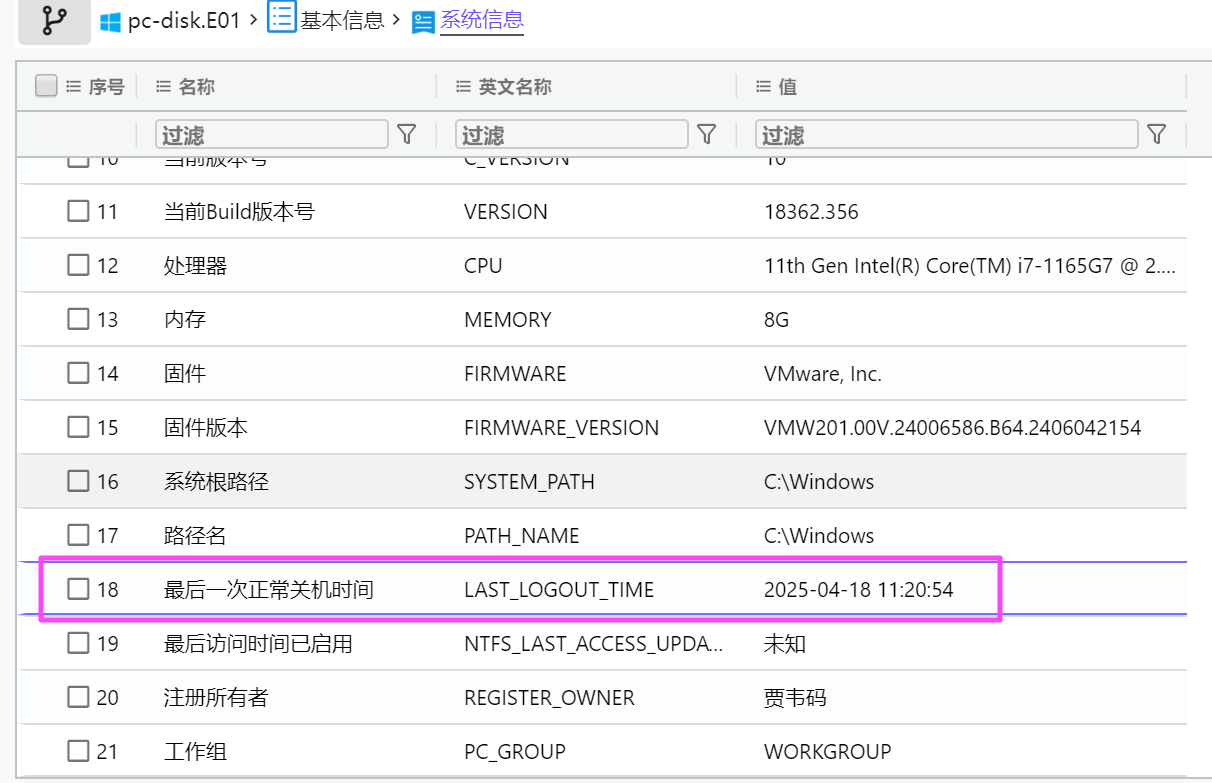
注意检材的时区是 UTC+8,答案要求 UTC+0,需要减去 8 小时。
2025-04-18 03:20:54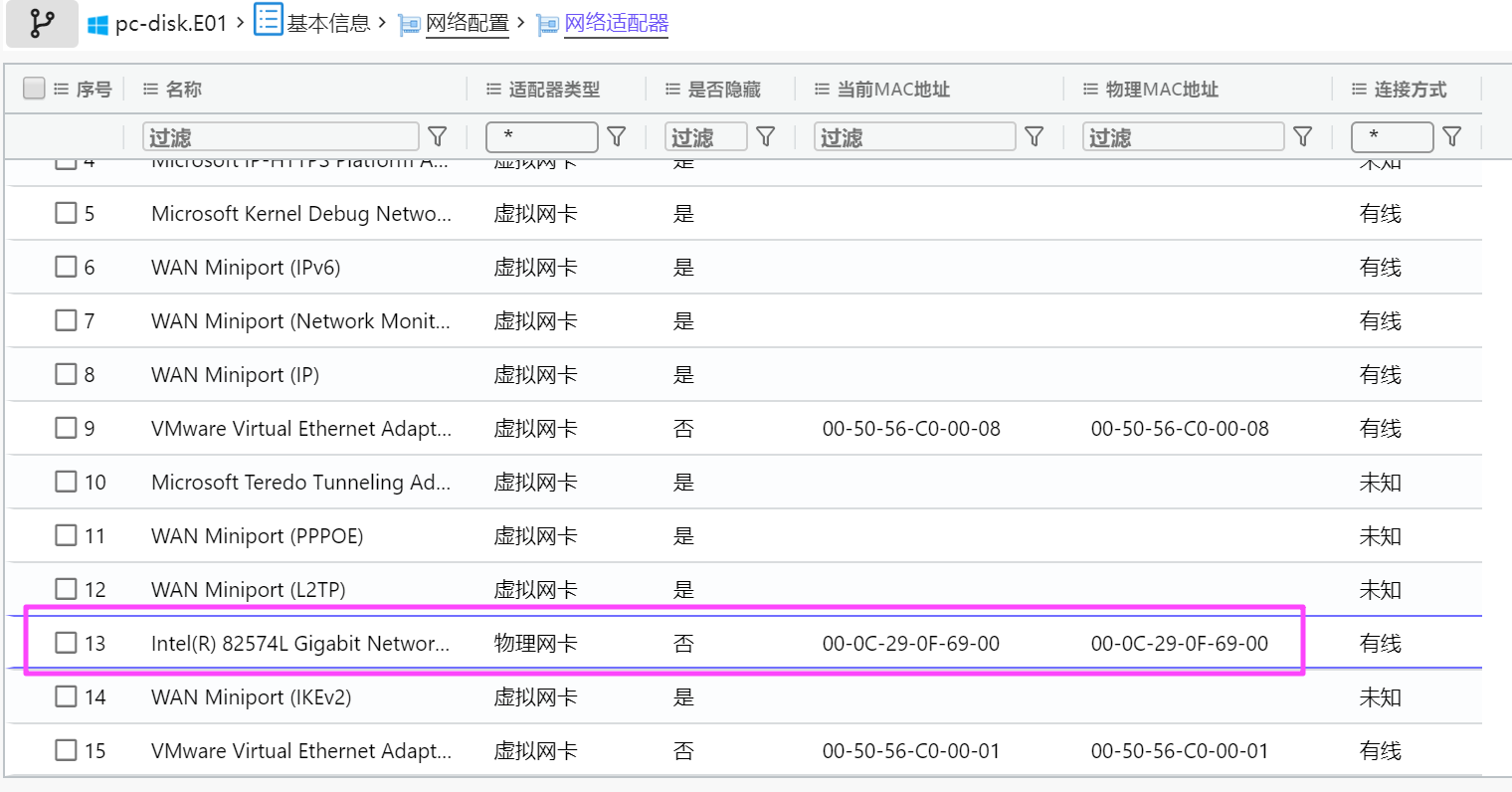
00-0C-29-0F-69-00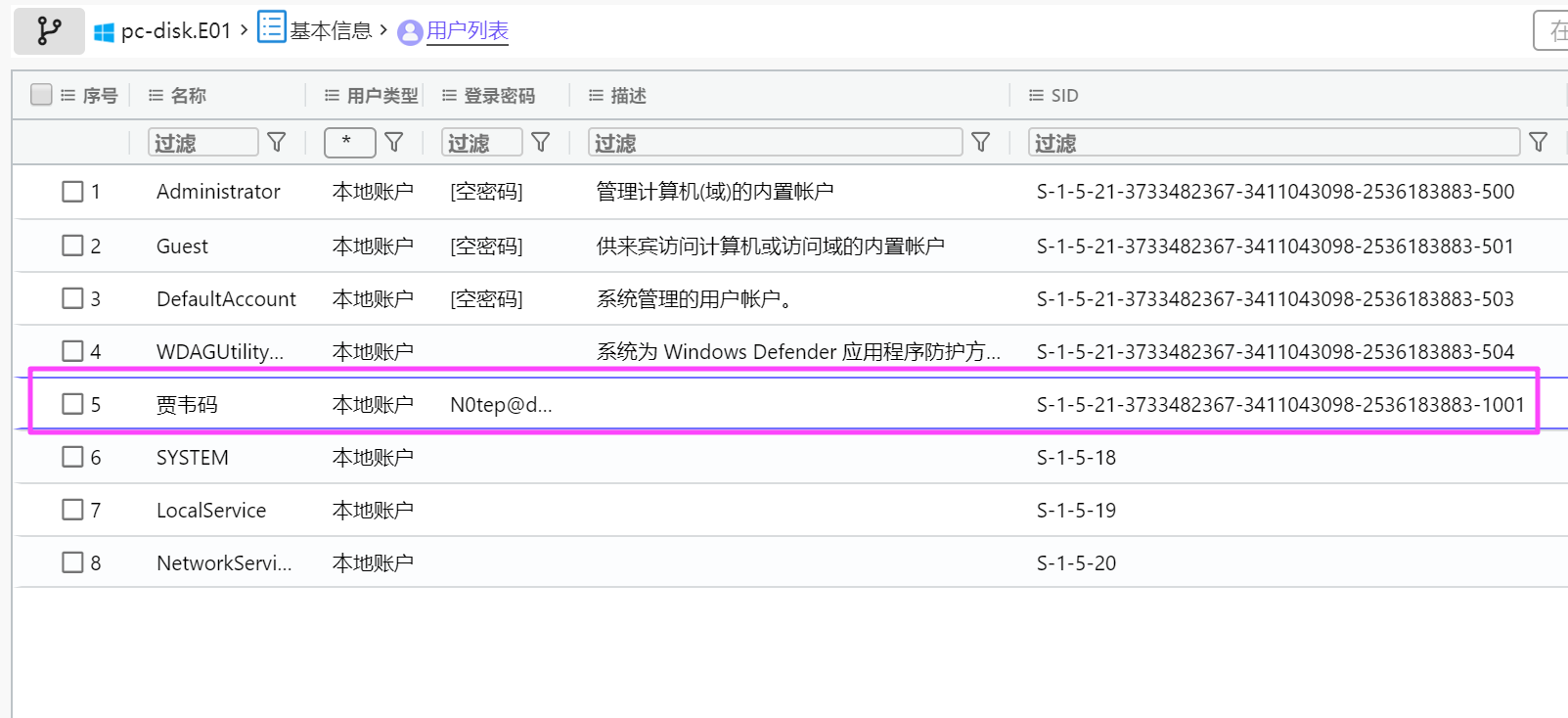
S-1-5-21-3733482367-3411043098-2536183883-1001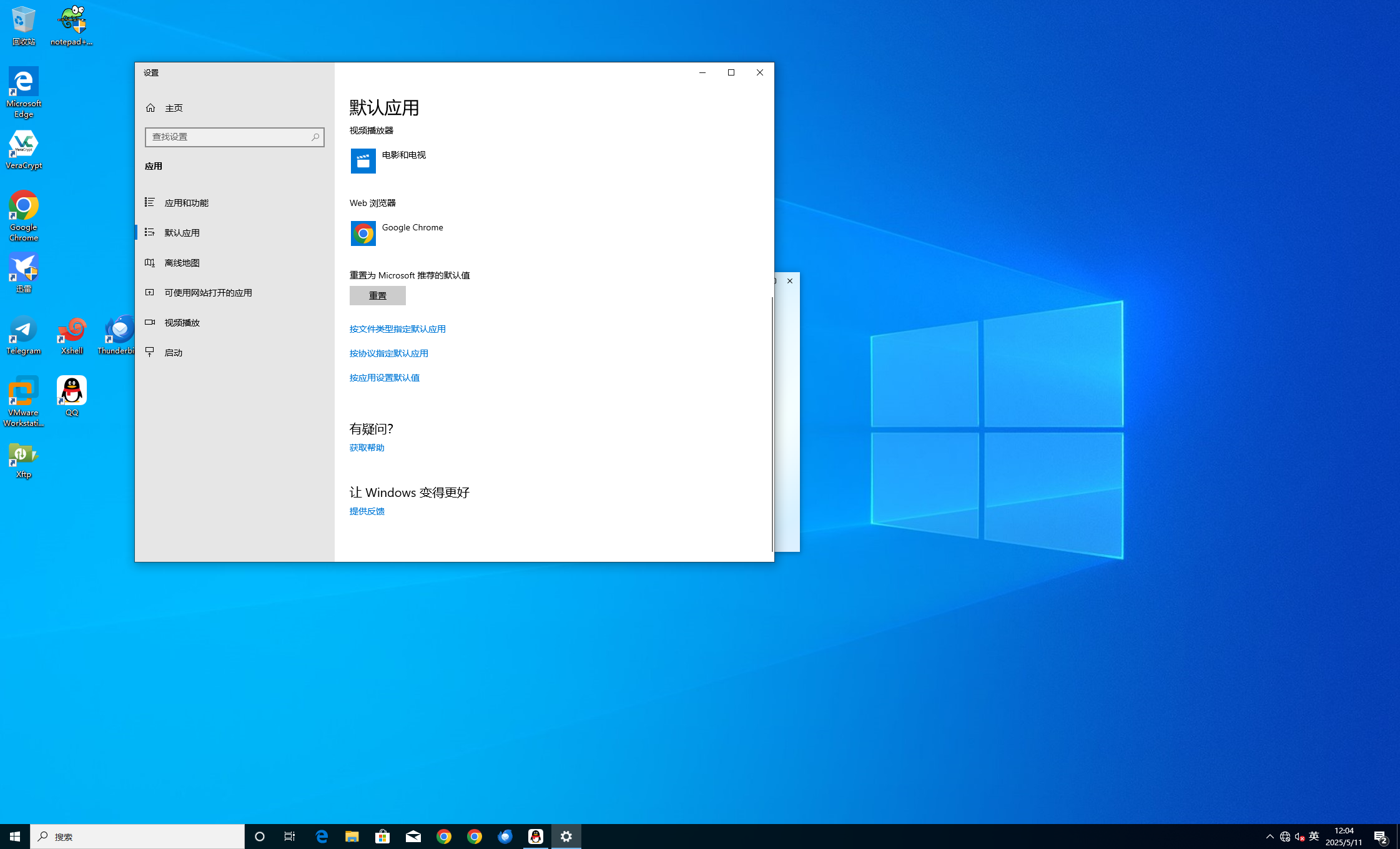
Google Chrome
135.0.7049.96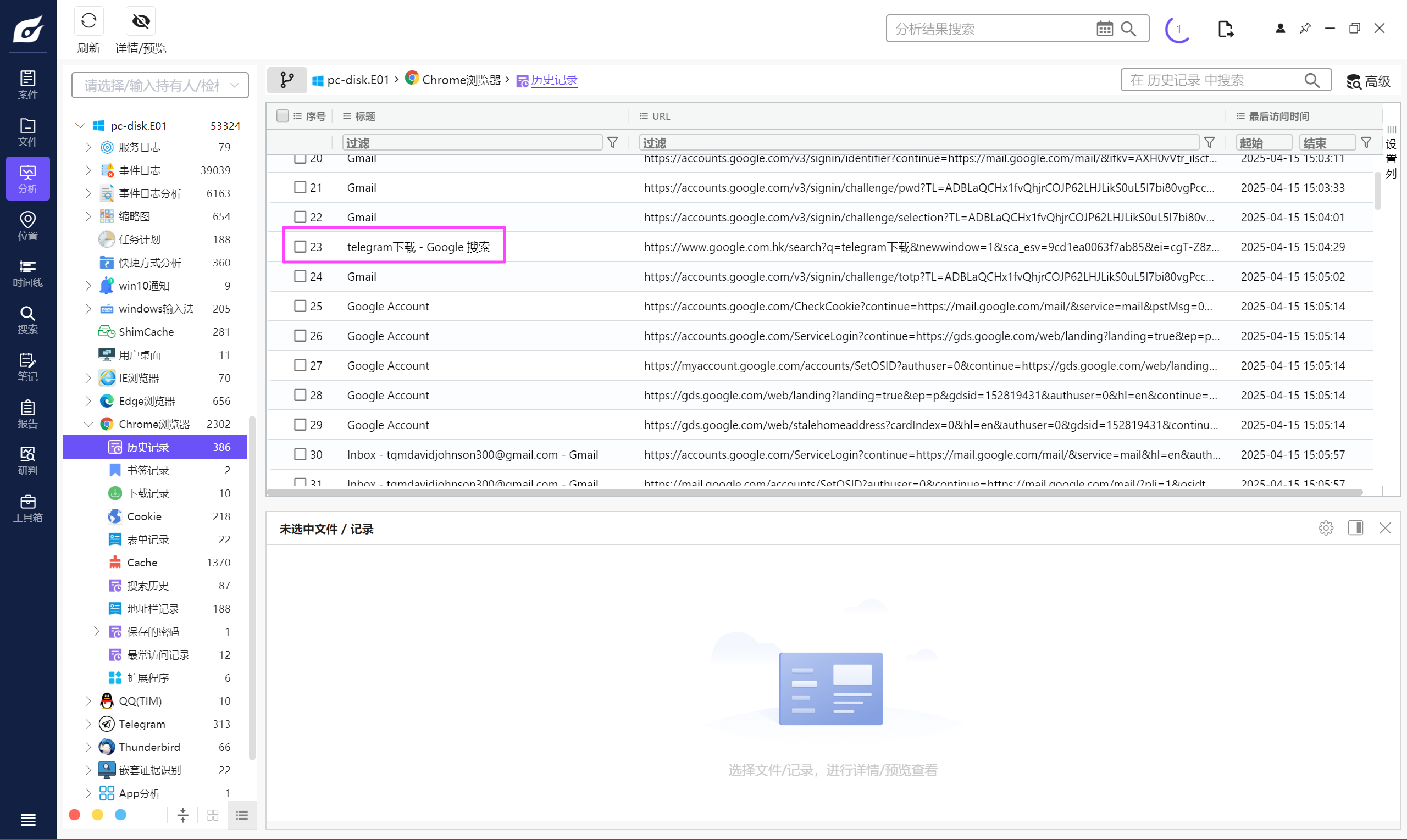
Telegram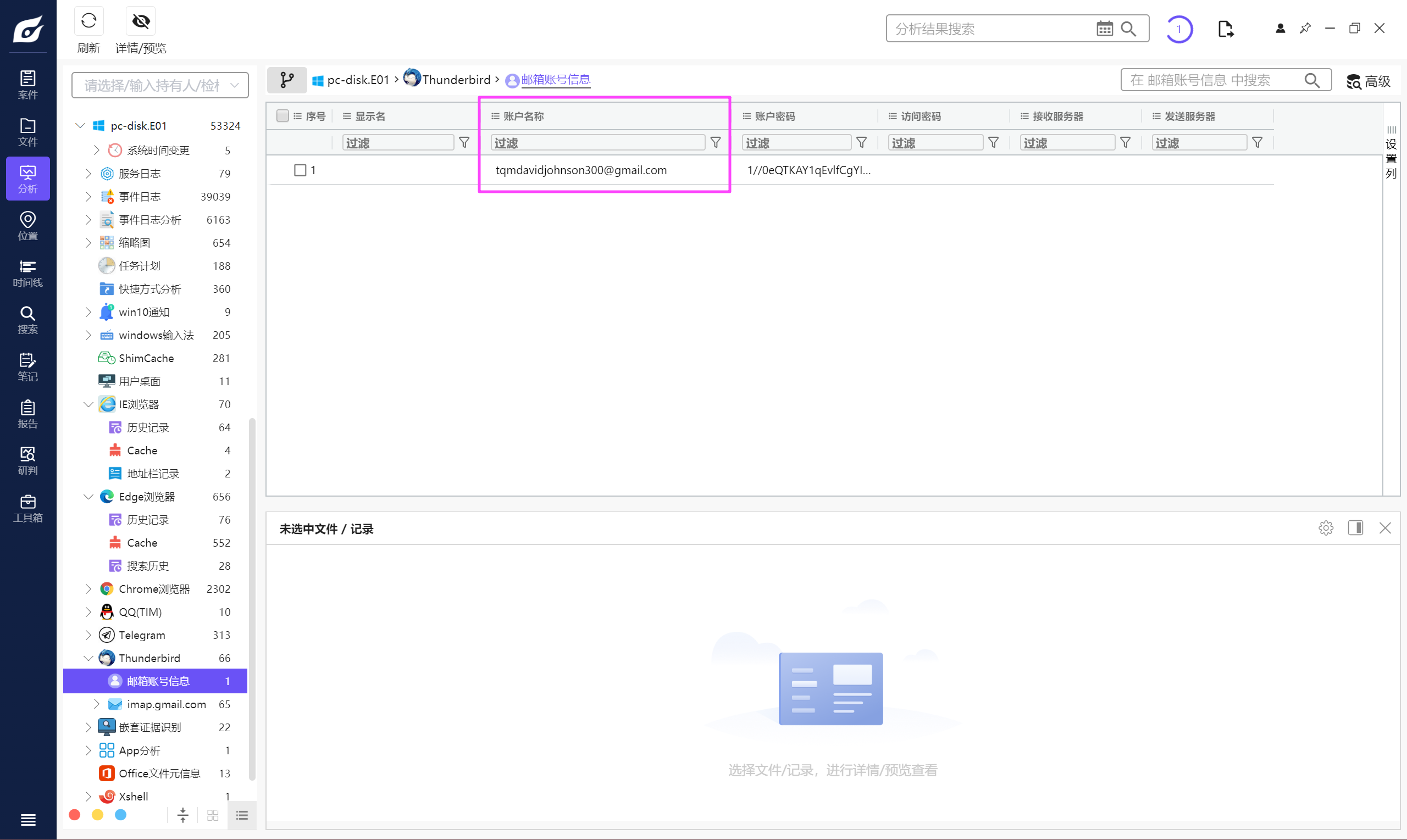
tqmdavidjohnson300@gmail.com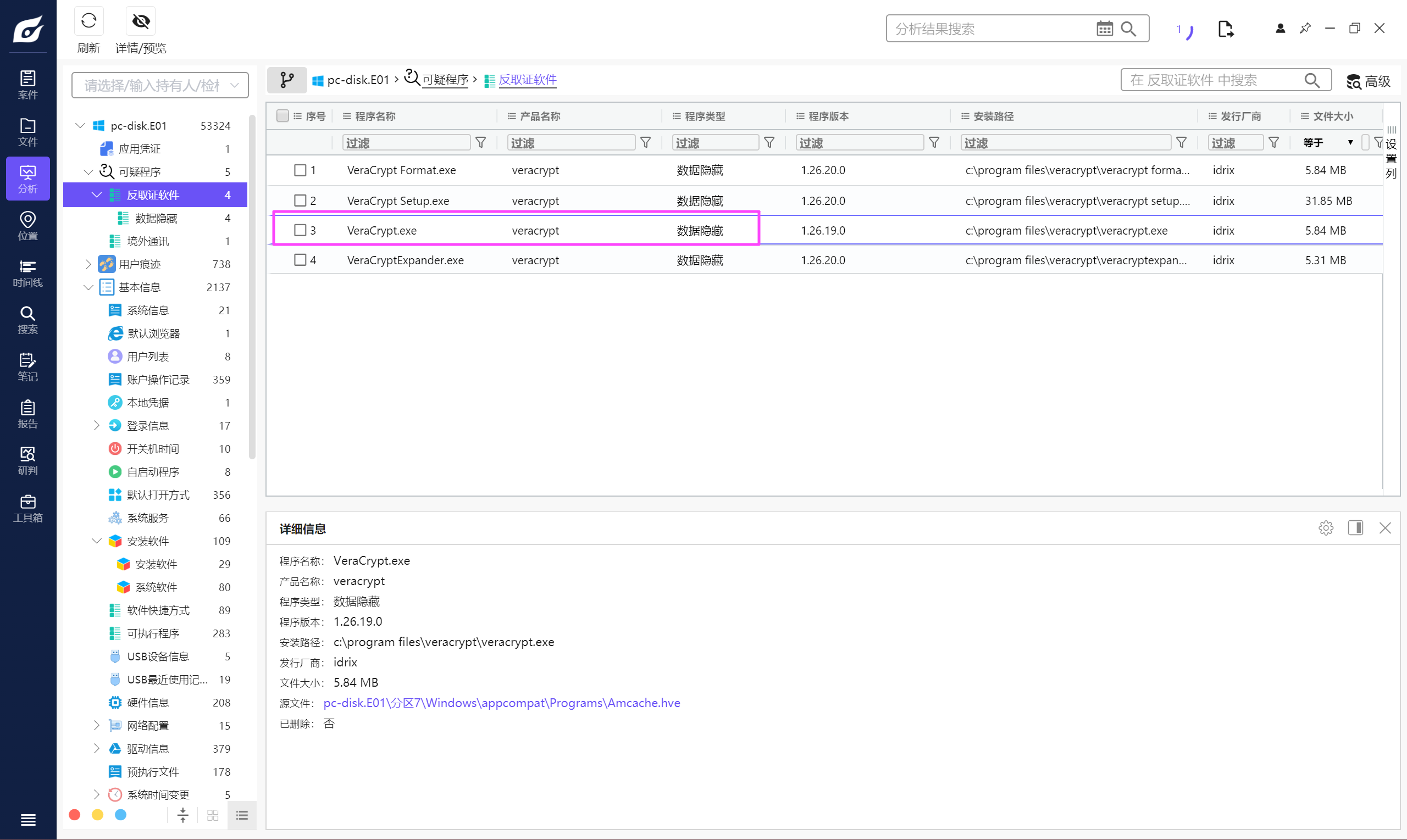
VeraCrypt.exe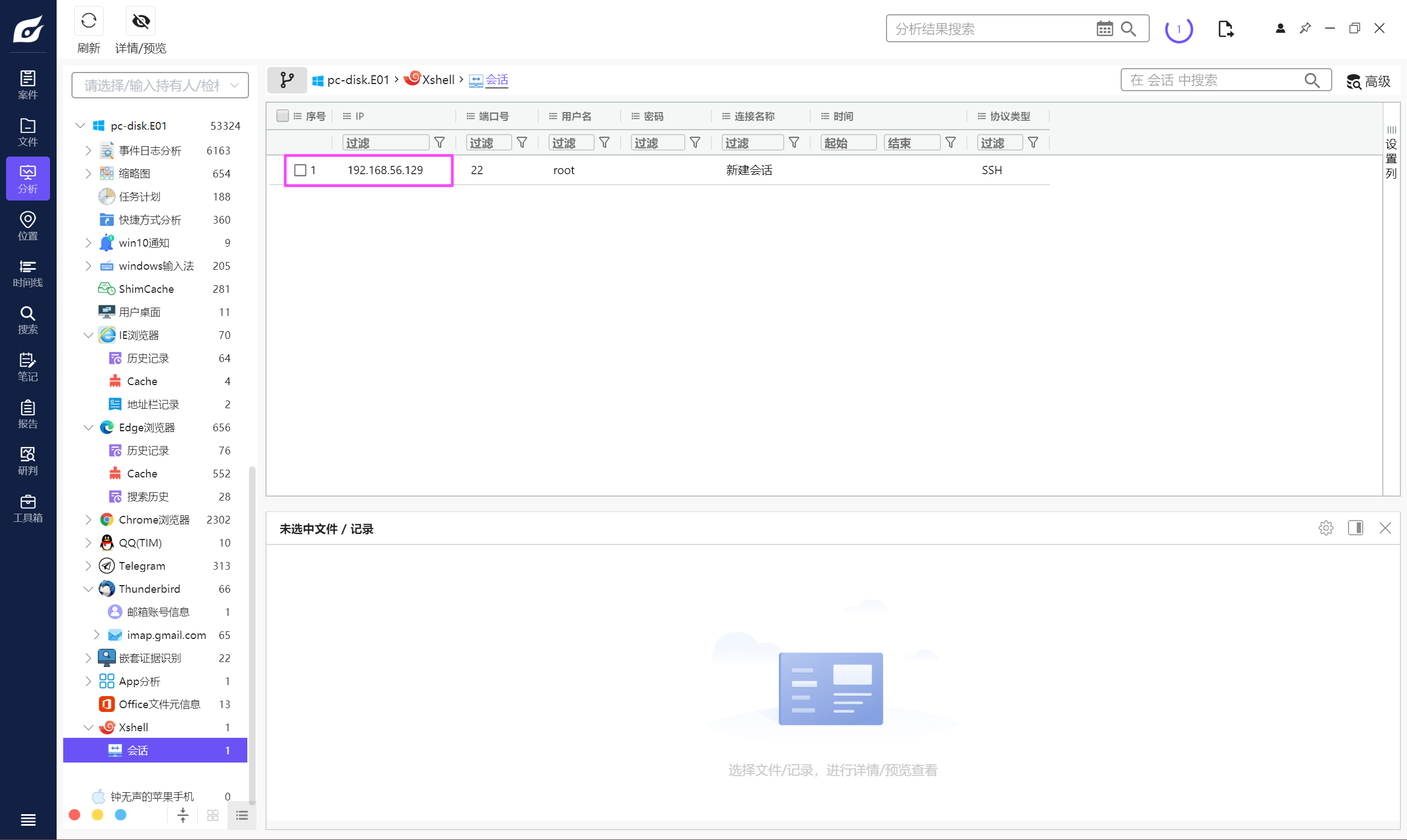
192.168.56.129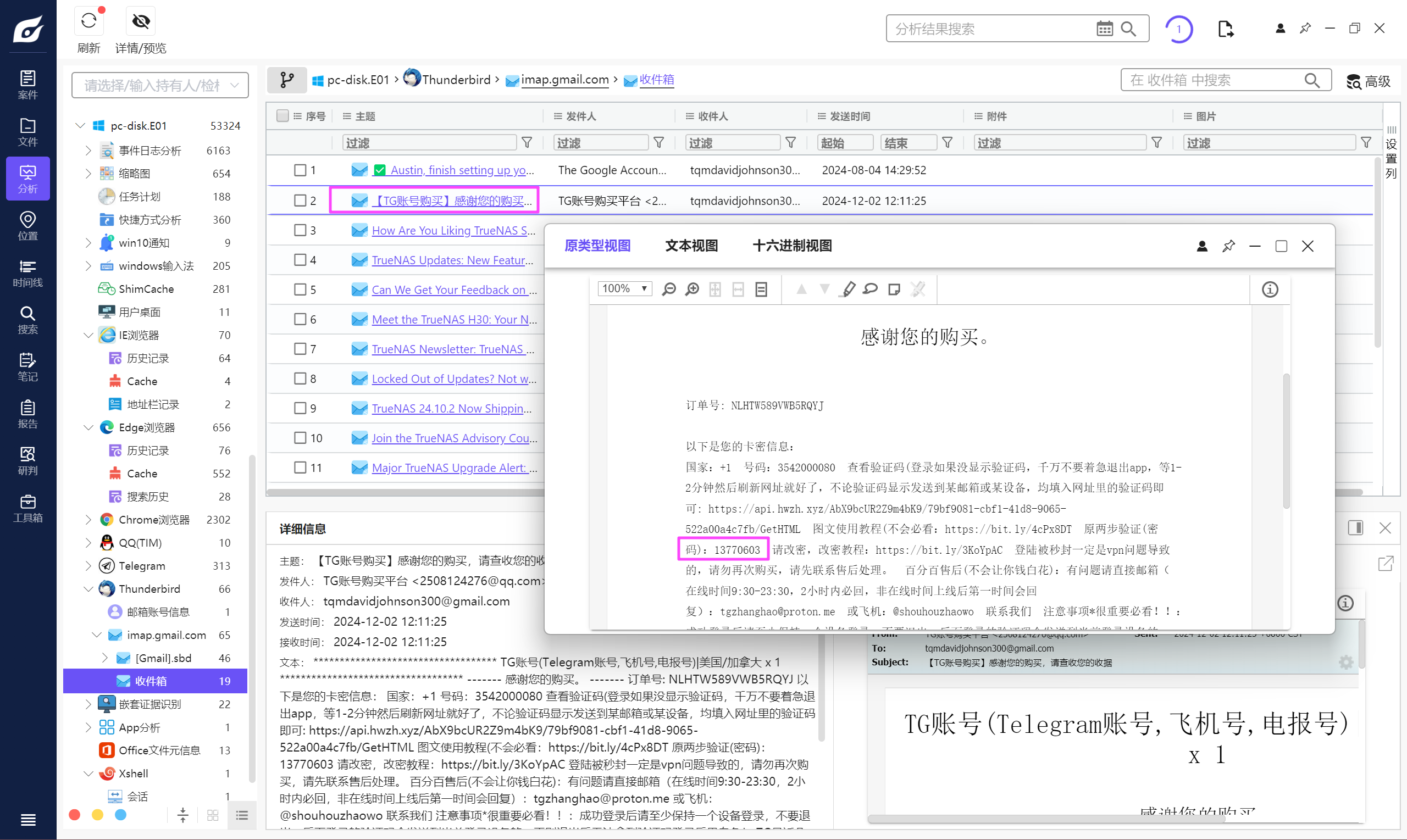
13770603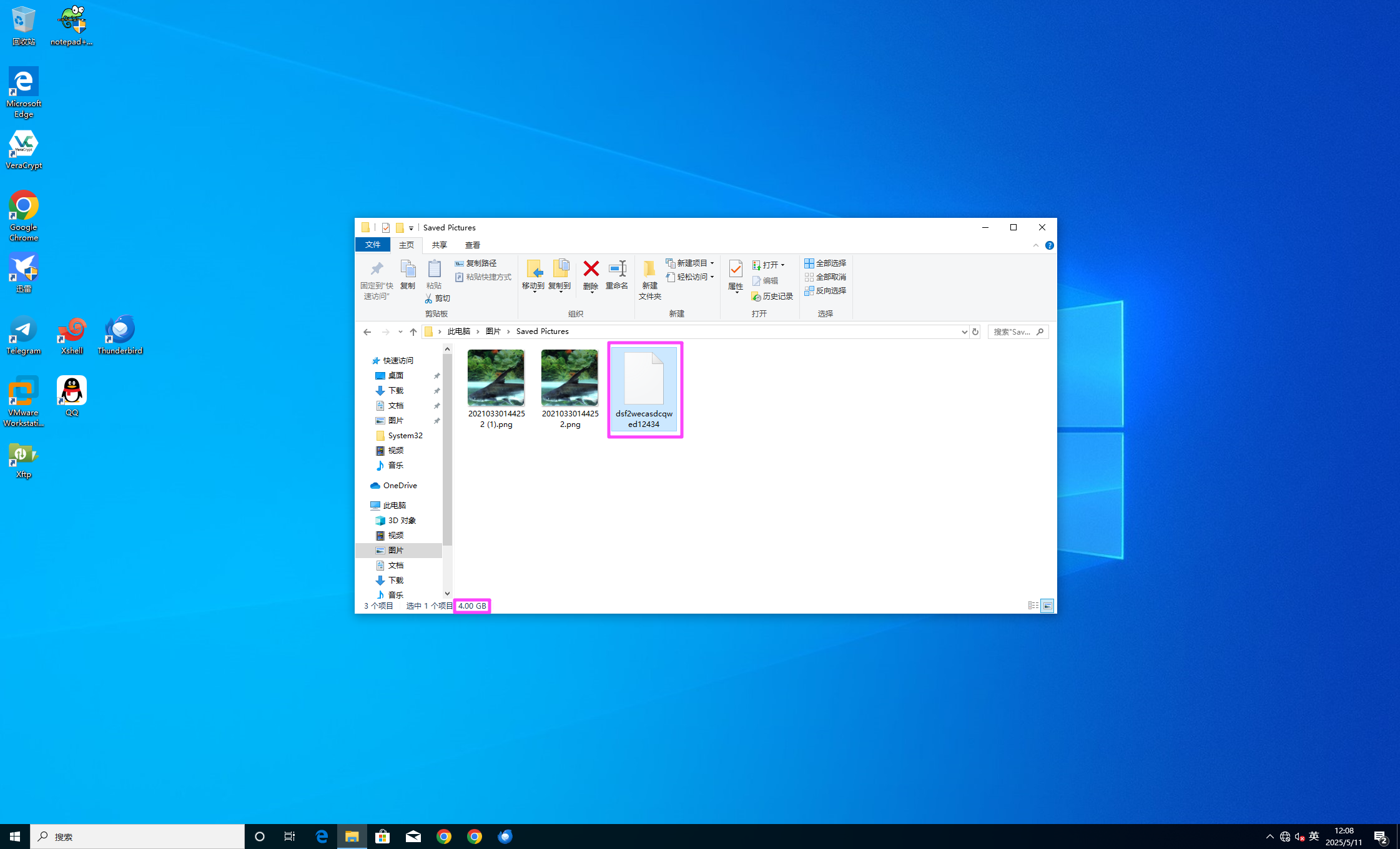
保存的图片里面有一个加密容器,但是不知道密码。
其实,密码在 VR 案情里面,卧室里面有一个暗门,可以直接拿到密码。


直接用 Passware 去爆密码即可。
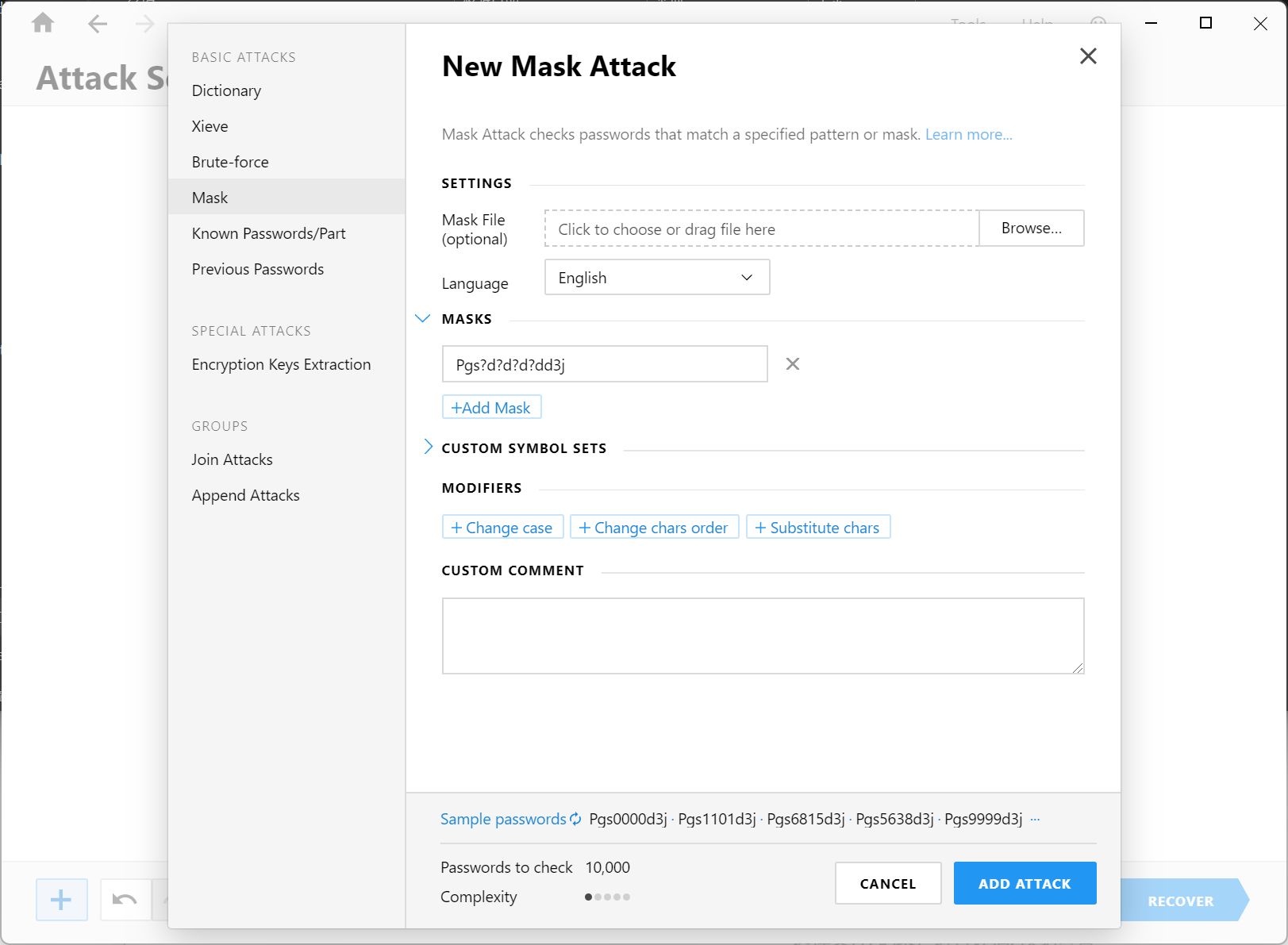
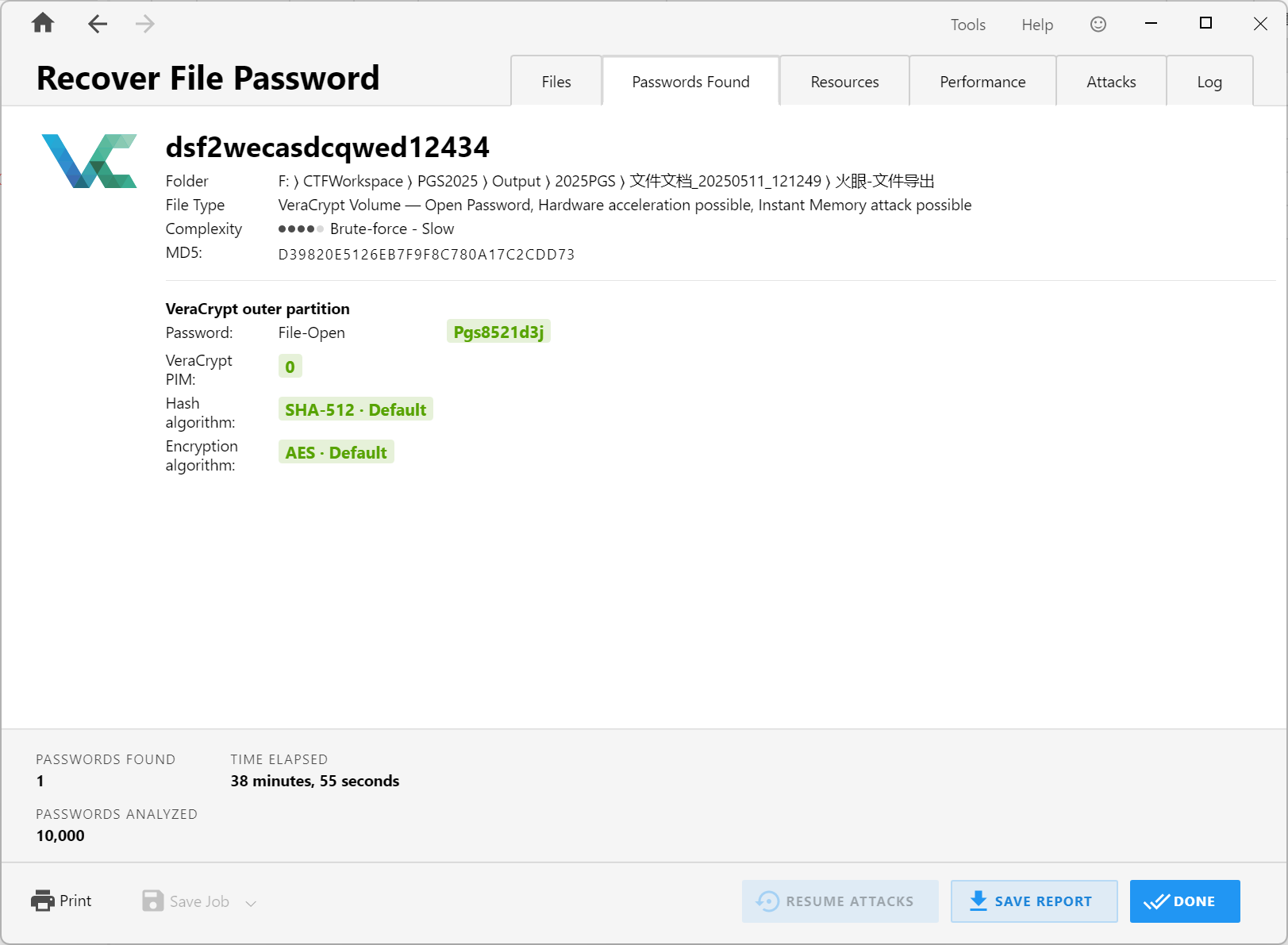
Pgs8521d3j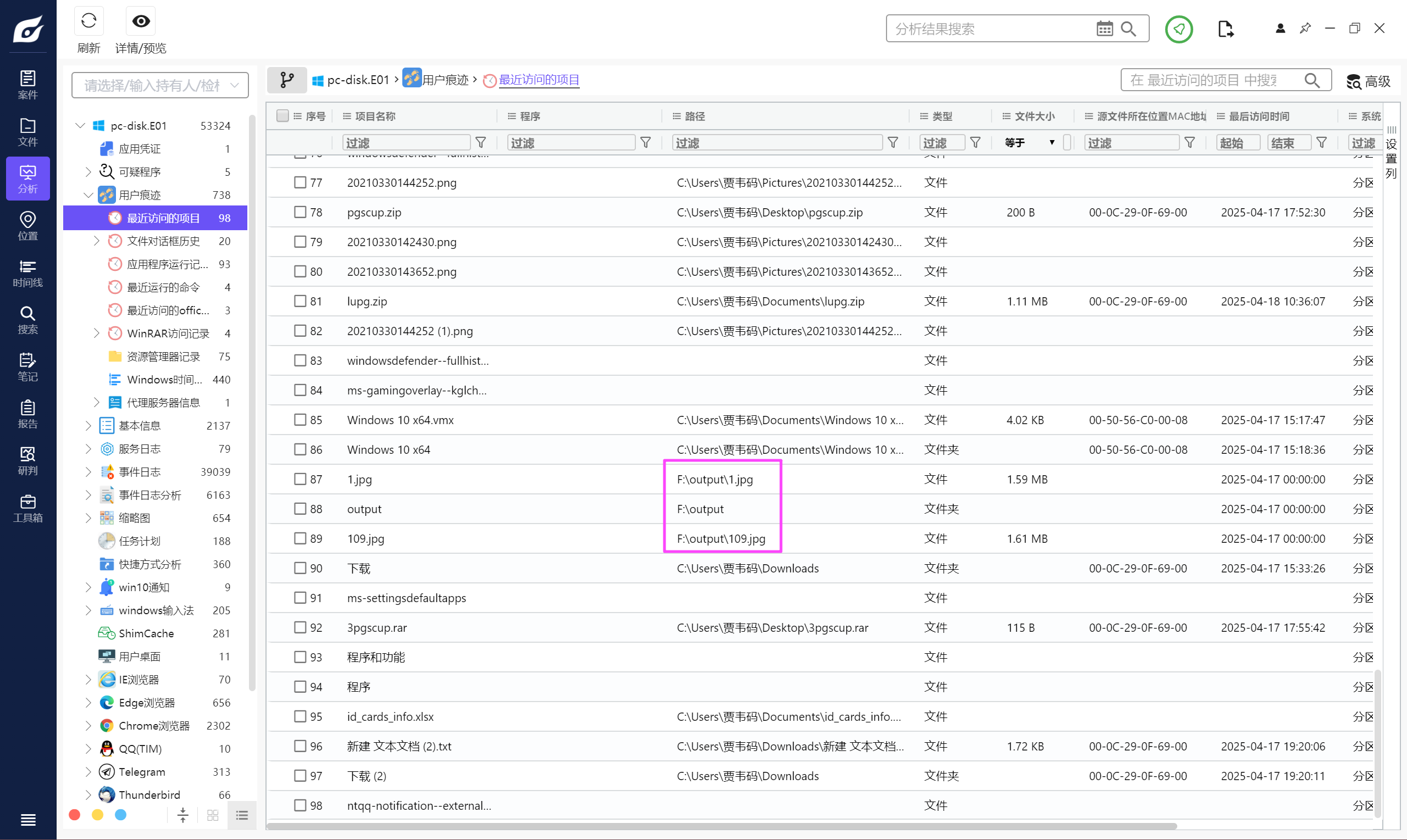
看一下用户的访问记录,发现有个 F 盘,就是这个挂载的盘符。
F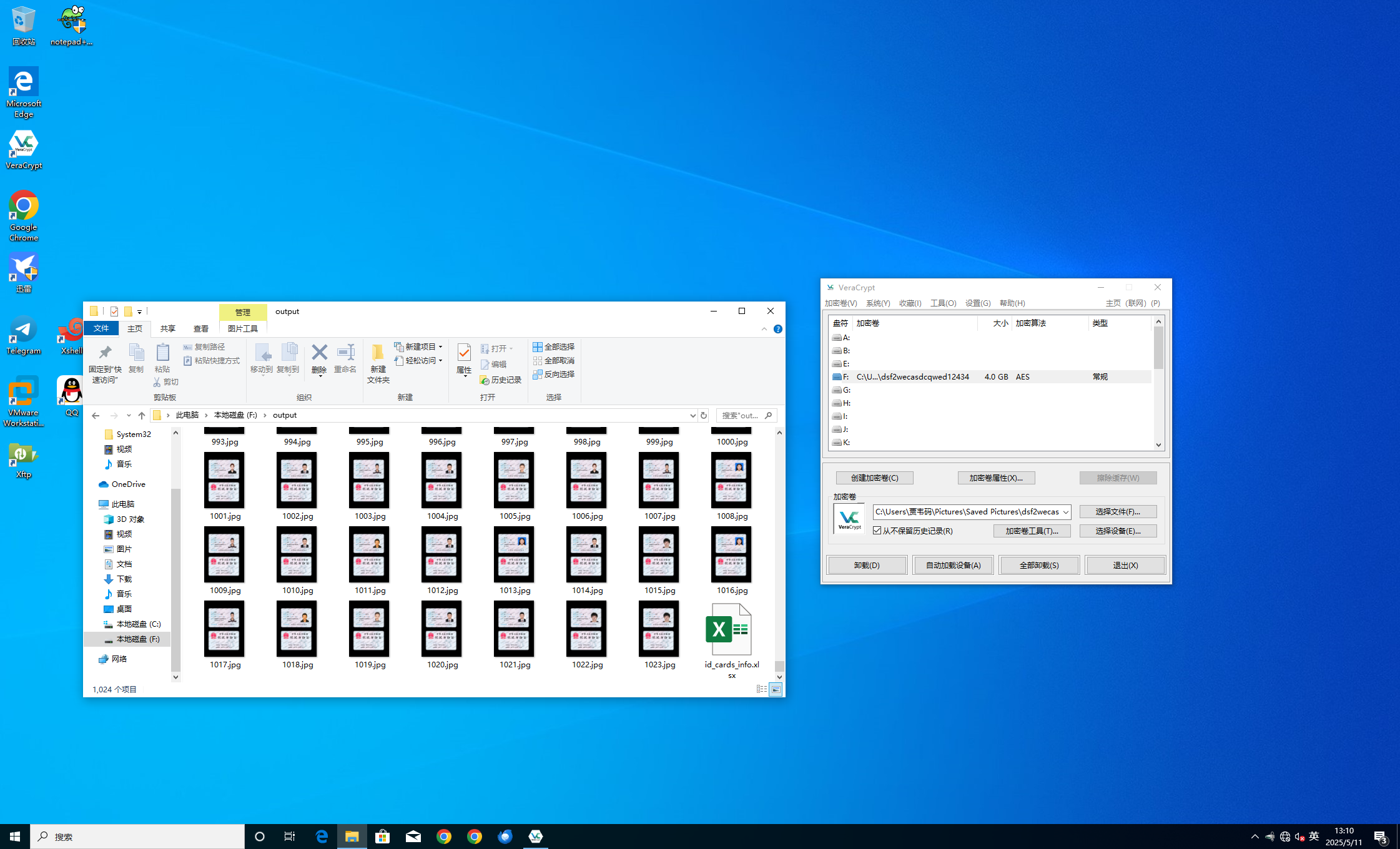
1023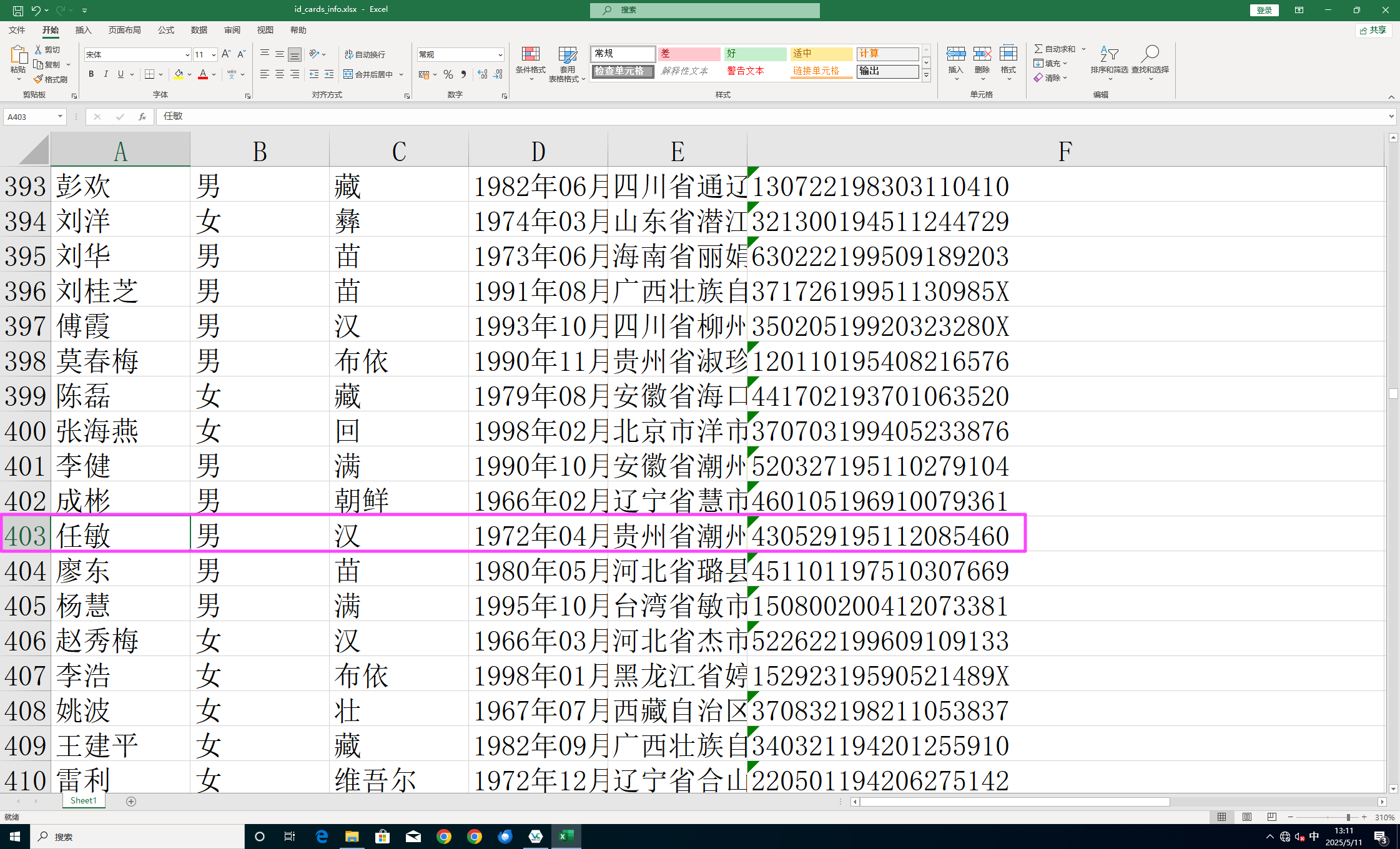
430529195112085460
有个 3pgscup.rar,没找到文件在哪。

无,直接 xwf 爆搜 rar 文件头 52 61 72 21 1a 07 01 00。
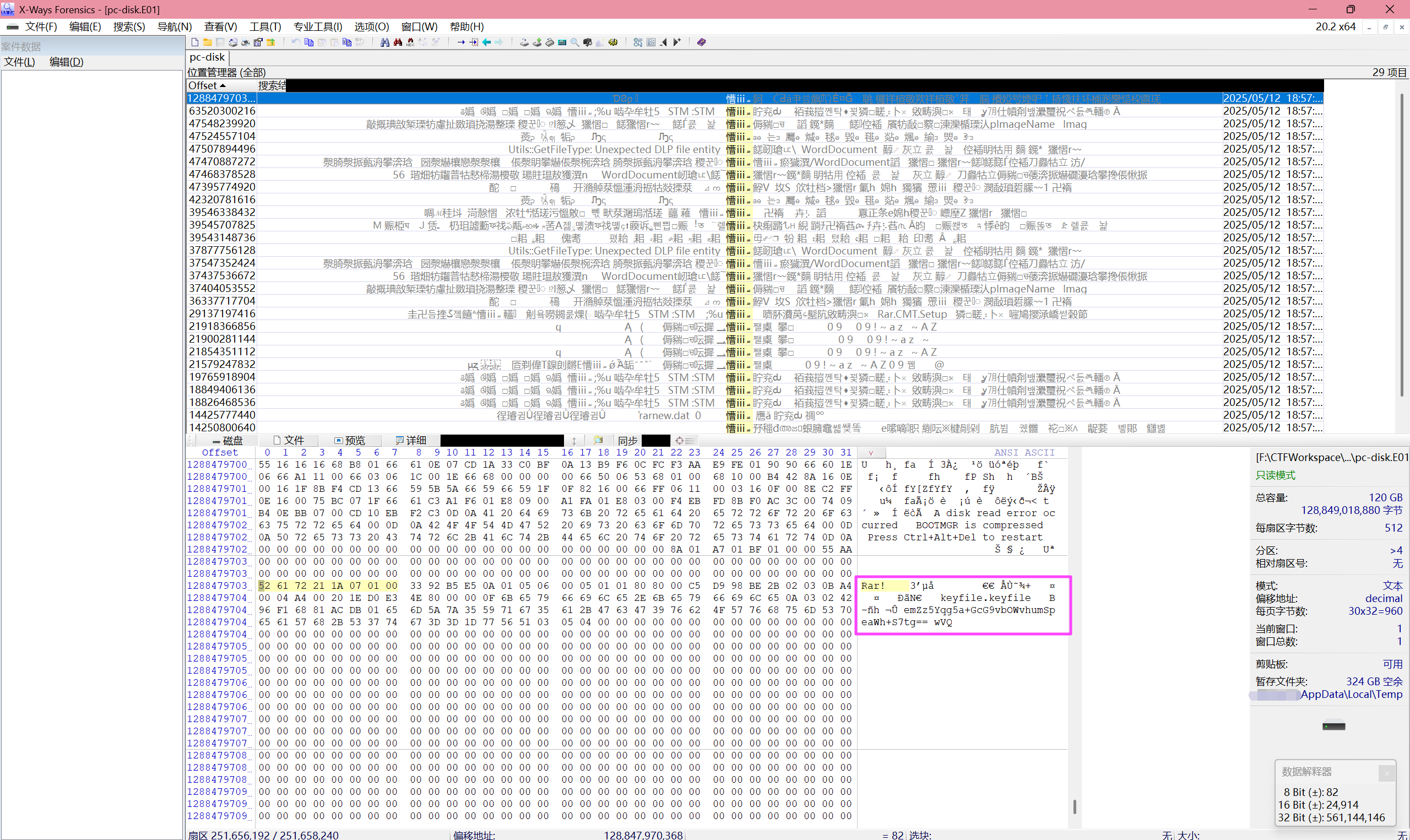
1022cc083a4a5a9e2036065e2822c48e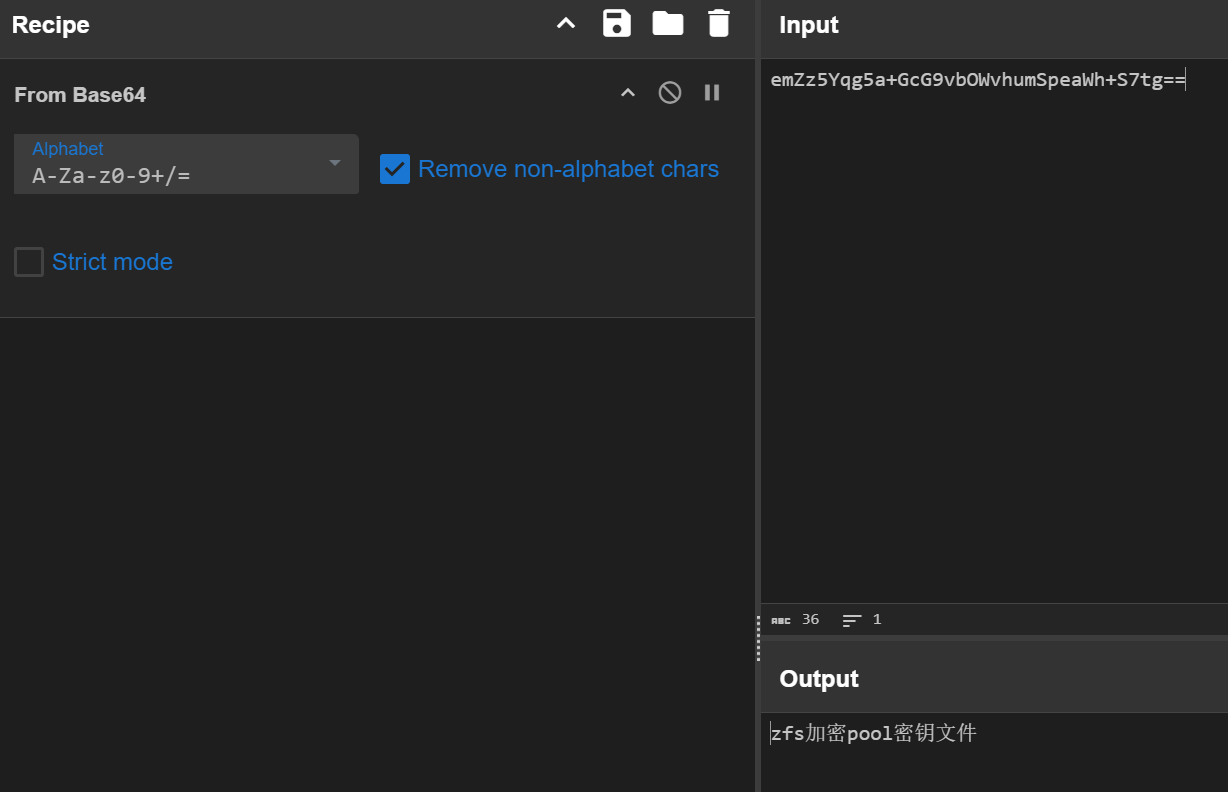
zfs加密pool密钥文件
Outlook
com.apple.Notes
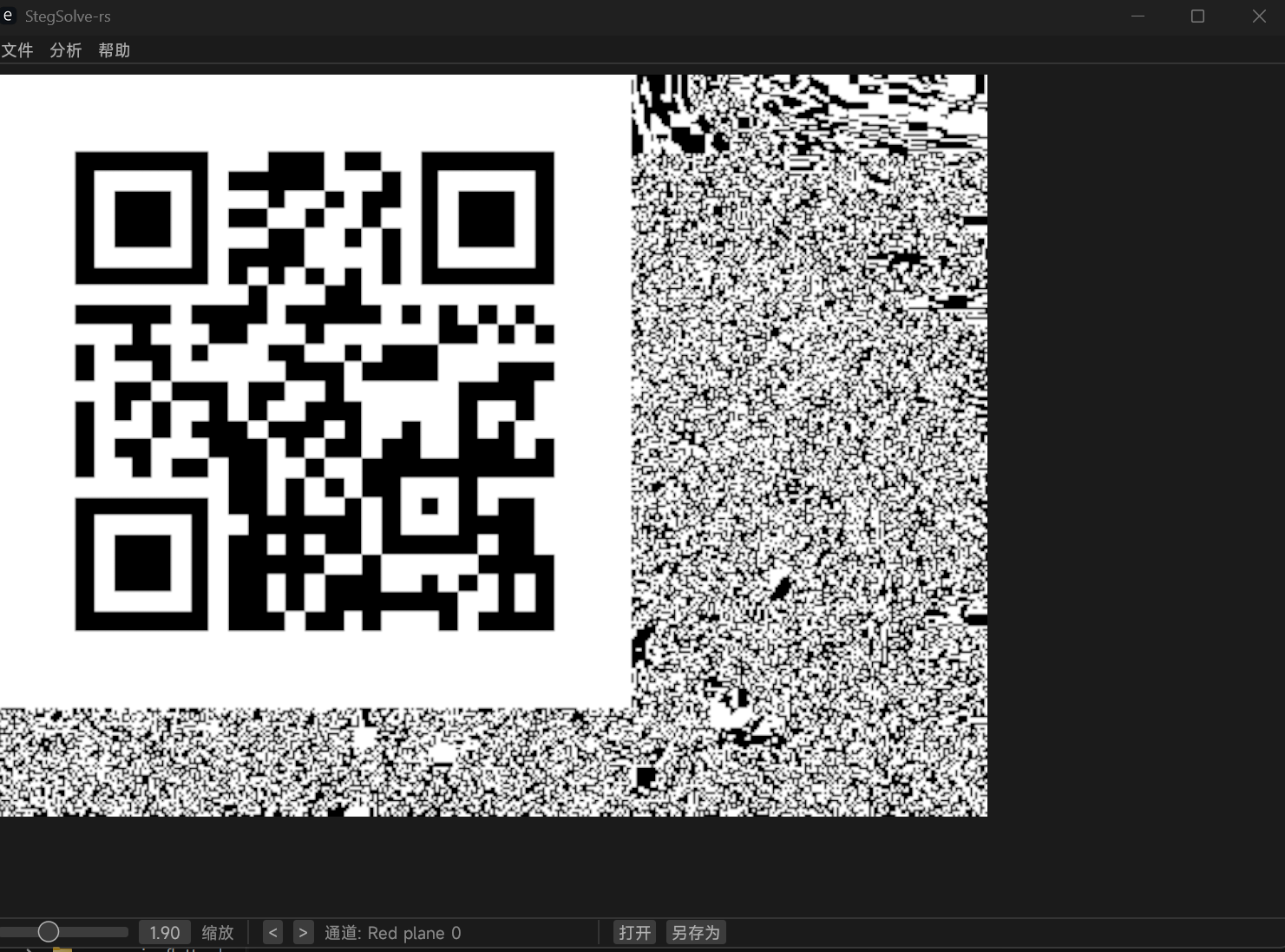
Red plane 0 通道有一个二维码,扫出来就是隐藏的内容。
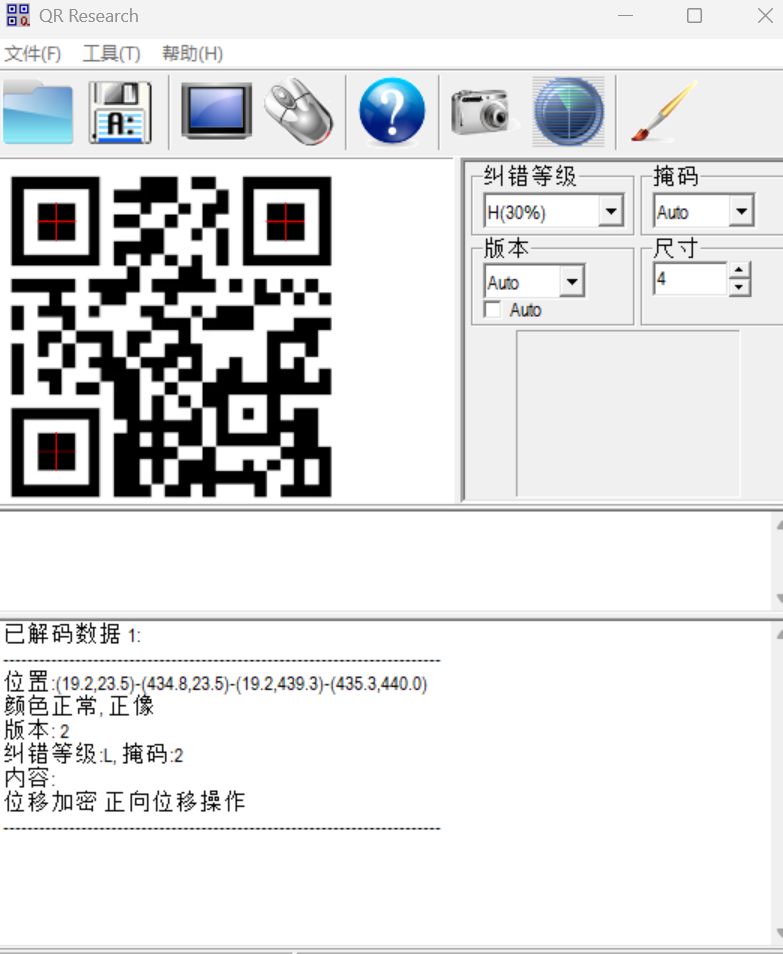
位移加密 正向位移操作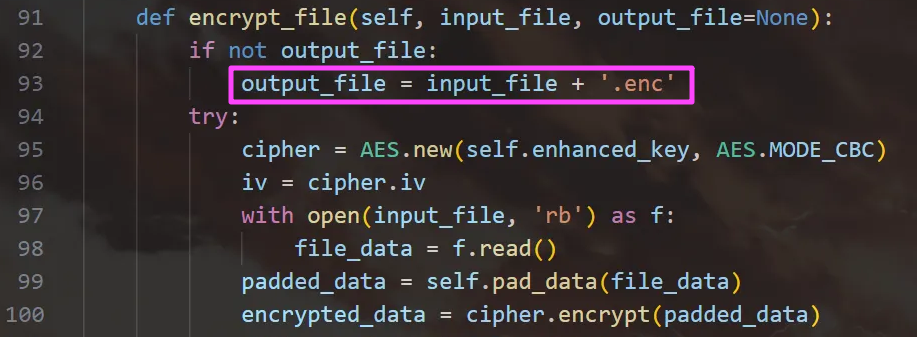
enc
只有电脑桌面上这一个。
1``
解压出来一个 face1.jpg 和 资料.docx,这个 face1.jpg 和后面的冰箱有关,另一个资料.docx里面存了贾韦码的一些信息,门锁信息就在其中。

金刚Ⅲ号
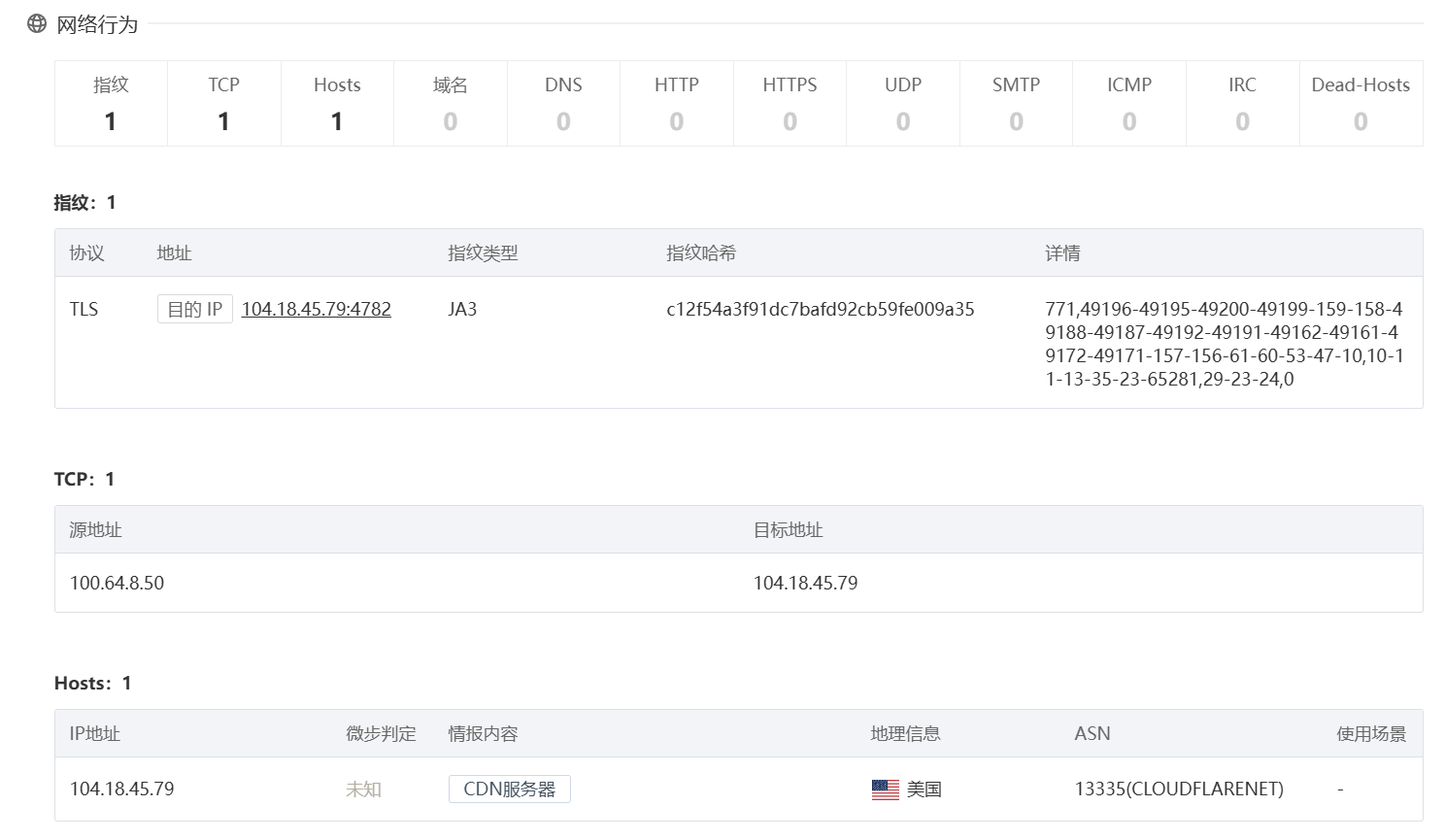
104.18.45.79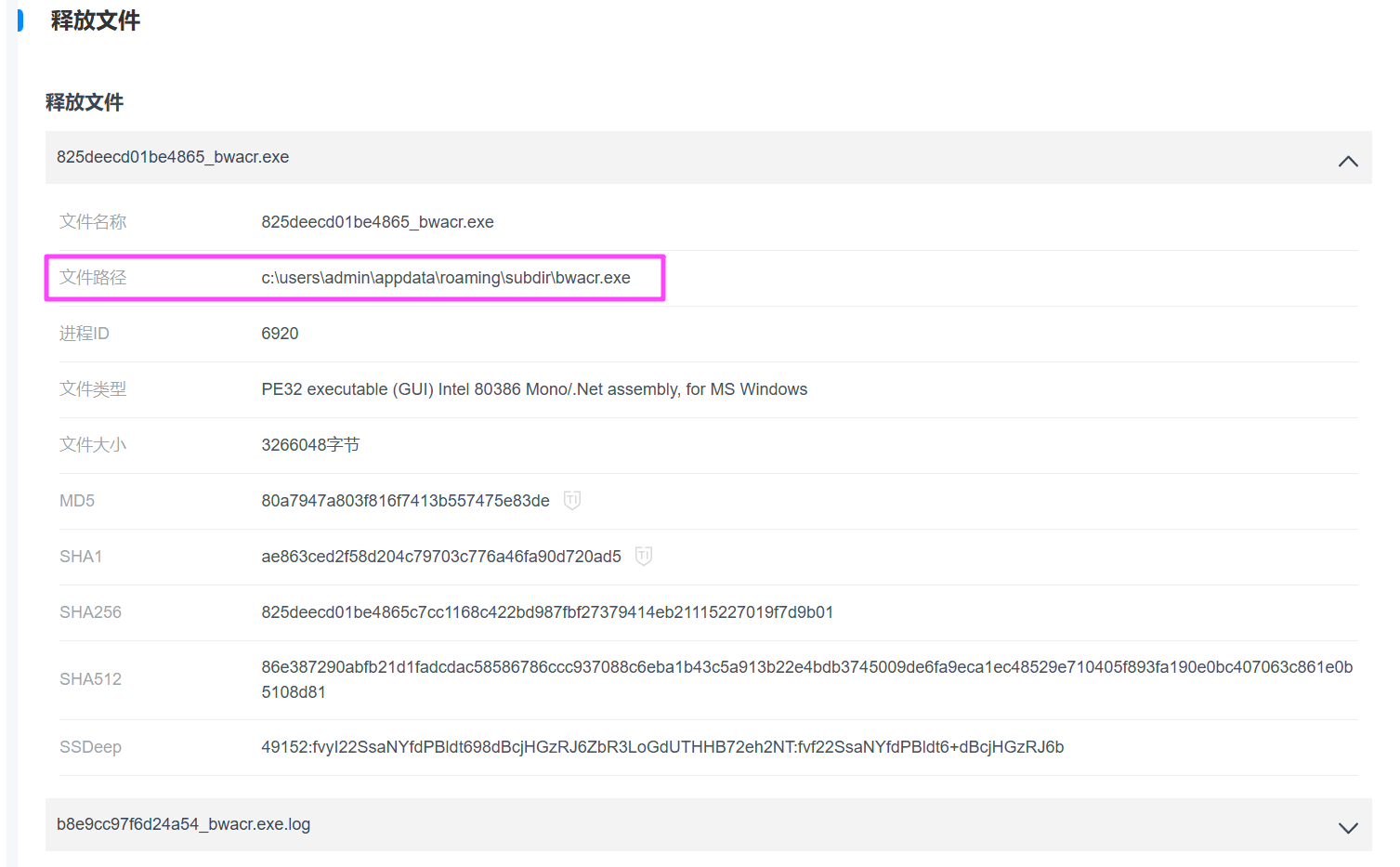

SubDirBwAcr.exe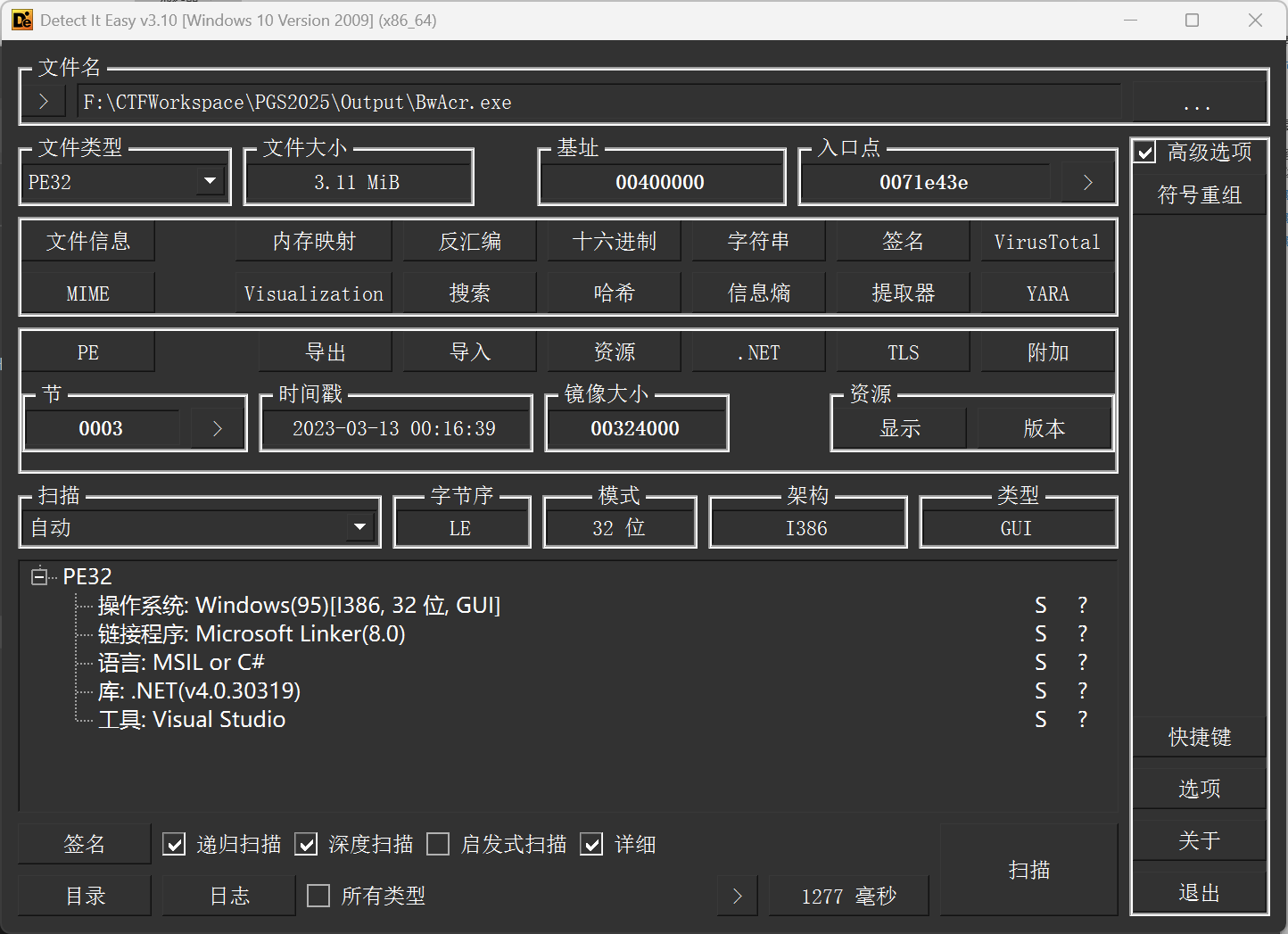
.NET 写的,用 dnSpy 去看。
有疑似获取账户和密码的操作,这几个里面有几个是浏览器。
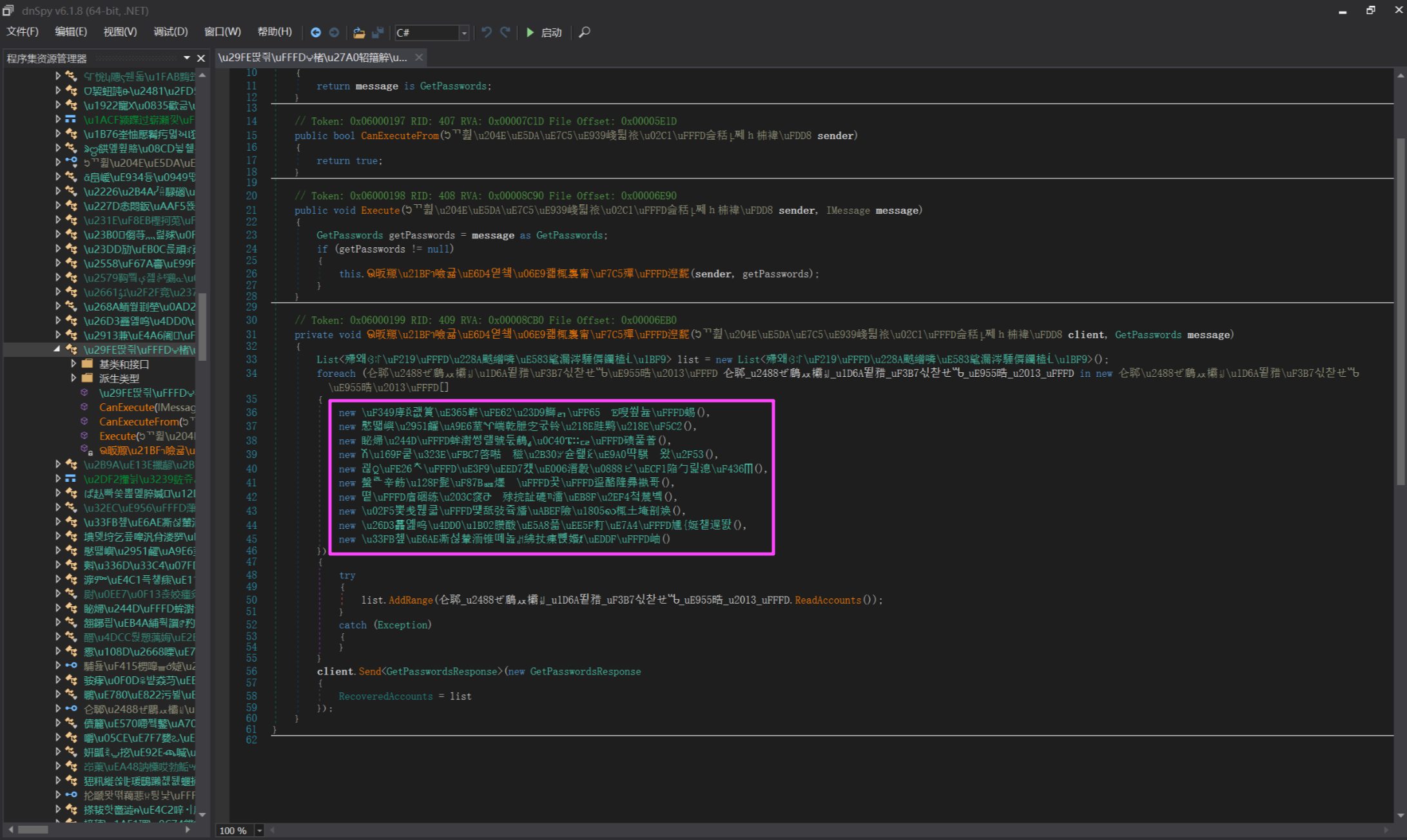
交叉引用一下里面的 ReadAccounts,用到他的浏览器有 Firefox, Edge, Yandex, Opera, Google Chrome, OperaGX, Brave, IE 一共 8 个,剩下两个是 FileZilla 和 winscp,和这个题没关系。

8
开源的,直接上 Github 去看源码。
https://github.com/quasar/Quasar/blob/master/Quasar.Client/Helper/SystemHelper.cs
Unknown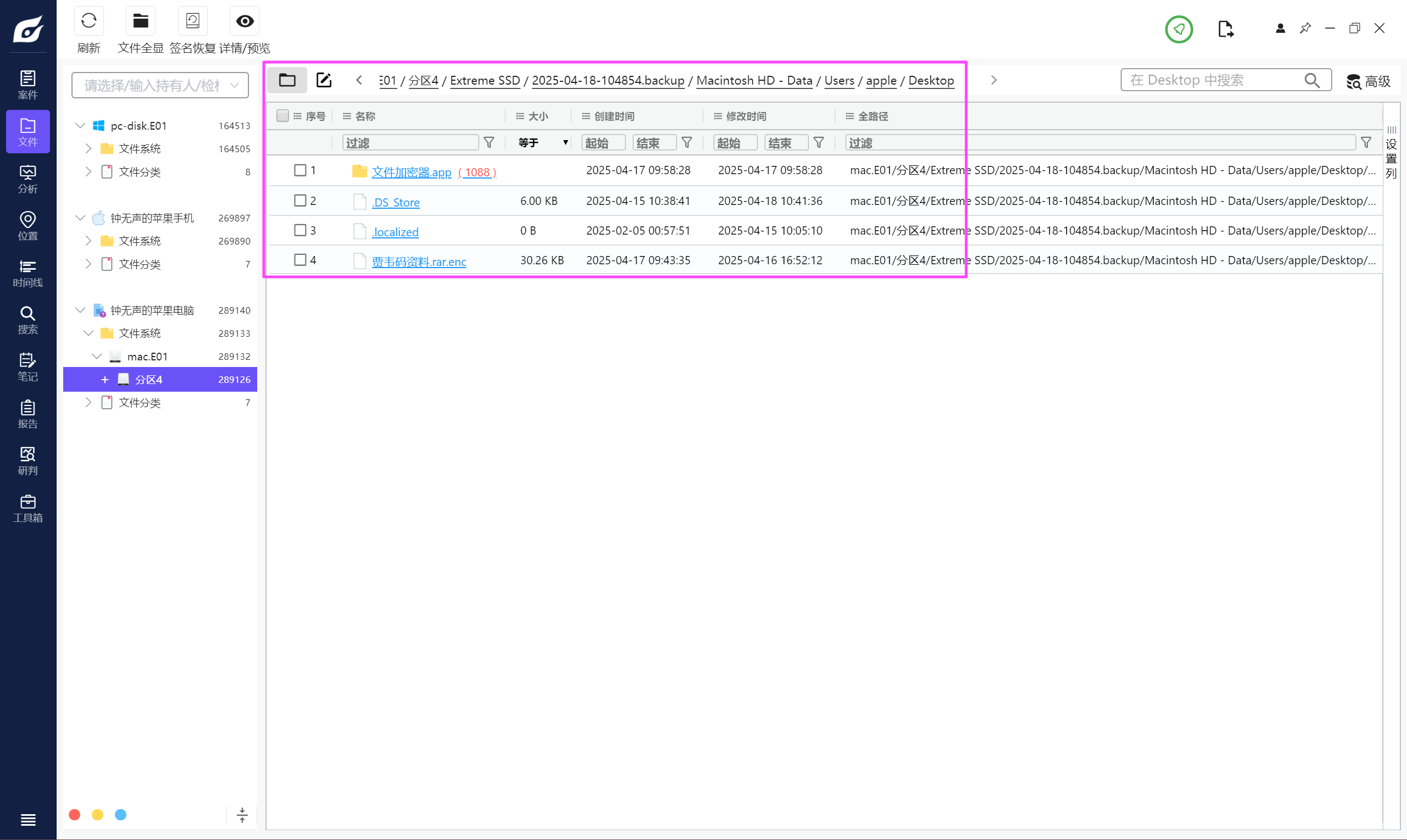
加密程序在苹果电脑的桌面,拷出来逆向一下。
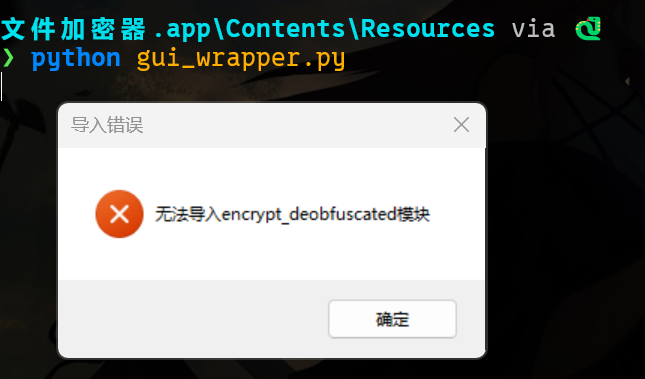
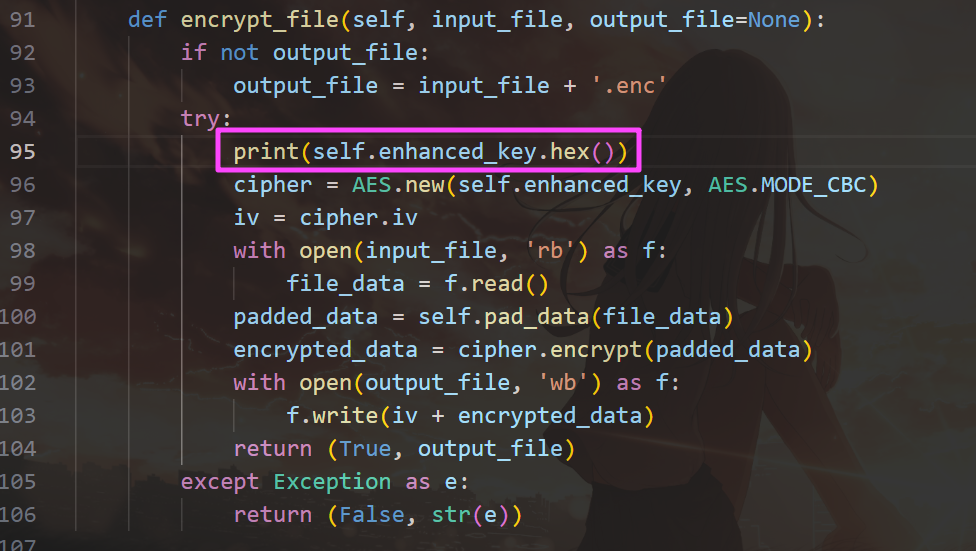
直接运行会报错,找不到这个 encrypt_deobfuscated 模块,这个就是加密文件的核心。
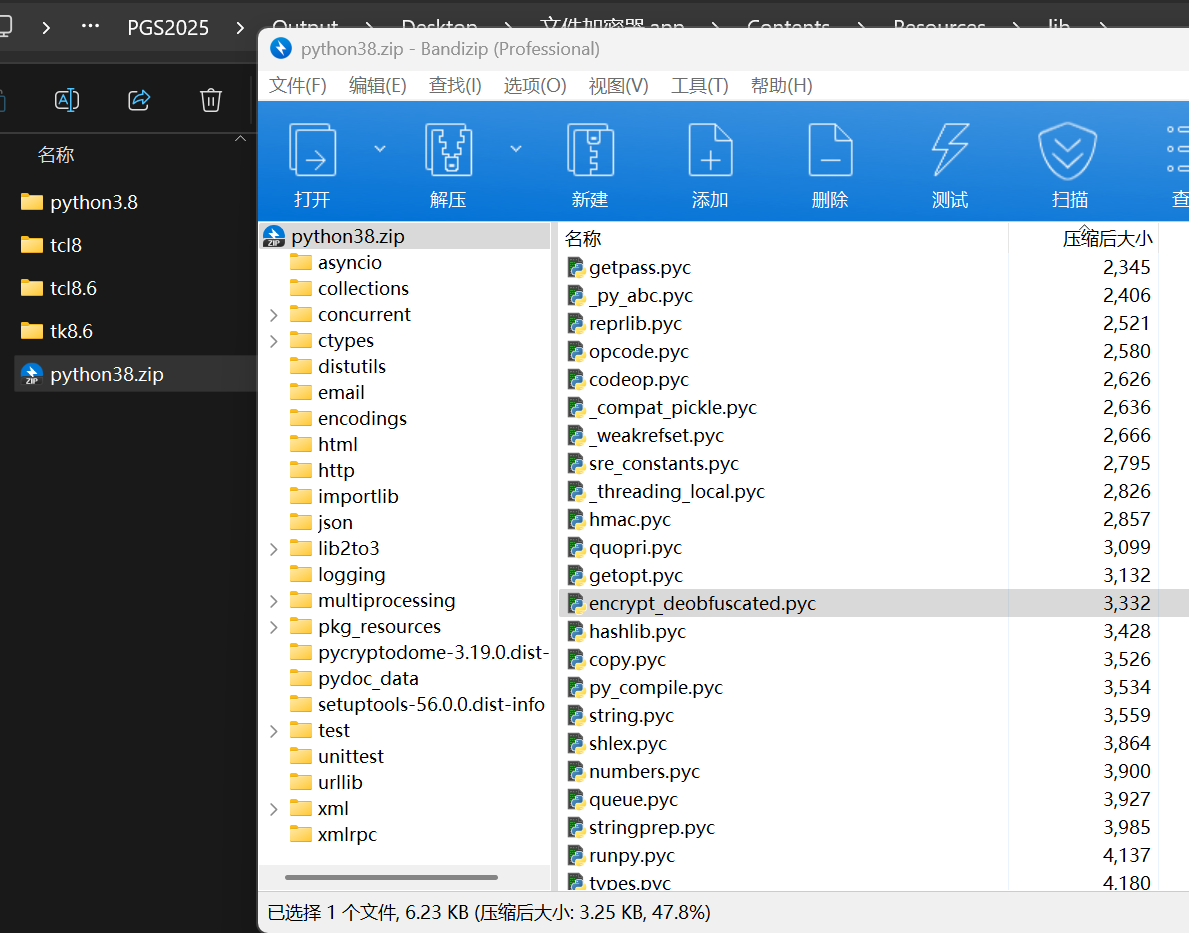
lib 文件夹里面有这个模块,解压出来用 pylingual 反编译一下。
# Decompiled with PyLingual (https://pylingual.io)
# Internal filename: encrypt_deobfuscated.pyc
# Bytecode version: 3.8.0rc1+ (3413)
# Source timestamp: 2025-04-17 01:58:27 UTC (1744855107)
import os
import sys
import tkinter as tk
from tkinter import filedialog, messagebox
from Crypto.Cipher import AES
import base64
import hashlib
import time
import random
class EncryptionTool:
def __init__(self):
self._generate_key()
def _generate_key(self):
seed_values = [(19, 7, 83), (5, 31, 69), (13, 11, 86), (41, 3, 76), (2, 57, 55), (23, 5, 96), (17, 13, 58), (29, 7, 94), (11, 19, 102), (7, 17, 42), (43, 3, 48), (37, 11, 51), (3, 43, 52), (59, 7, 53), (47, 5, 54)]
key_parts = []
for a, b, base in seed_values:
val = (a * b % 60 + base) % 256
if val % 2 == 0:
val = (val + 13) % 256
else:
val = (val + 7) % 256
key_parts.append(chr(val))
scrambled = []
indices = [3, 7, 2, 12, 0, 11, 5, 14, 9, 1, 6, 4, 10, 8, 13]
for idx in indices:
scrambled.append(key_parts[idx])
raw_key = ''.join(scrambled)
timestamp = int(time.time()) % 1000
random_val = random.randint(1, 255)
entropy = chr(timestamp % 256) + chr(random_val)
temp_key = hashlib.sha256((raw_key + entropy).encode()).digest()
self._descramble_key(temp_key)
def _descramble_key(self, temp_key):
mixed_base = b''.join([bytes([b ^ 42]) for b in temp_key[:10]])
actual_key = 'SecureKey123456'
self.enhanced_key = self.enhance_key(actual_key)
def enhance_key(self, key):
round1 = self._add_salt(key)
round2 = self._ascii_transform(round1)
round3 = self._xor_transform(round2)
round4 = round3[::-1]
final_key = hashlib.md5(round4.encode()).digest()
return final_key
def _add_salt(self, key):
salt_components = ['salt', '_', 'value']
return key + ''.join(salt_components)
def _ascii_transform(self, text):
result = ''
for i in range(len(text)):
ascii_val = ord(text[i])
if i % 3 == 0:
result += chr((ascii_val + 7) % 256)
elif i % 3 == 1:
result += chr((ascii_val ^ 15) % 256)
else:
result += chr(ascii_val * 5 % 256)
return result
def _xor_transform(self, text):
xor_keys = ['XorKey123456789', 'AnotherKey987654']
result = text
for xor_key in xor_keys:
temp = ''
for i in range(len(result)):
temp += chr(ord(result[i]) ^ ord(xor_key[i % len(xor_key)]))
result = temp
return result
def pad_data(self, data):
block_size = AES.block_size
padding_length = block_size - len(data) % block_size
padding = bytes([padding_length]) * padding_length
return data + padding
def unpad_data(self, data):
padding_length = data[-1]
return data[:-padding_length]
def encrypt_file(self, input_file, output_file=None):
if not output_file:
output_file = input_file + '.enc'
try:
cipher = AES.new(self.enhanced_key, AES.MODE_CBC)
iv = cipher.iv
with open(input_file, 'rb') as f:
file_data = f.read()
padded_data = self.pad_data(file_data)
encrypted_data = cipher.encrypt(padded_data)
with open(output_file, 'wb') as f:
f.write(iv + encrypted_data)
return (True, output_file)
except Exception as e:
return (False, str(e))
class EncryptionGUI:
def __init__(self, root):
self.root = root
self.root.title('File Encryption Tool')
self.root.geometry('500x300')
self.root.resizable(False, False)
self.encryptor = EncryptionTool()
self.setup_ui()
def setup_ui(self):
file_frame = tk.Frame(self.root, pady=20)
file_frame.pack(fill='x')
tk.Label(file_frame, text='Select File to Encrypt:').pack(side='left', padx=10)
self.file_path = tk.StringVar()
tk.Entry(file_frame, textvariable=self.file_path, width=30).pack(side='left', padx=5)
tk.Button(file_frame, text='Browse', command=self.browse_file).pack(side='left', padx=5)
action_frame = tk.Frame(self.root, pady=20)
action_frame.pack()
tk.Button(action_frame, text='Encrypt File', command=self.encrypt_file, bg='#4CAF50', fg='white', width=15, height=2).pack(pady=10)
status_frame = tk.Frame(self.root, pady=10)
status_frame.pack(fill='x')
self.status_var = tk.StringVar()
self.status_var.set('Ready')
tk.Label(status_frame, textvariable=self.status_var, bd=1, relief=tk.SUNKEN, anchor=tk.W).pack(fill='x', padx=10)
def browse_file(self):
filename = filedialog.askopenfilename(title='Select File to Encrypt')
if filename:
self.file_path.set(filename)
def encrypt_file(self):
file_path = self.file_path.get()
if not file_path:
messagebox.showerror('Error', 'Please select a file first!')
return
self.status_var.set('Encrypting...')
self.root.update()
success, result = self.encryptor.encrypt_file(file_path)
if success:
self.status_var.set(f'Encryption complete! Output: {result}')
messagebox.showinfo('Success', f'File encrypted successfully!\nOutput: {result}')
else:
self.status_var.set(f'Encryption failed: {result}')
messagebox.showerror('Error', f'Encryption failed: {result}')
def main():
root = tk.Tk()
app = EncryptionGUI(root)
root.mainloop()
if __name__ == '__main__':
main()
42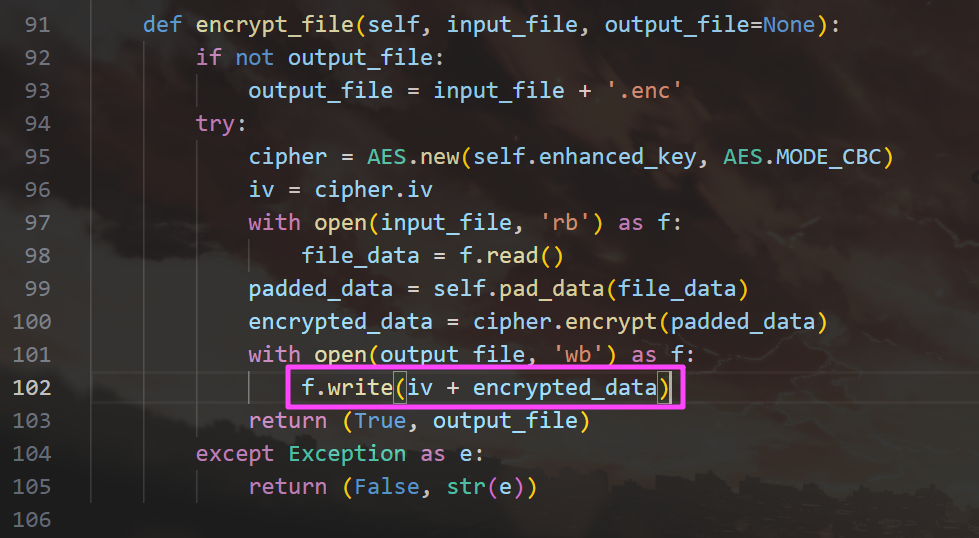
加密后文件的结构是 IV 和加密内容。
iv_encrypted_data
这个函数是对密钥进行一些混淆,但是这个 mixed_base 变量根本就没用到,相当于直接把下面的 actual_key 当成了密钥,符合题目描述。
_descramble_key感谢 Cn5uk 师傅分享的思路
还参考了 S1eepS0rt 大佬的 WP
https://r1.pub/p/pangushi-pgs-forensics-2025-pre-unraid-server/
server1.001 是系统盘。
server2.001 是数据盘,被 LUKS 加密了,我们之前在计算机里面拿到了一个密钥文件就是用来解这个的。
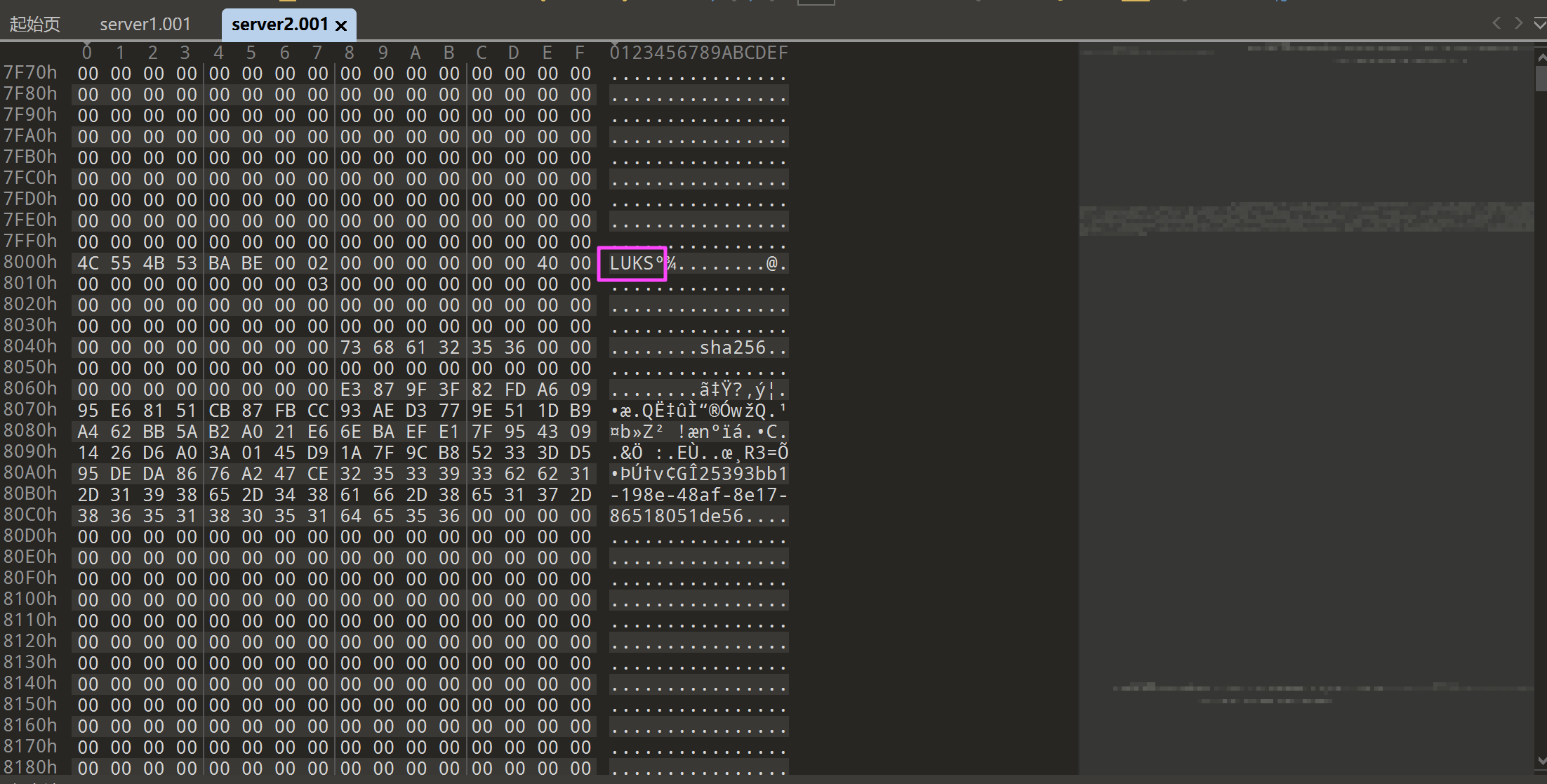
先把 server1.001 和 server2.001 转成 vmdk。


管理员身份运行 VMware,新建虚拟机。
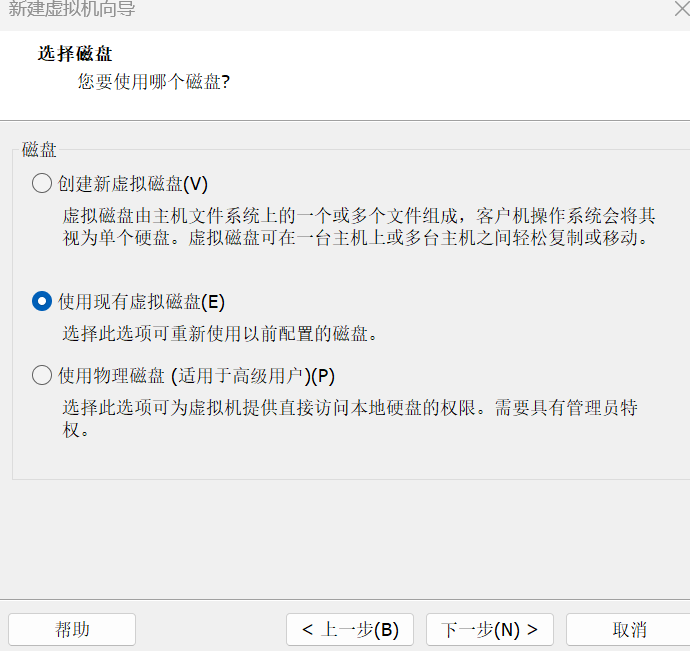
现有磁盘选择 server2.vmdk。
其他默认。
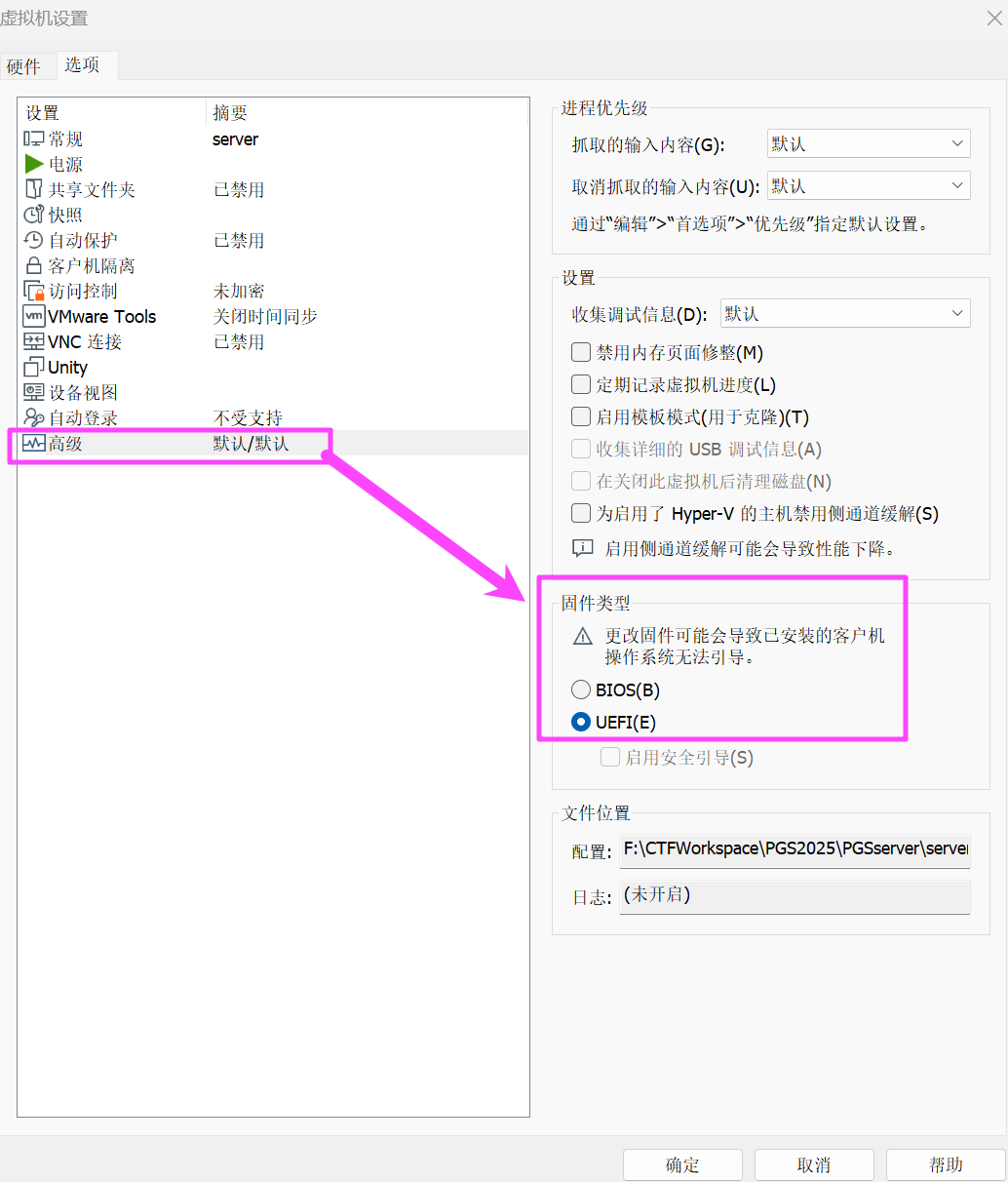
到虚拟机设置里面,把固件类型更改成 UEFI。
打开虚拟机目录,把之前转换出来的 server1.vmdk 拷过来,然后修改一下 vmx 文件。
在末尾添加如下内容:
ehci:0.present = "TRUE"
ehci:0.deviceType = "disk"
ehci:0.fileName="server1.vmdk"
ehci:0.readonly="FALSE"保存,然后重新双击打开 vmx。
接下来需要解密数据盘,关掉虚拟机,先挂载 server1.vmdk,把 keyfile 丢到 config 目录里面,然后修改 disk.cfg,把 luks 密钥路径修改成刚才 keyfile 的。
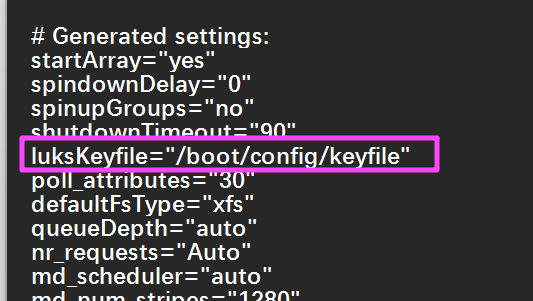
然后重新开启虚拟机。

需要账户密码,直接把 config 里面是 shadow 提出来,john 爆一下 root 密码就好了。
root:P@ssw0rd
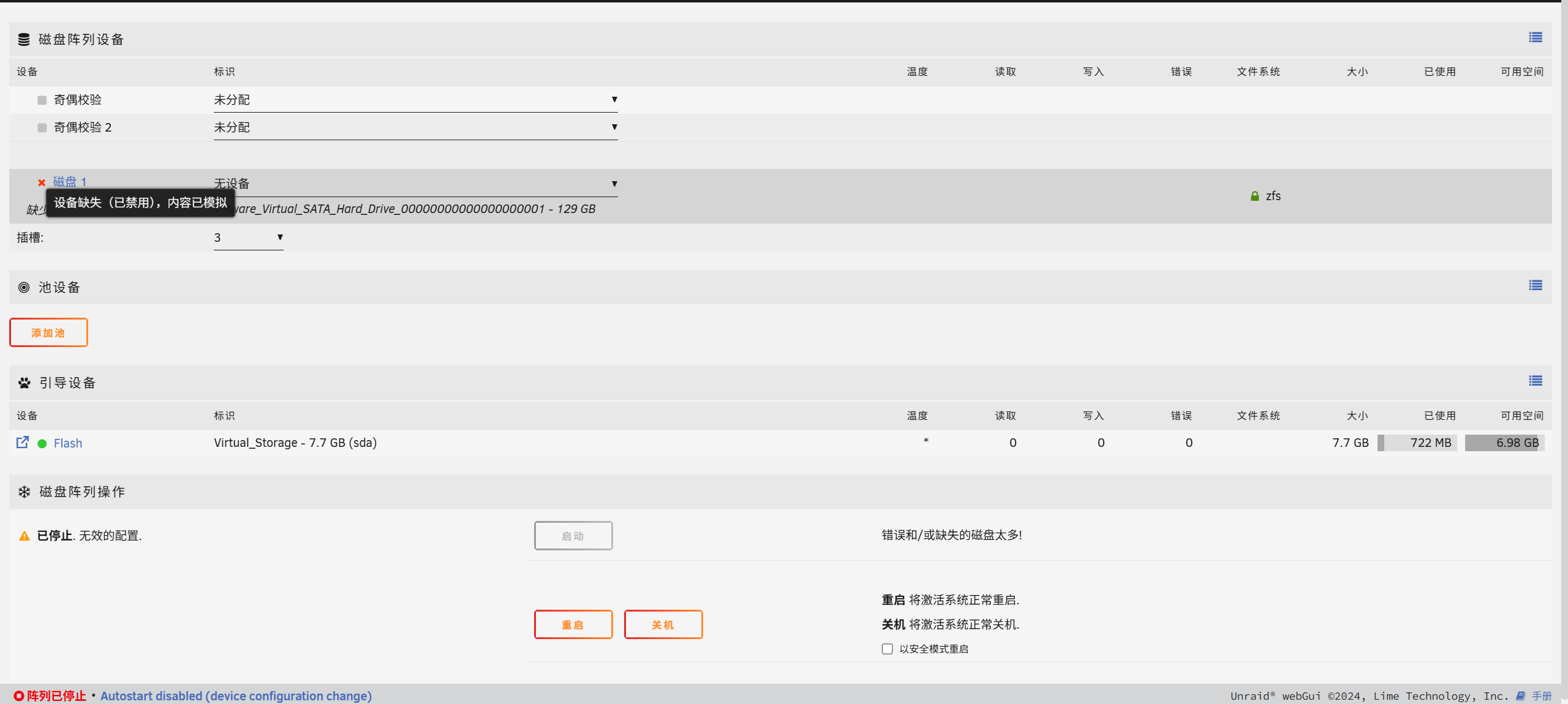
由于虚拟机硬盘 ID 以及名称可能会变化,进去可能检测不到磁盘,需要把 config 目录的 super.dat 删除。
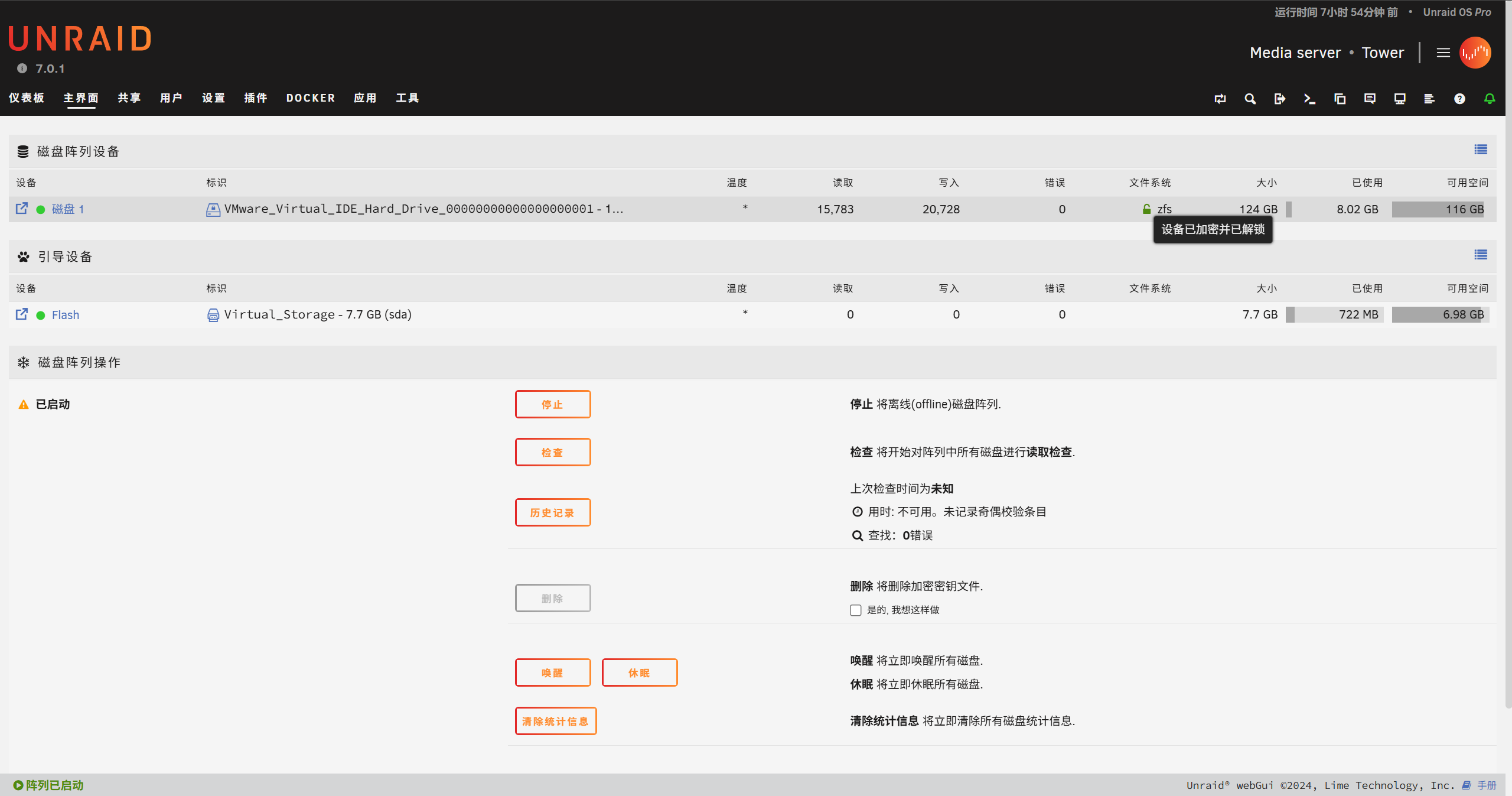
仿真成功。
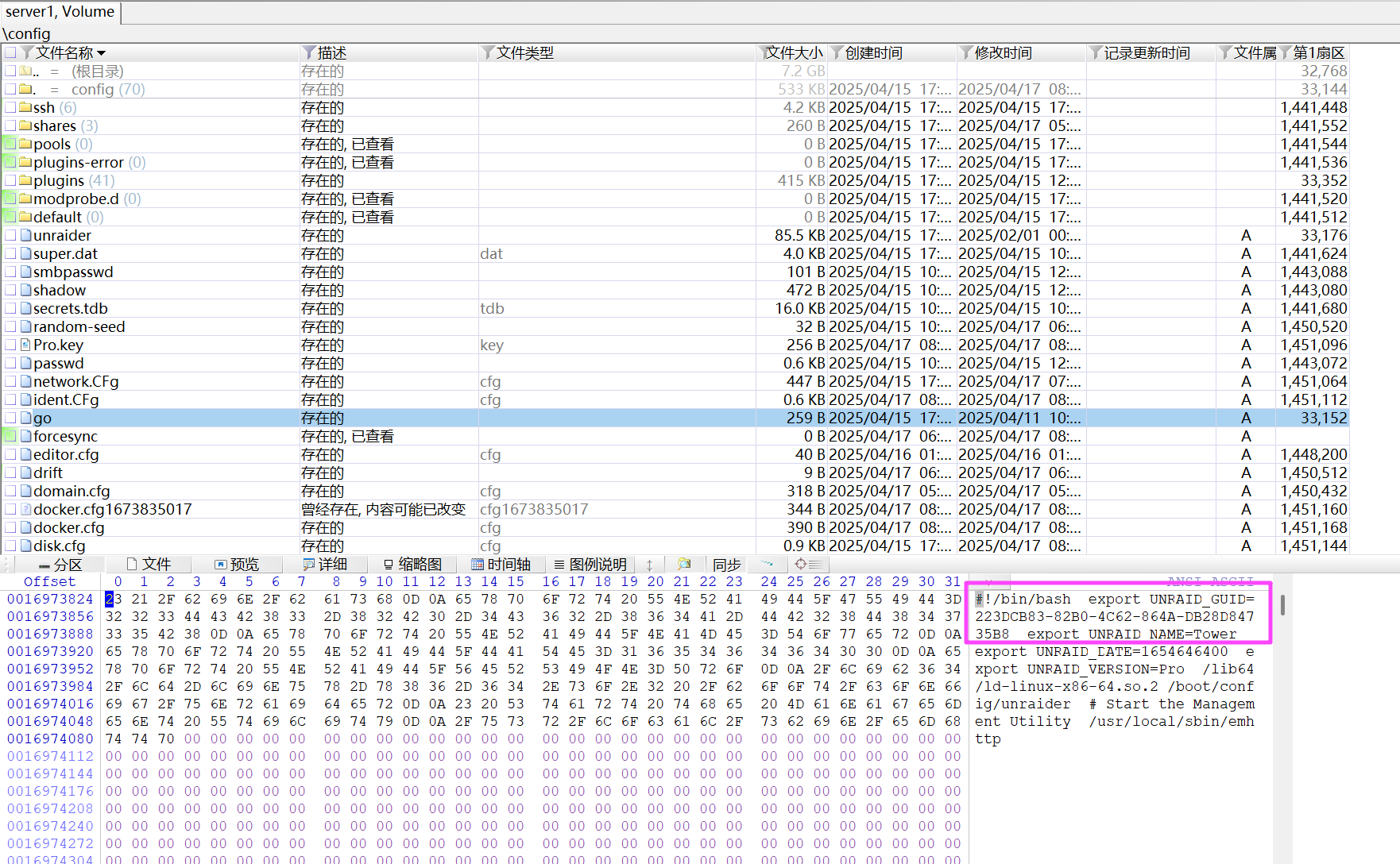
223DCB83-82B0-4C62-864A-DB28D84735B8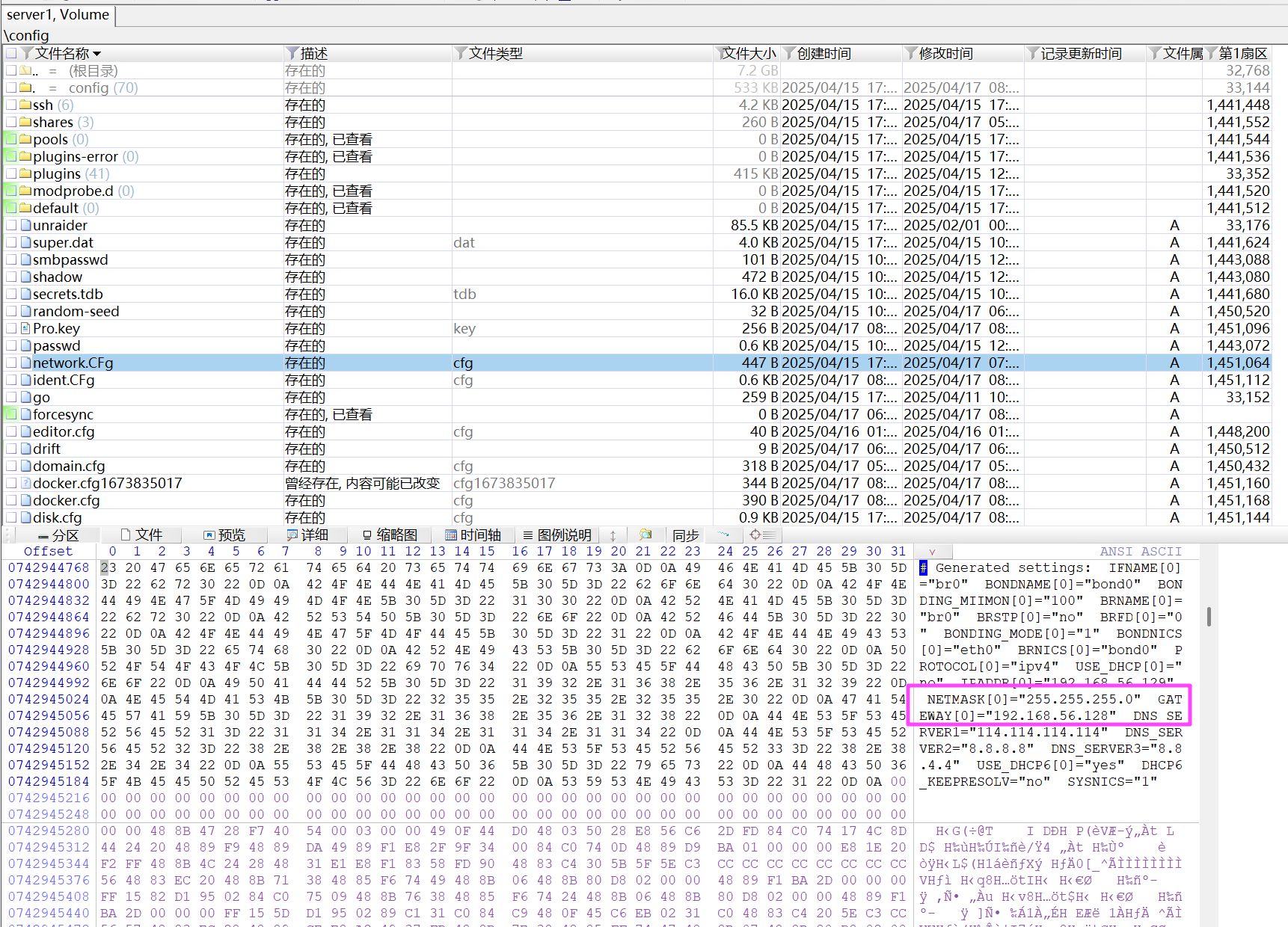
192.168.56.128
zfskeyfileP@ssw0rd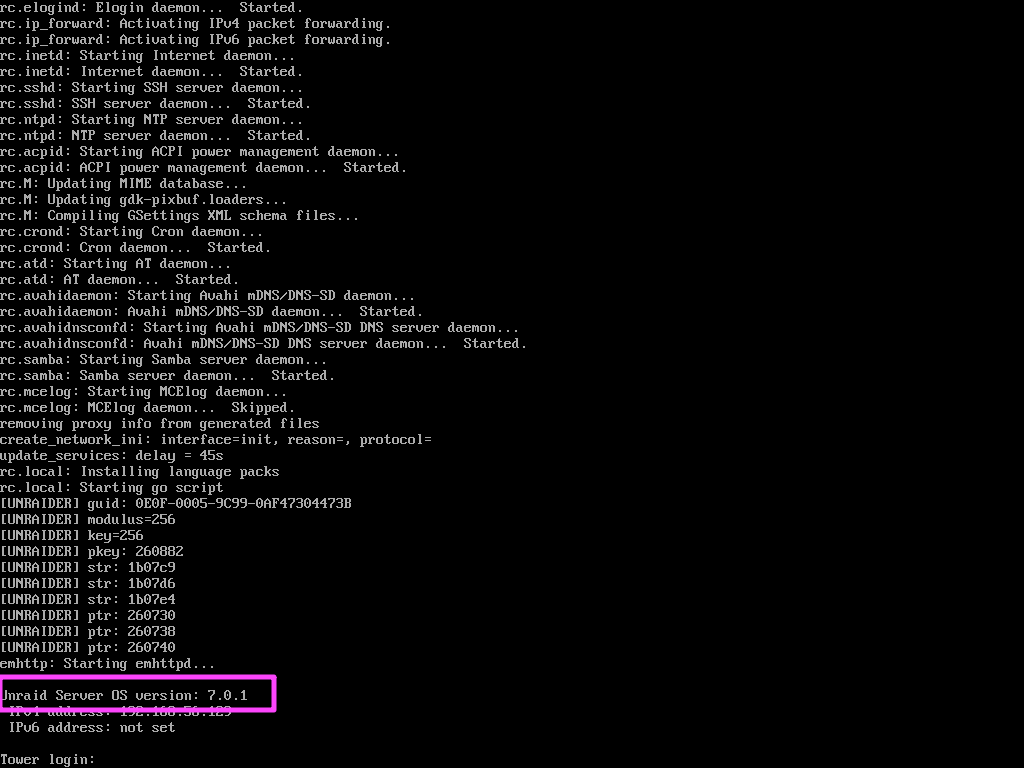
7.0.1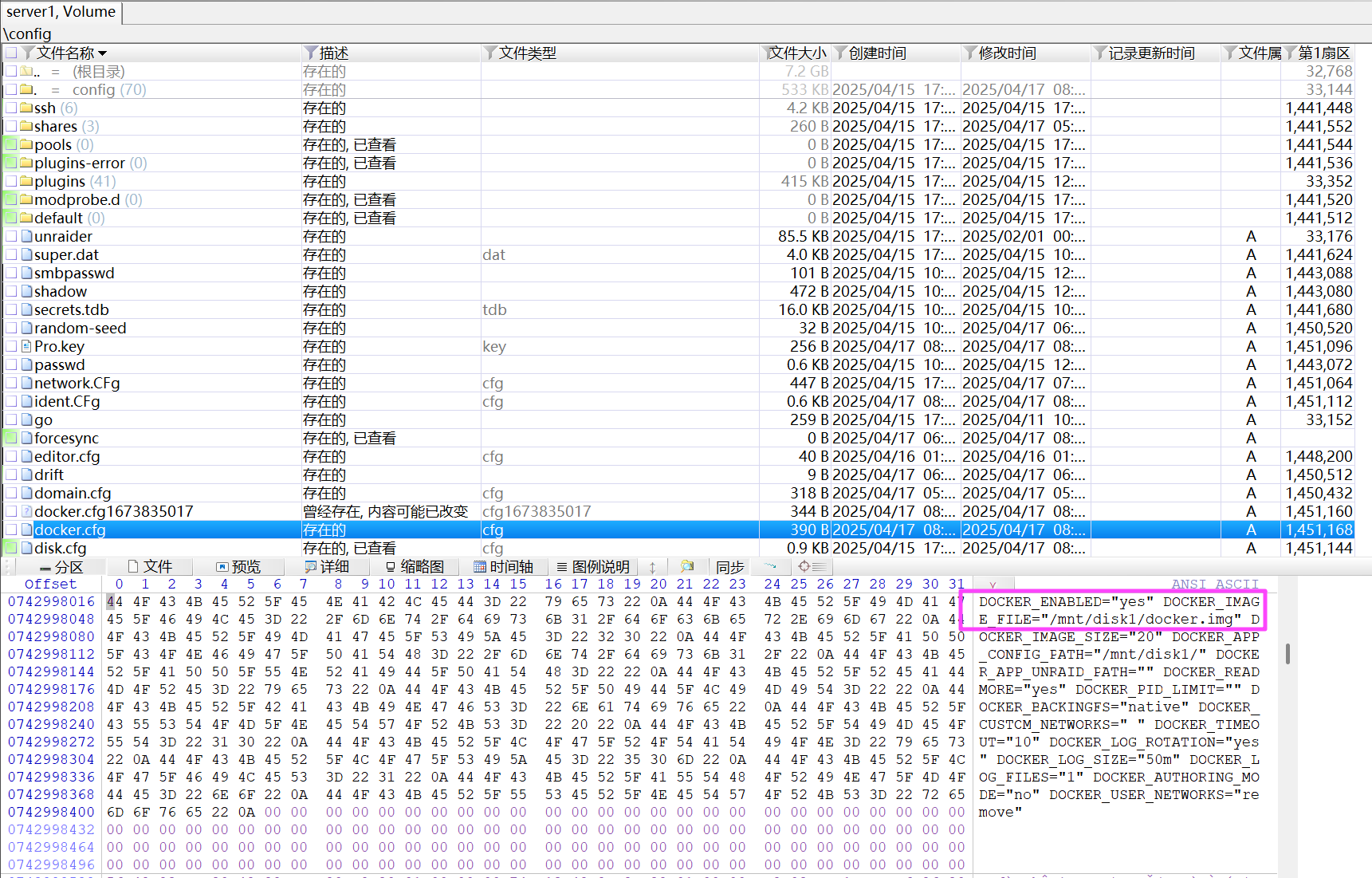
/mnt/disk1/docker.img
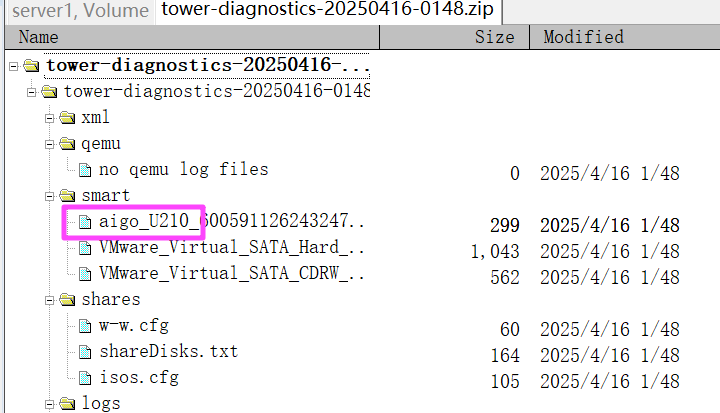
这个 U210 就是他的启动标识。
U210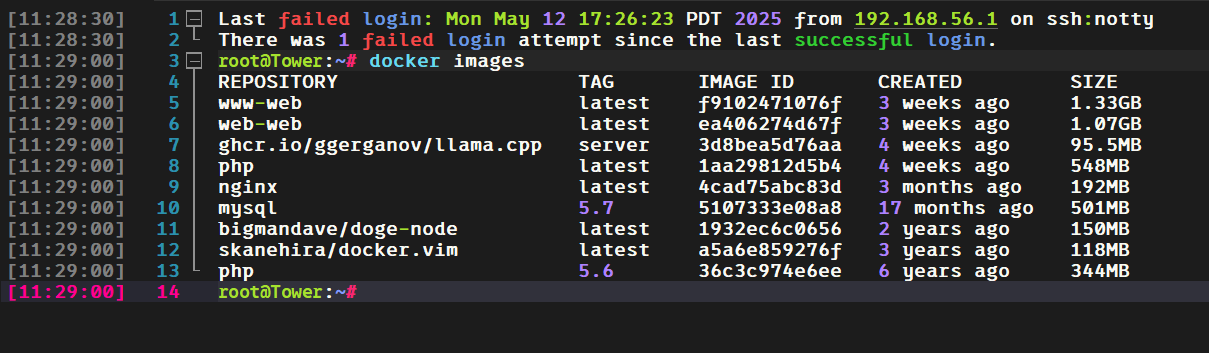
一共 9 个。
9
www-db-1
docker inspect 容器 ID 看一下对外暴露的端口。
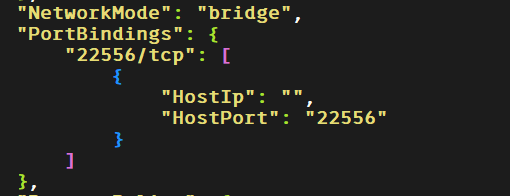
22556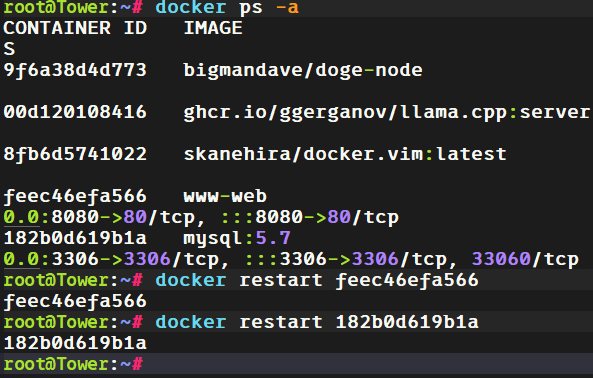
可以先看 Question 14,再看这里,需要进后台。
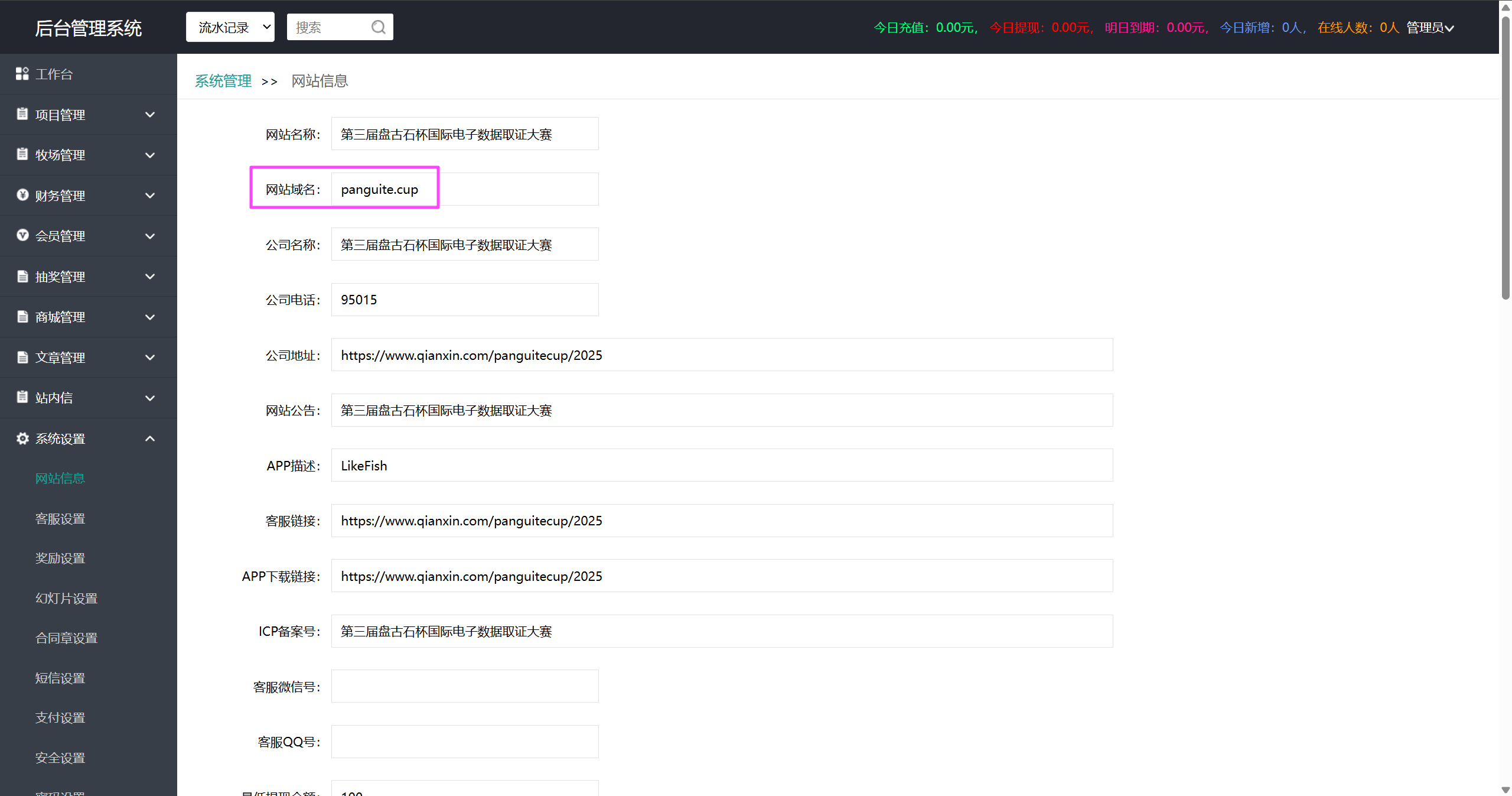
后台系统设置直接看到域名,其实根据浏览记录也能确定,但是不太保险。
panguite.cup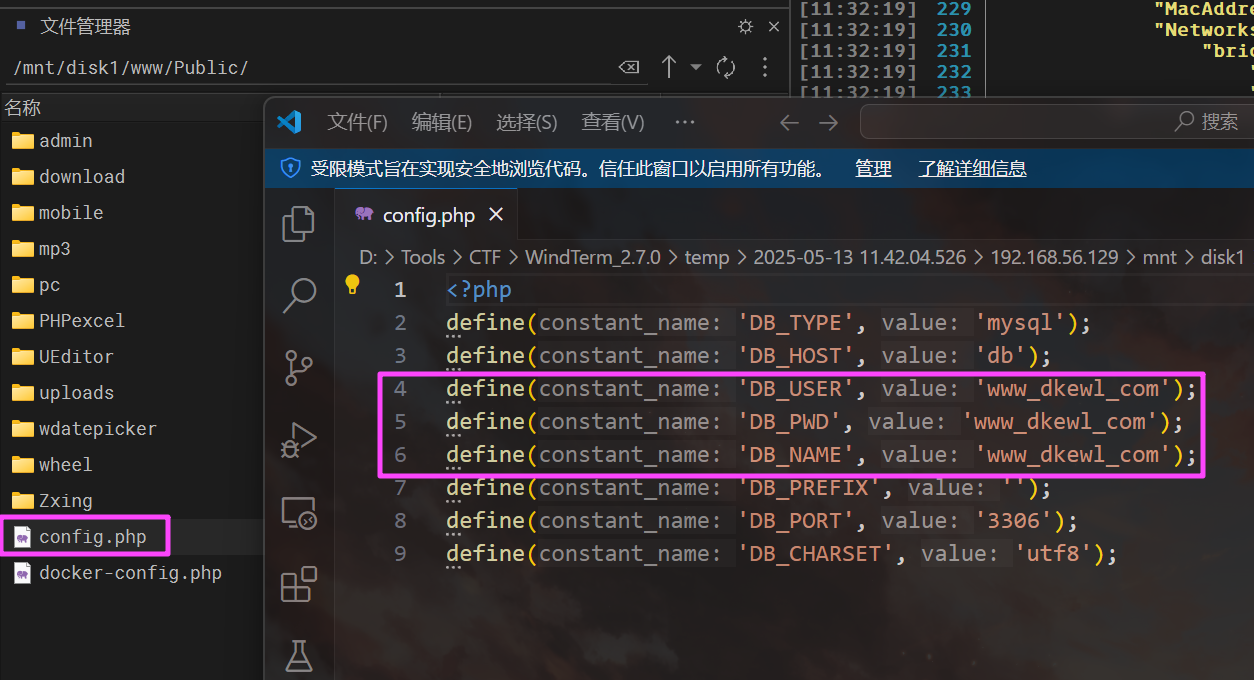
www_dkewl_com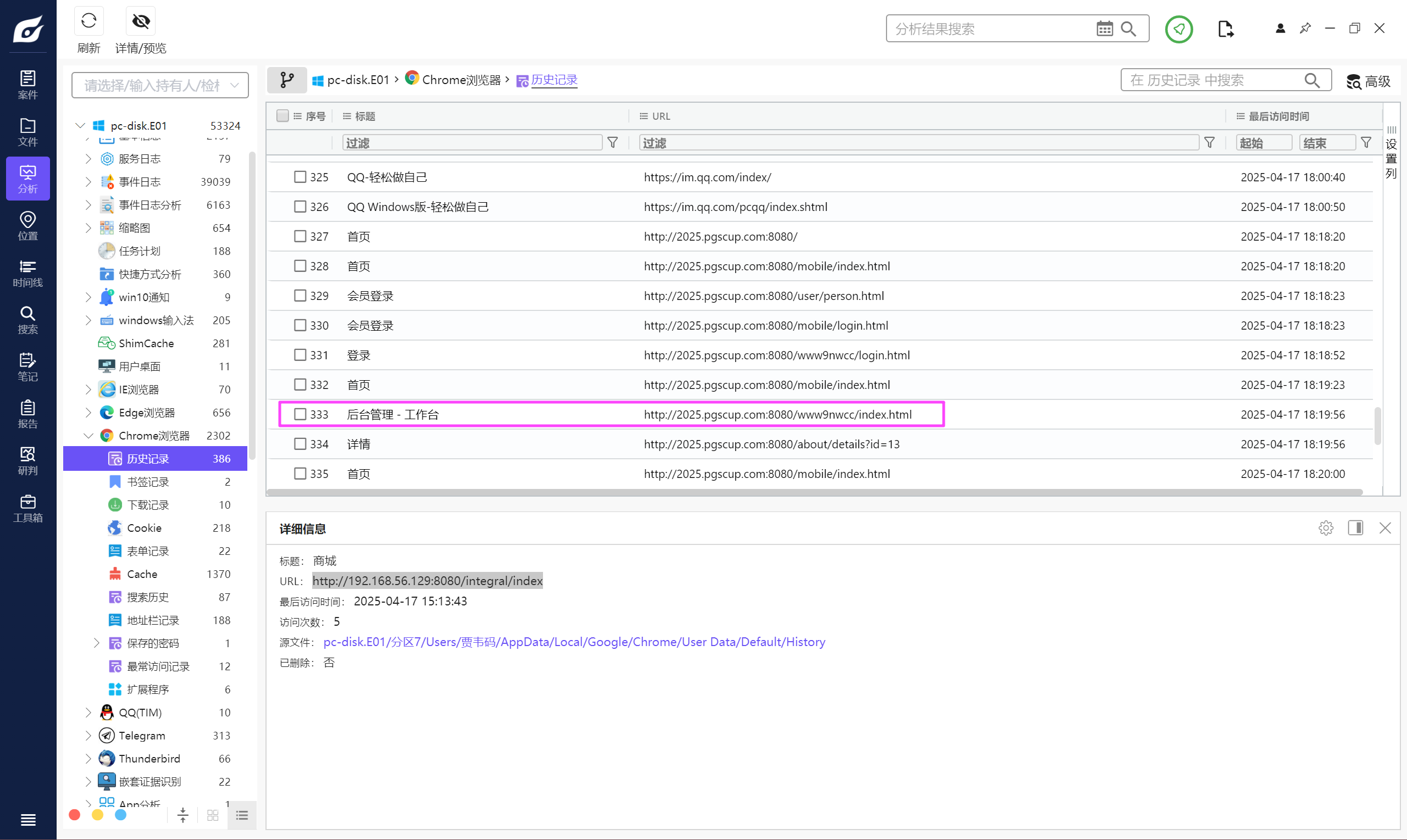
看一下计算机的浏览记录,发现有个后台管理的路由,尝试去访问。
需要密码才能进去,连一下数据库。
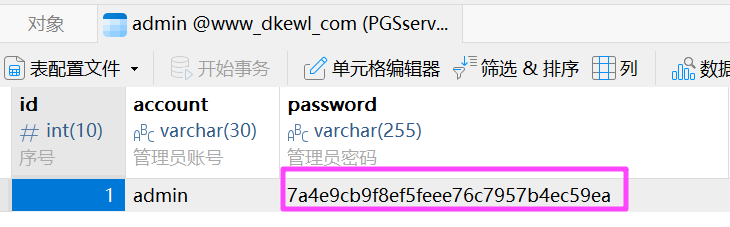
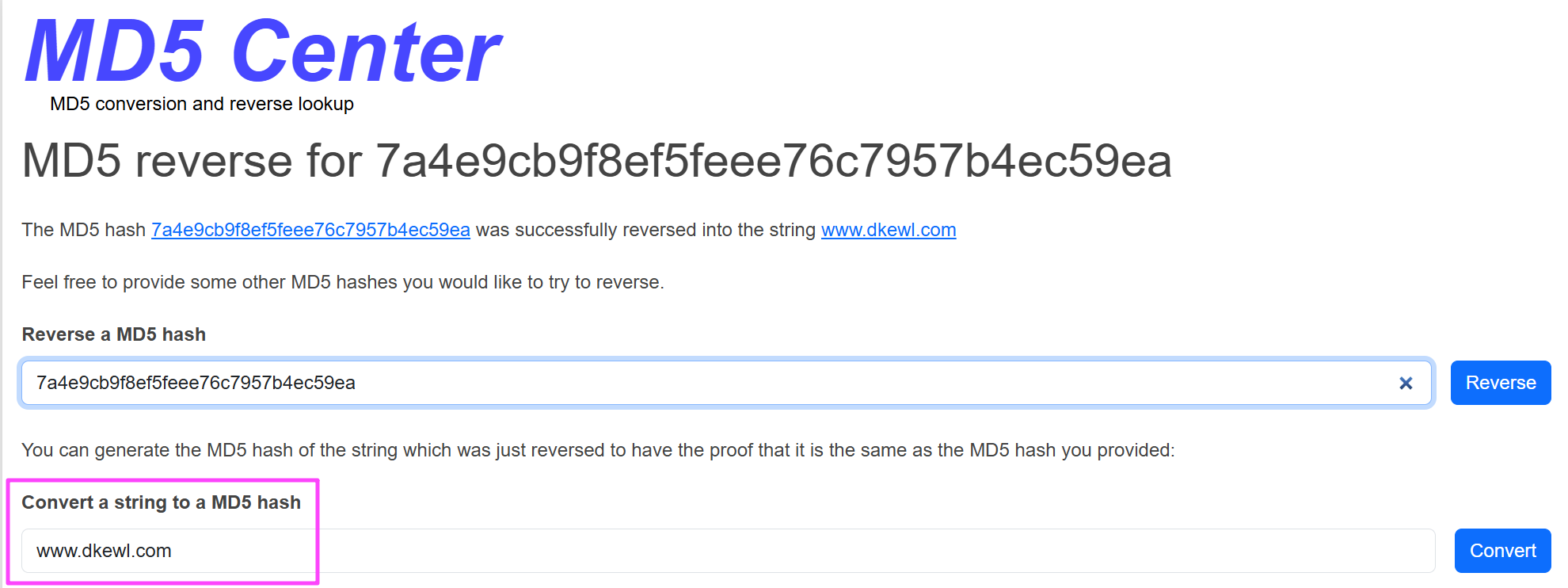
似乎没有加盐,直接就查出来了,试一下,发现能进后台。
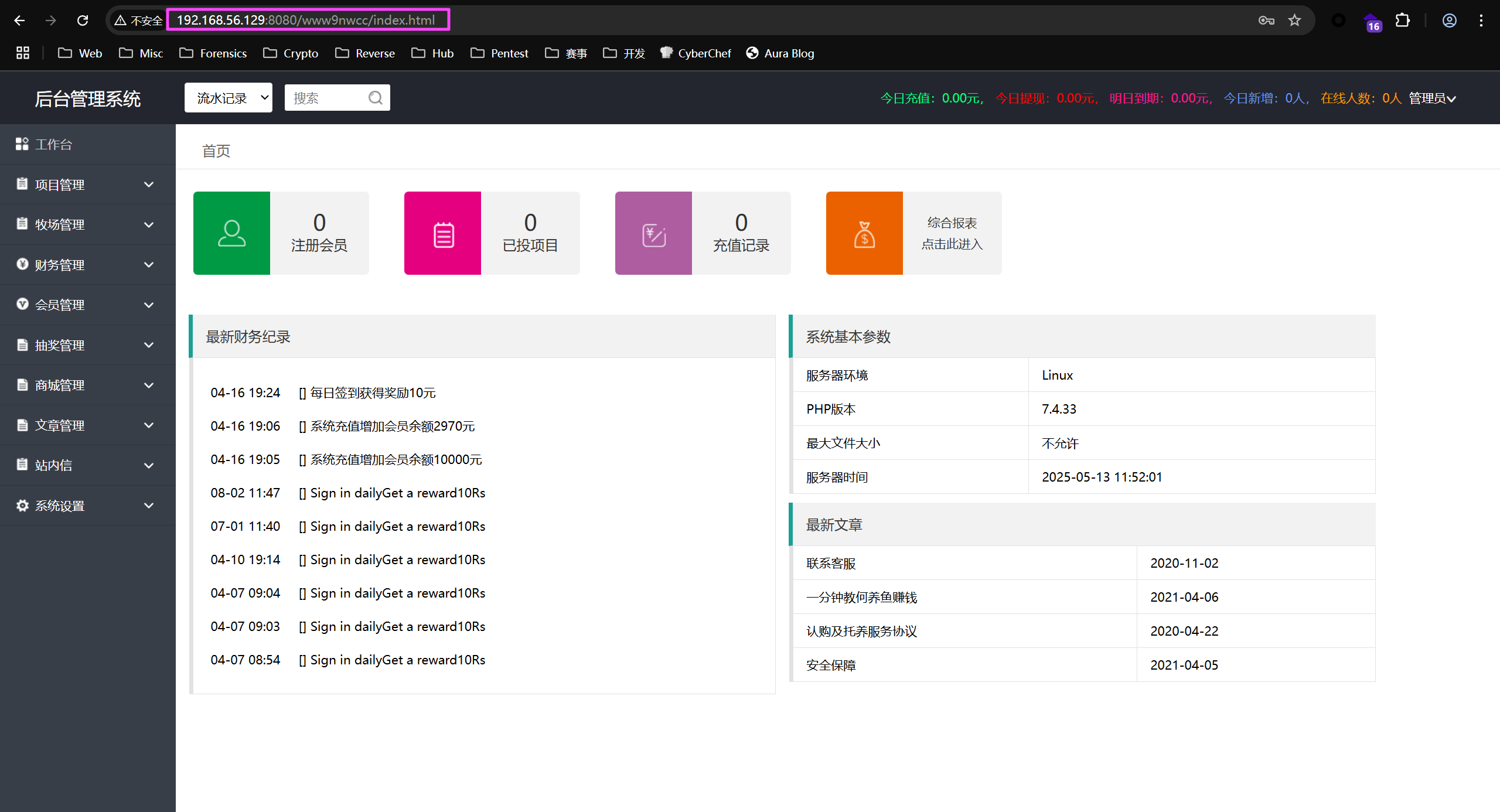
http://2025.pgscup.com:8080/www9nwcc/index.html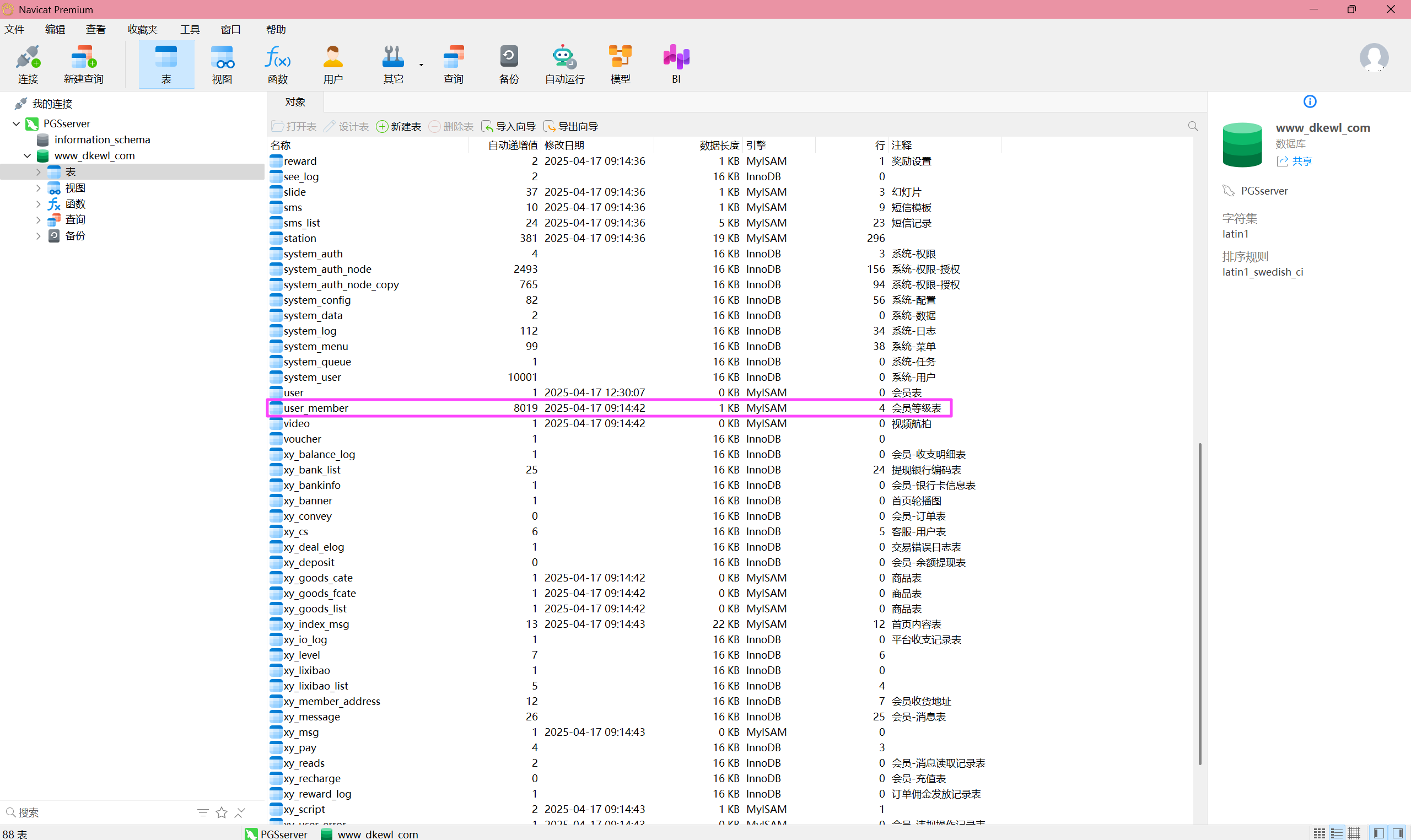
user_member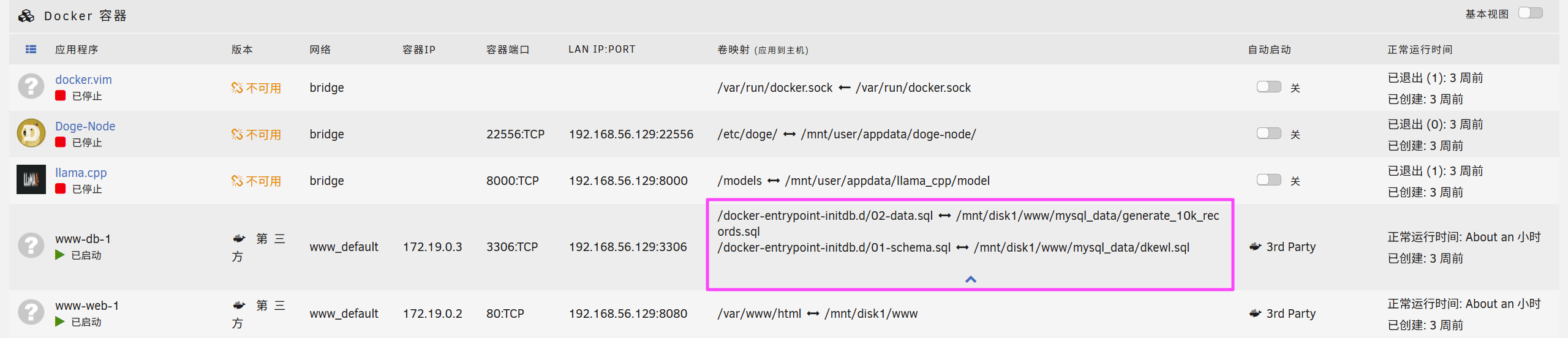
这个数据库的容器还映射了两个 .sql,直接导入进来。
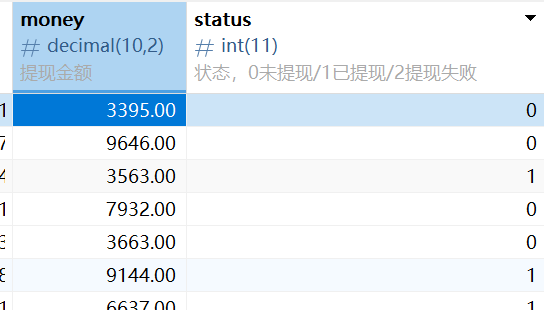
注意 1 是已提现,筛选一下。
SELECT SUM(money) FROM `cash` where status = 1;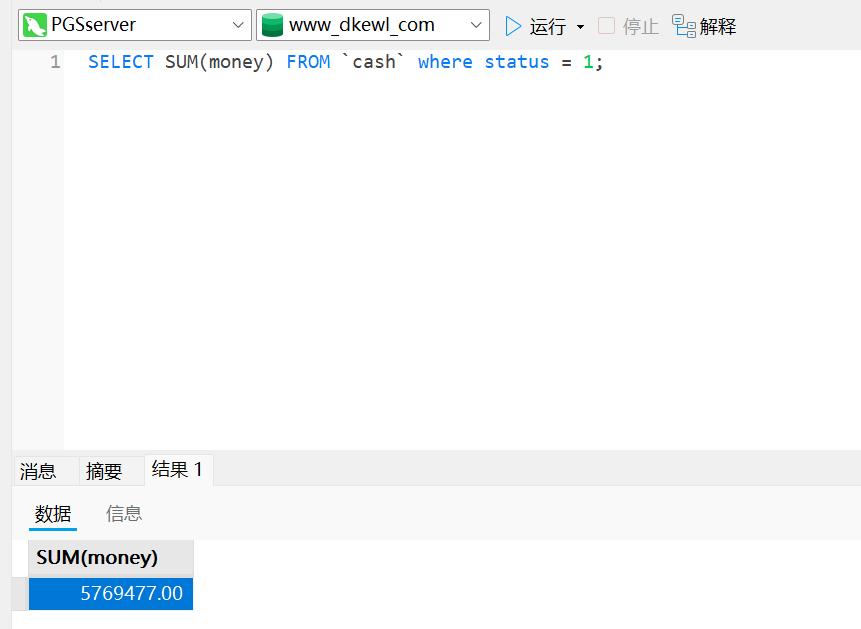
5769477SELECT * FROM `bank` where name = "王欣";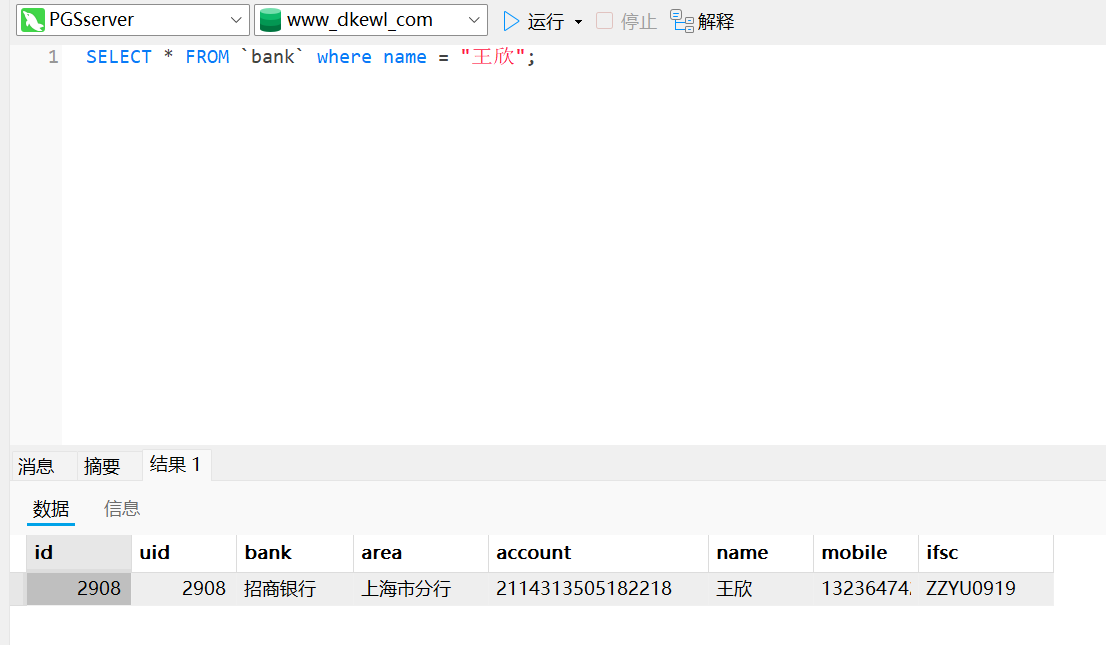
2114313505182218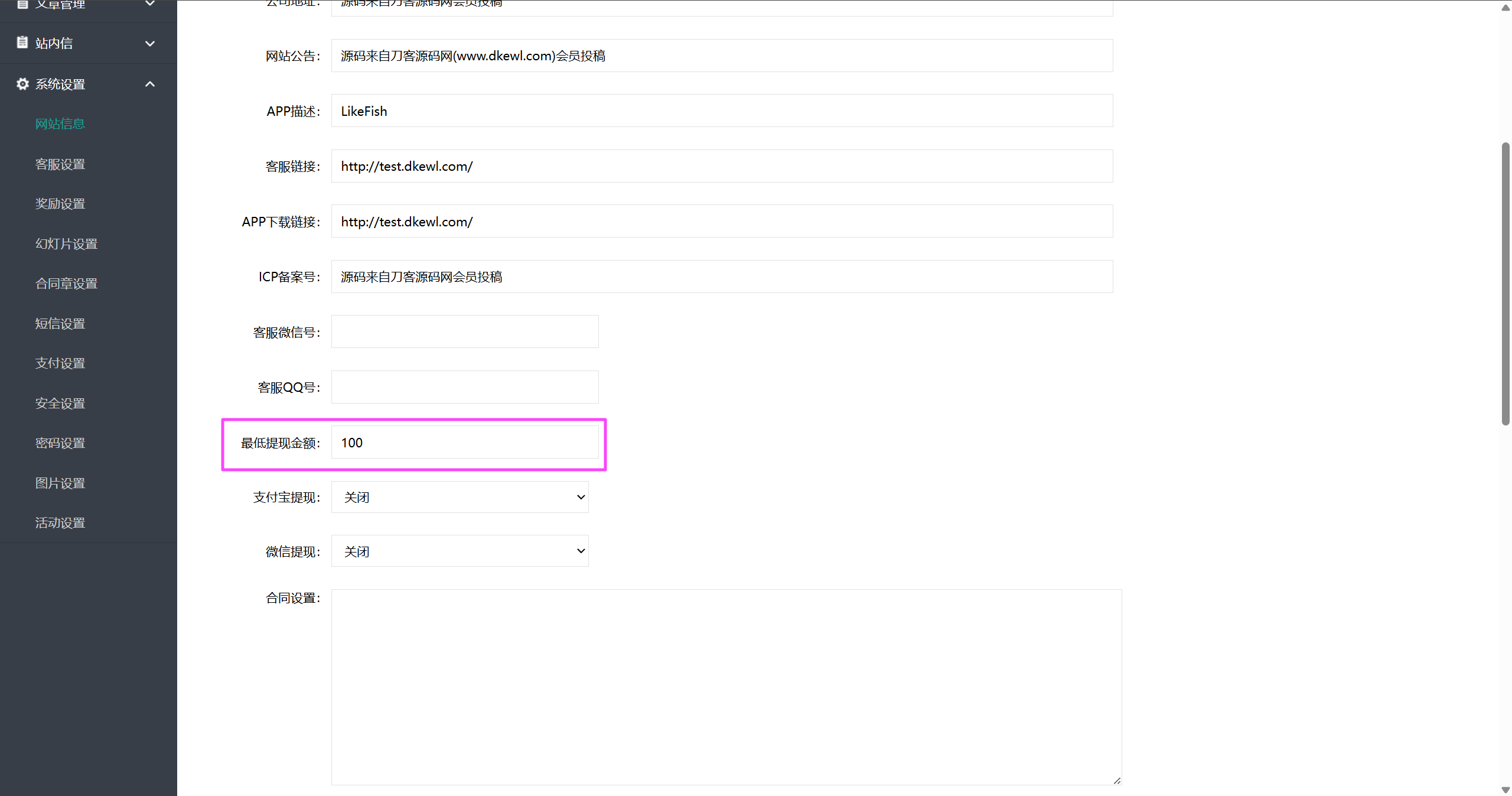
100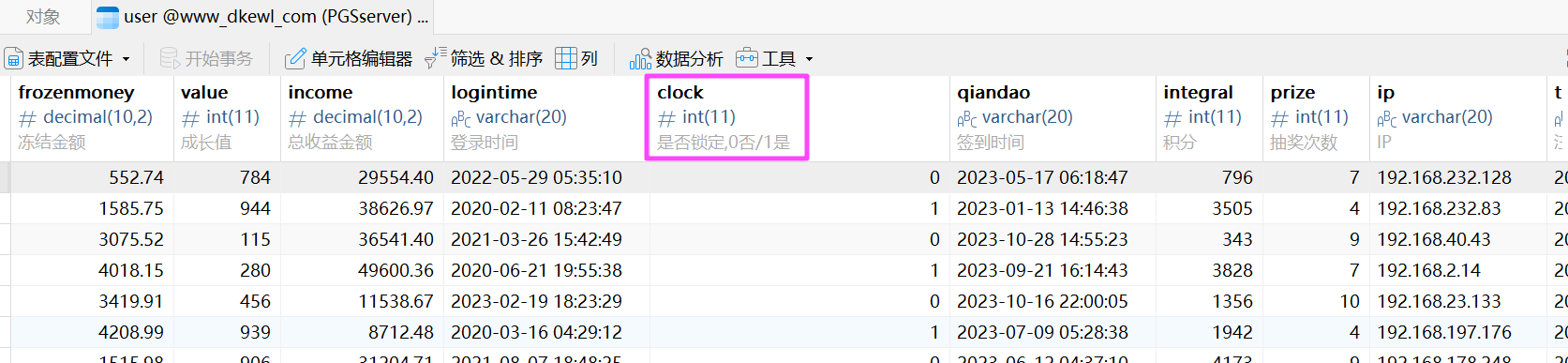
模棱两可,去后台看看会员列表确定一下。
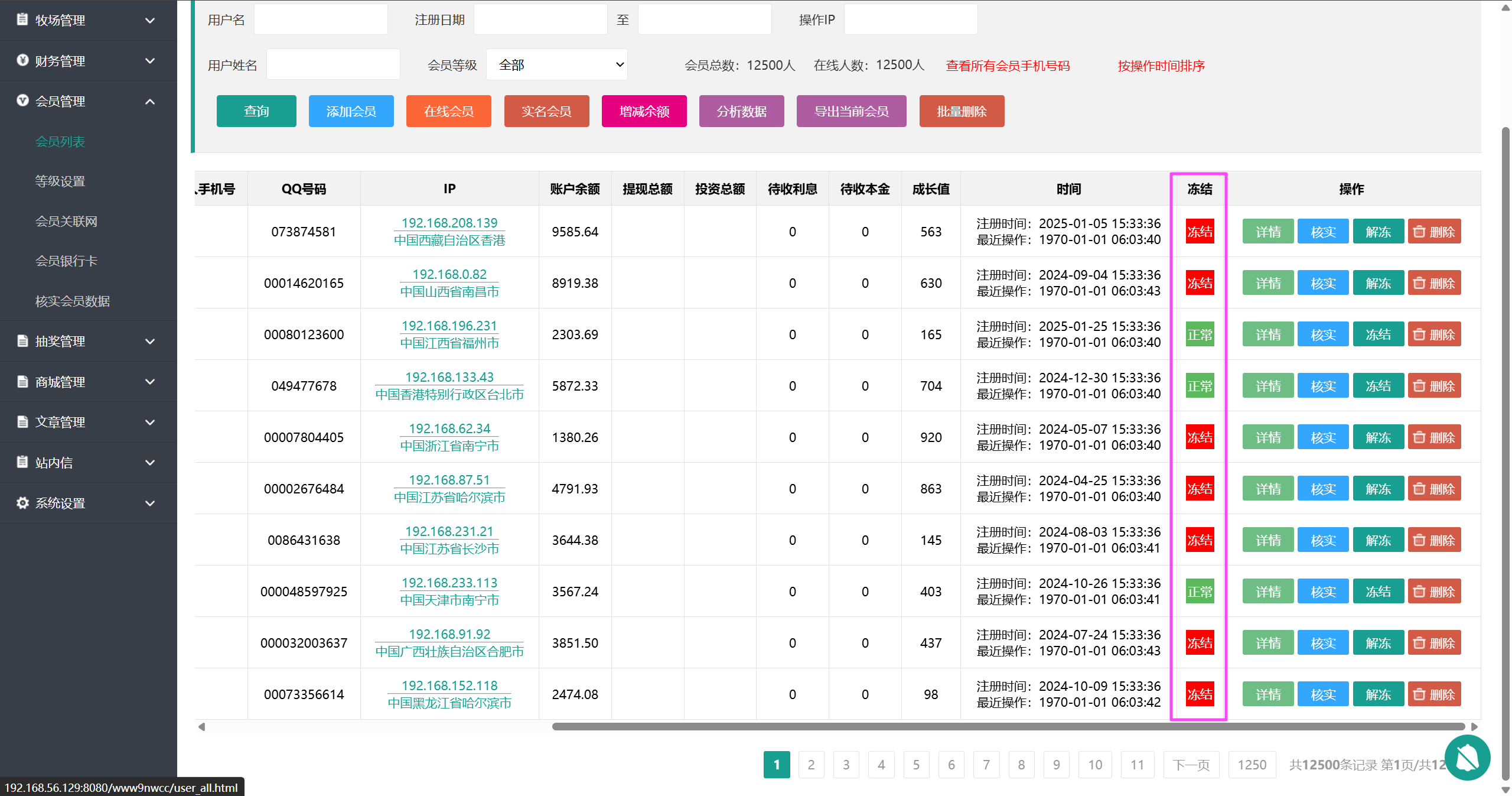
对应的是冻结这个字段,0 就是正常。
正常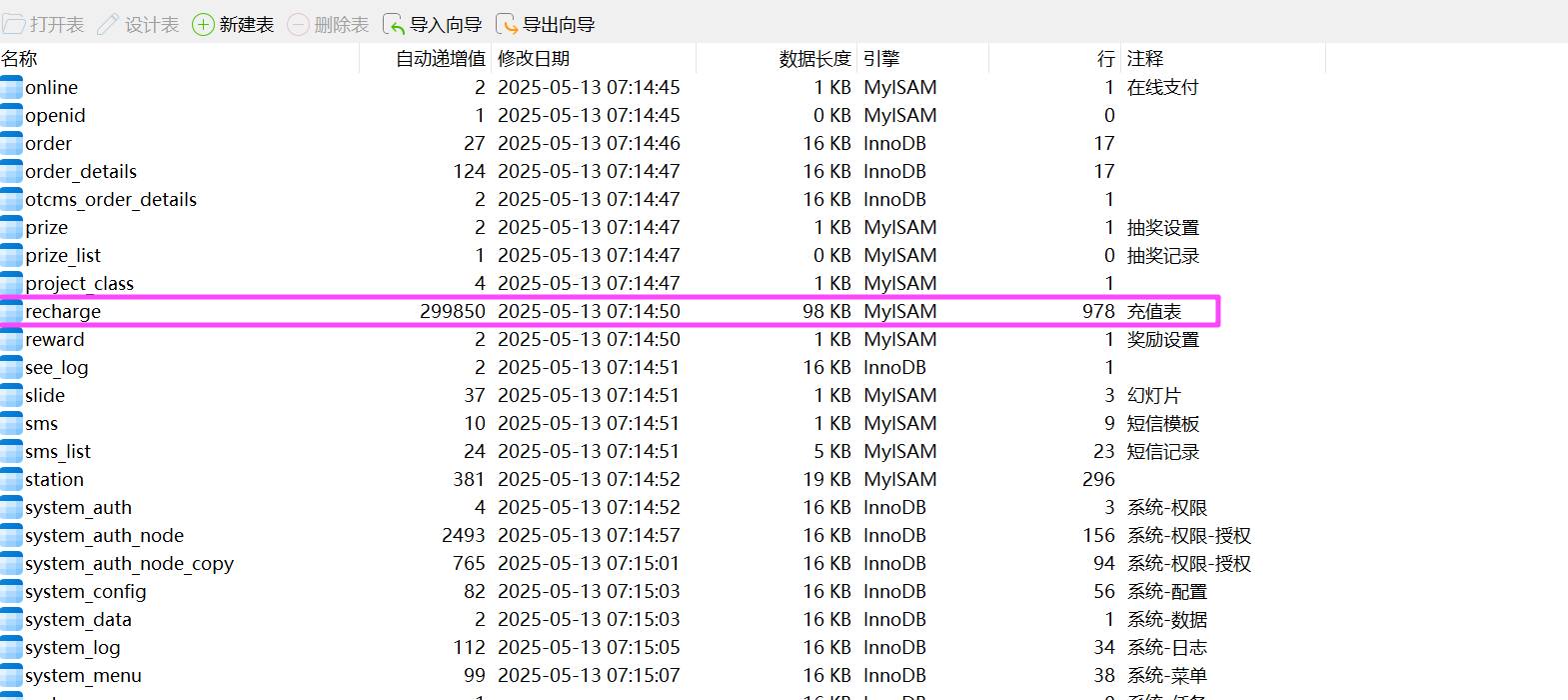
充值表是这个 recharge。
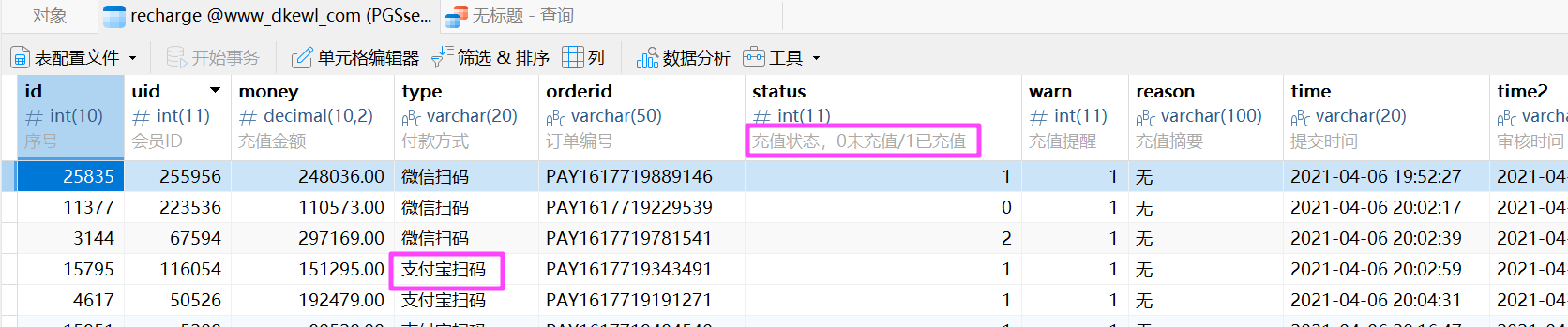
把 status 为 0 和支付宝扫码的都提取出来。
SELECT SUM(money) FROM recharge WHERE type = "支付宝扫码" AND status = 0;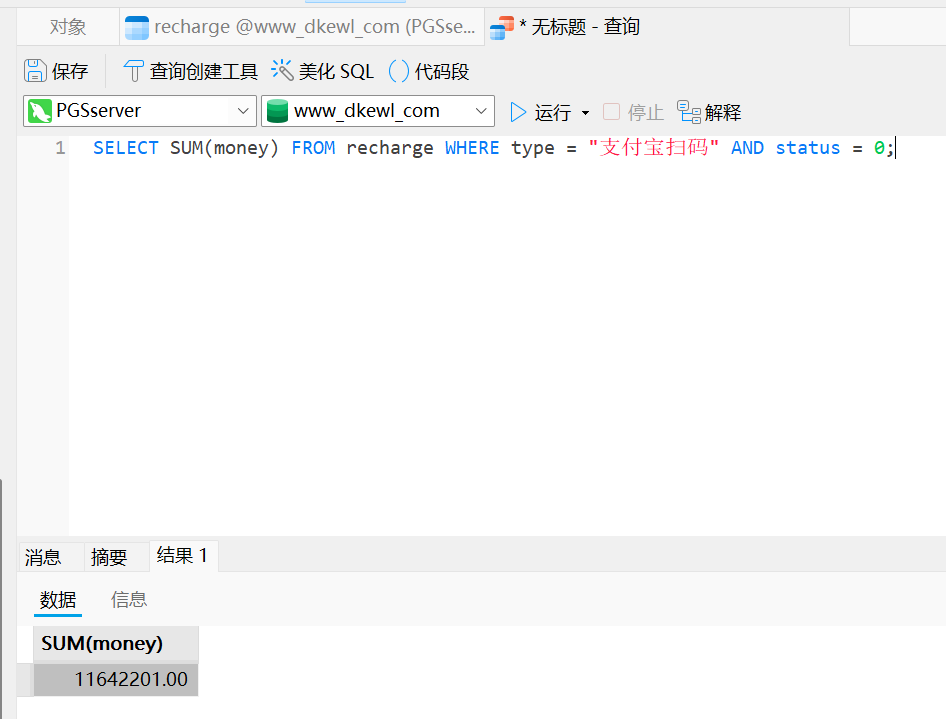
11642201
要密码,不知道。
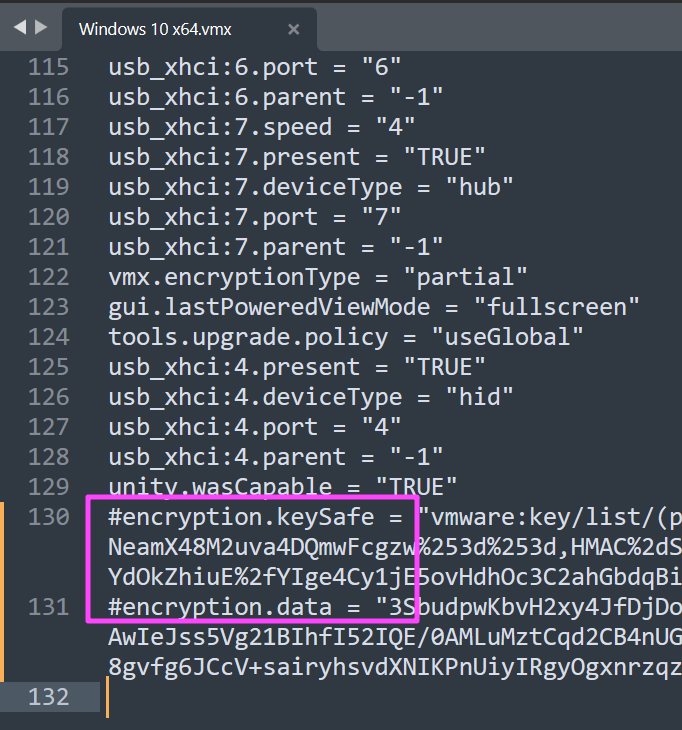
这里有两条路,第一条是用之前的掩码爆破爆出来密码,第二条是直接注释掉 vmx 的最后两行,直接绕过。
这里选择第二条路。
密码 123456。
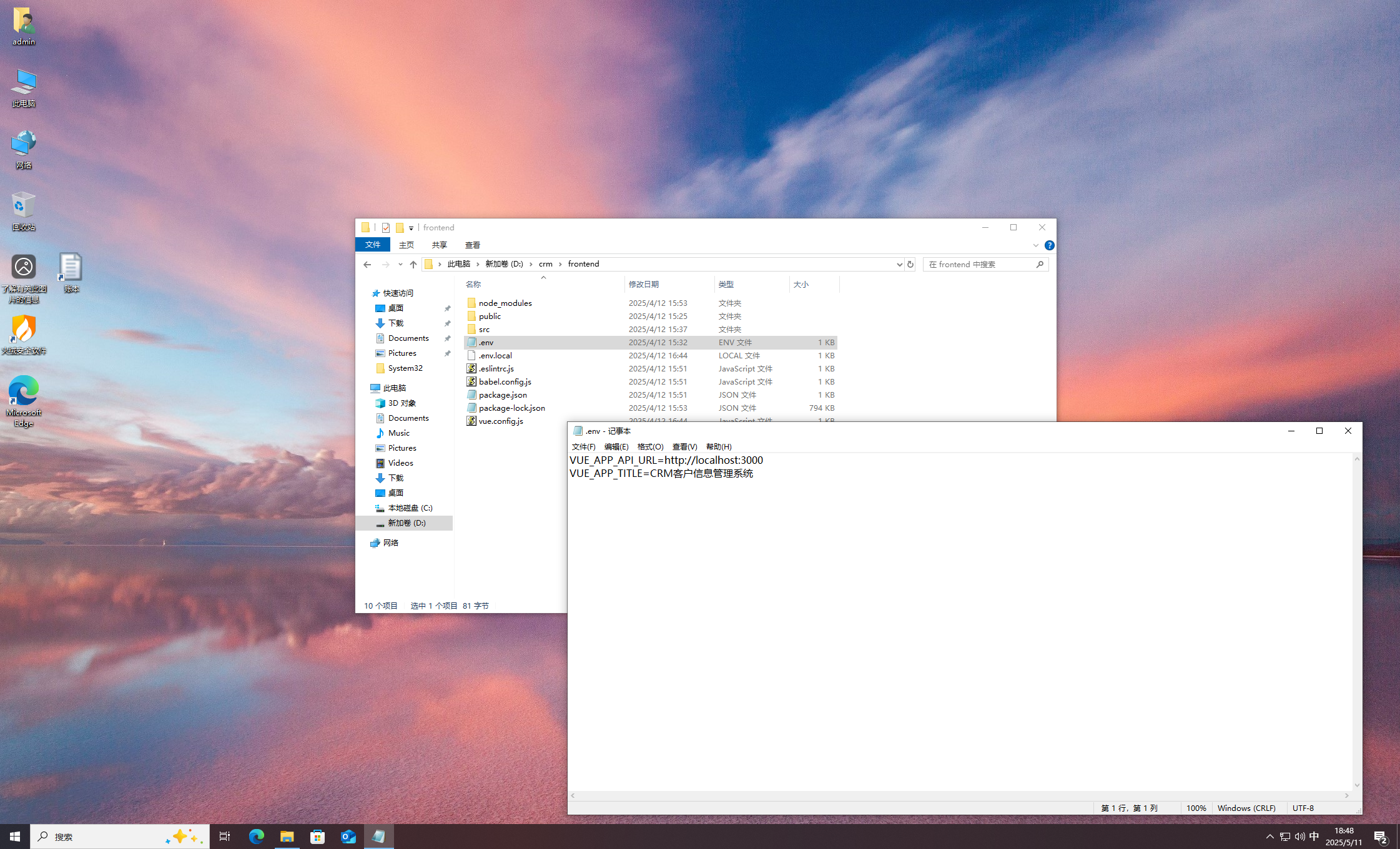
Vue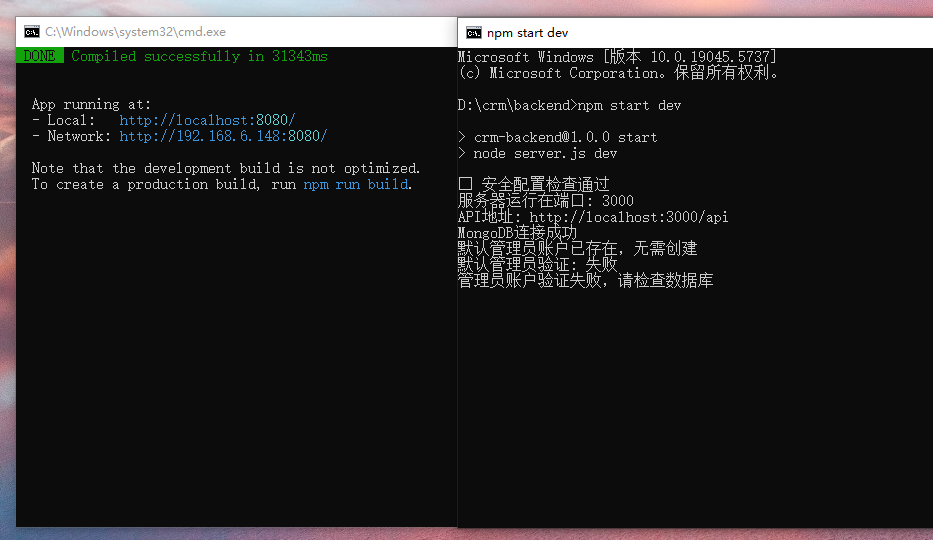
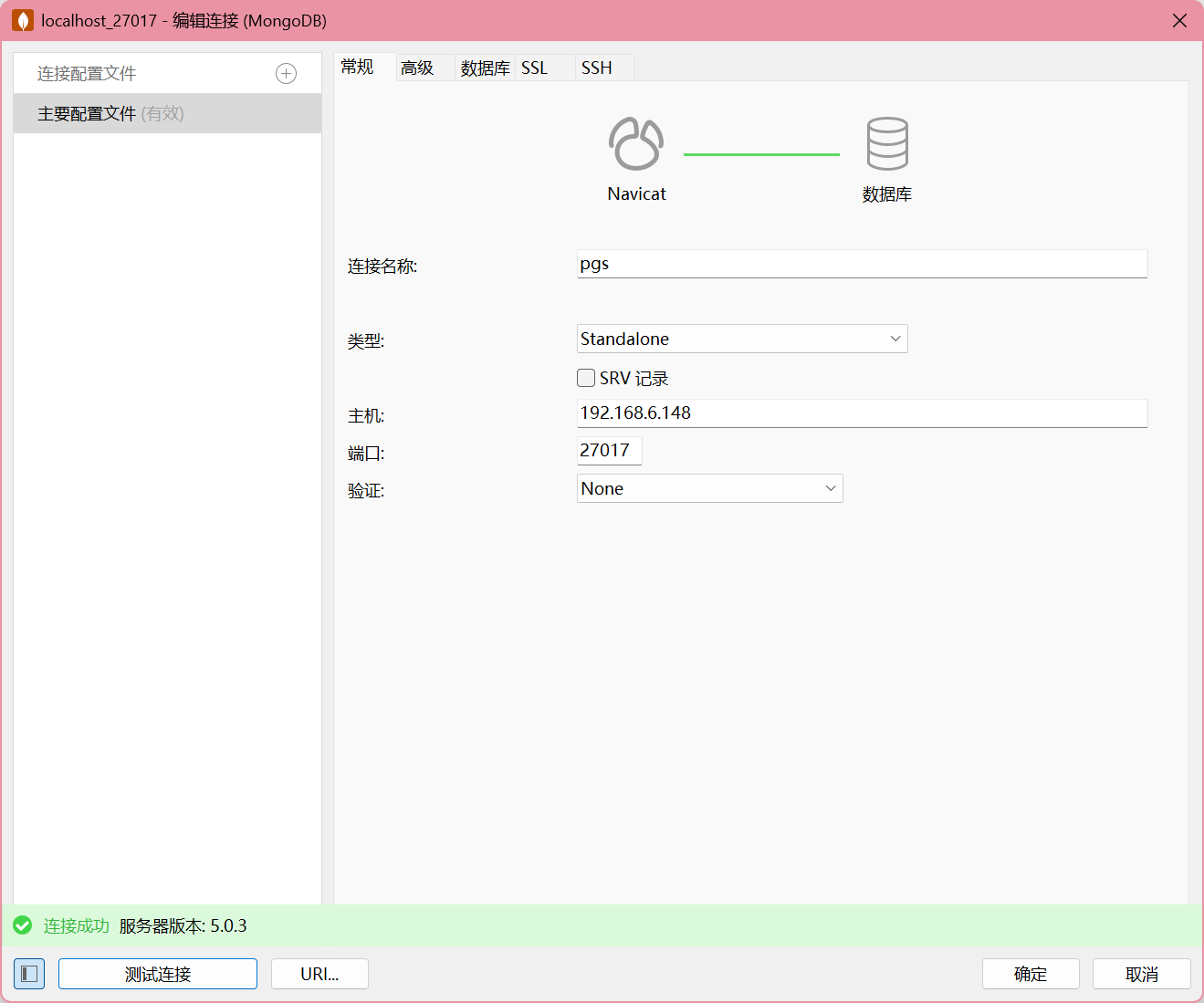
发现数据库是 MongoDB,去安装路径看看。
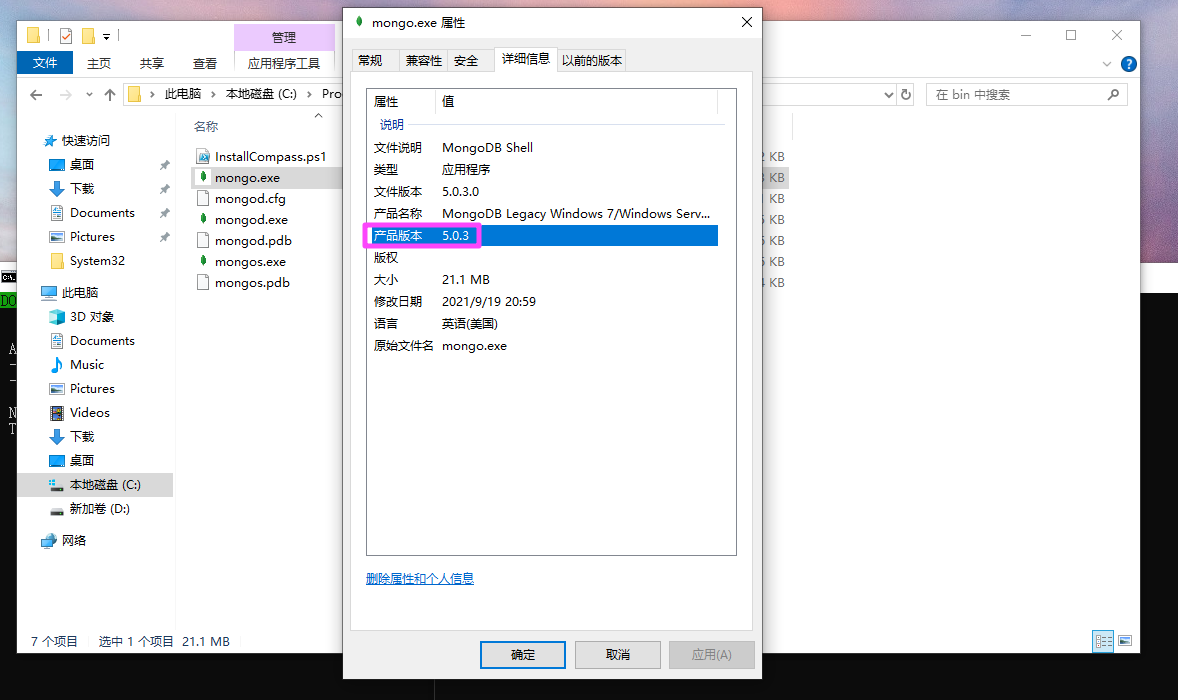
5.0.3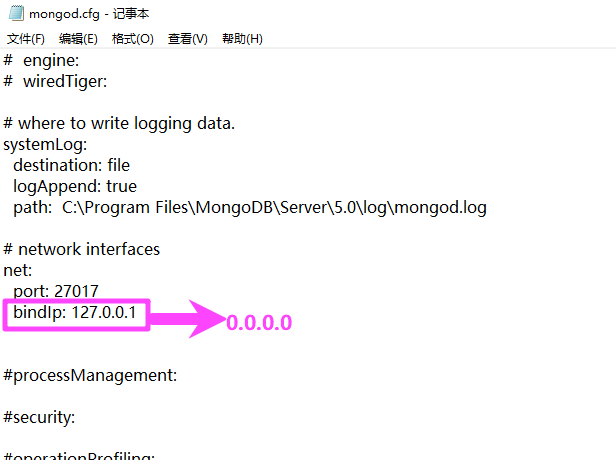
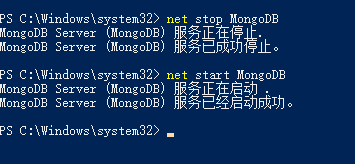
修改后重启服务。
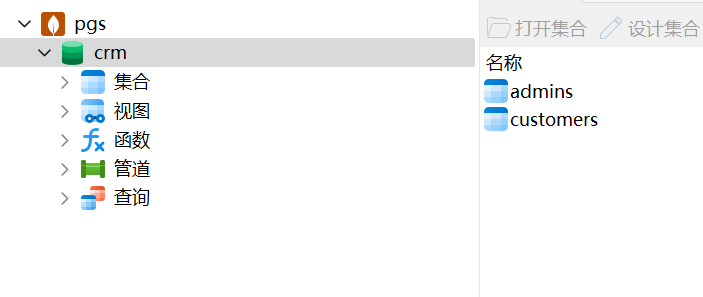
crm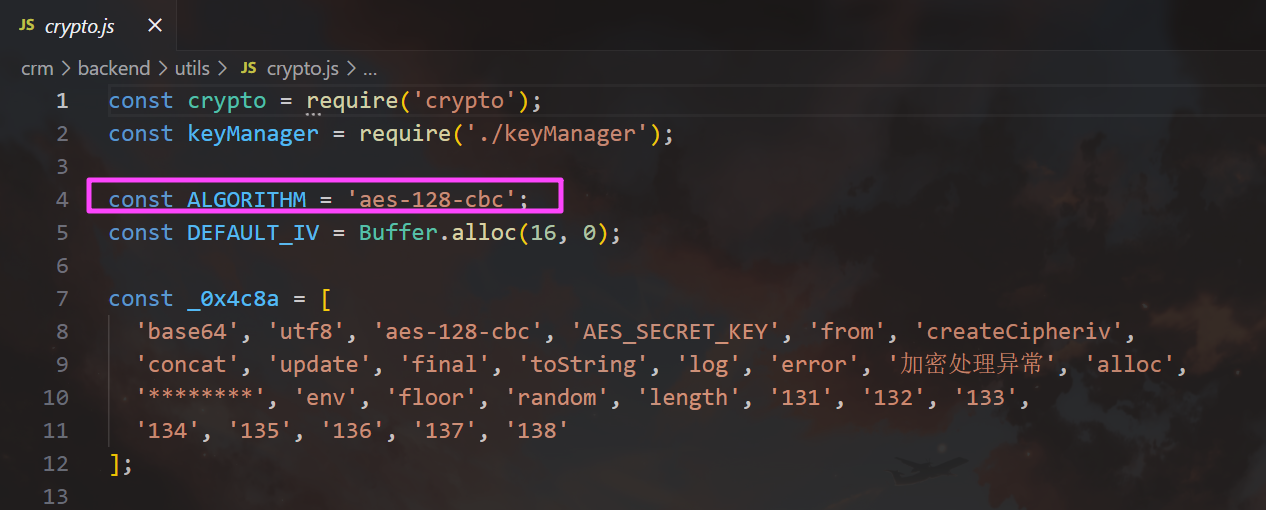
aes-128-cbc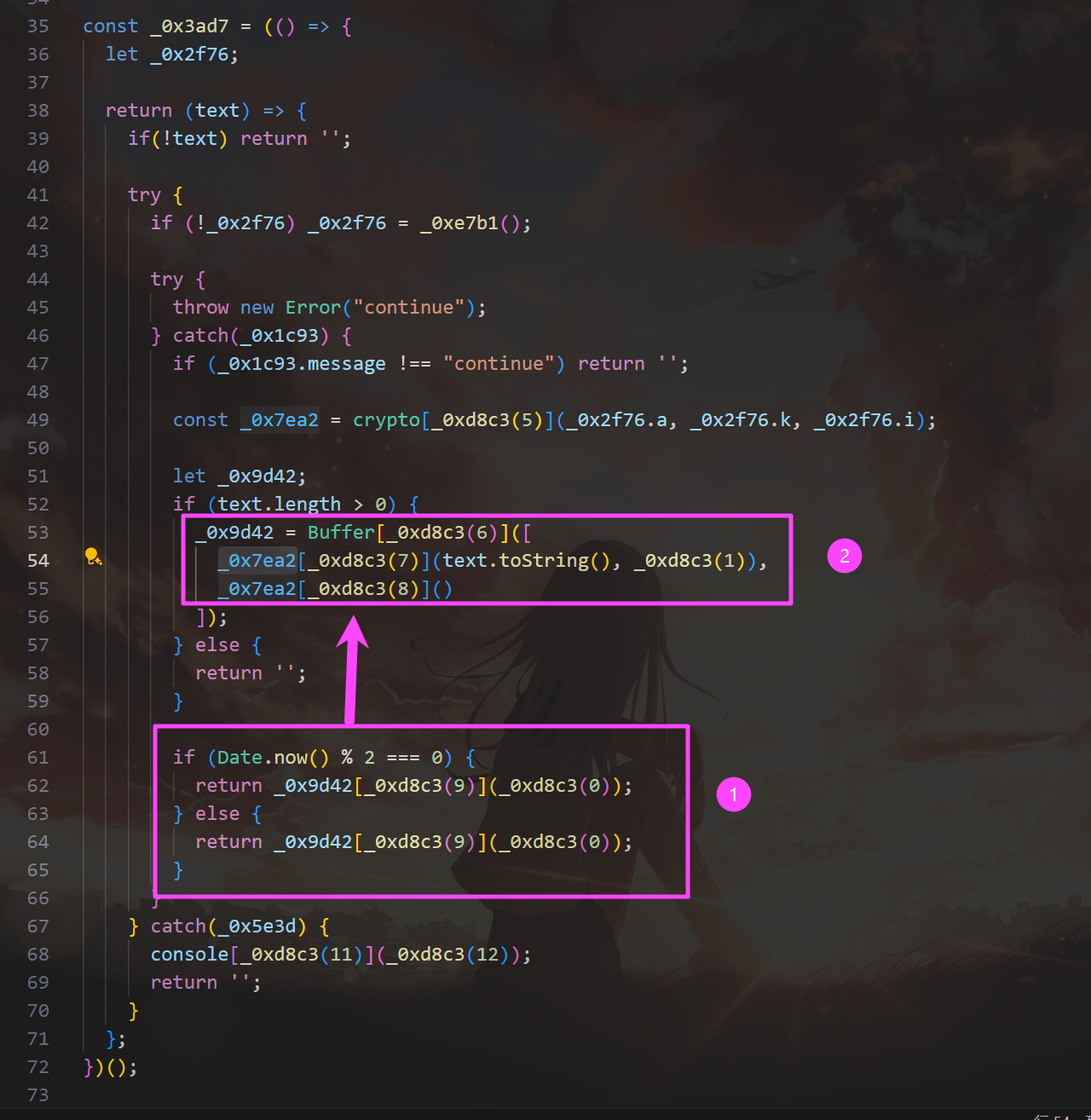
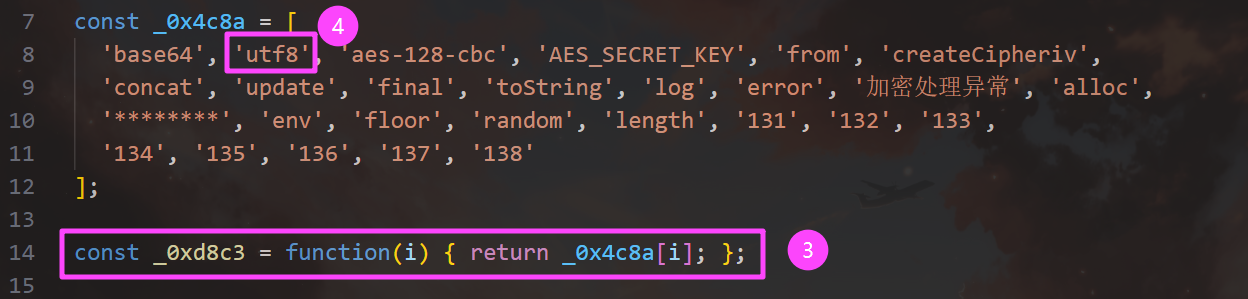
_0x4c8a 中索引为 1 的是 utf8。
utf8谜语人,没看懂在问什么。
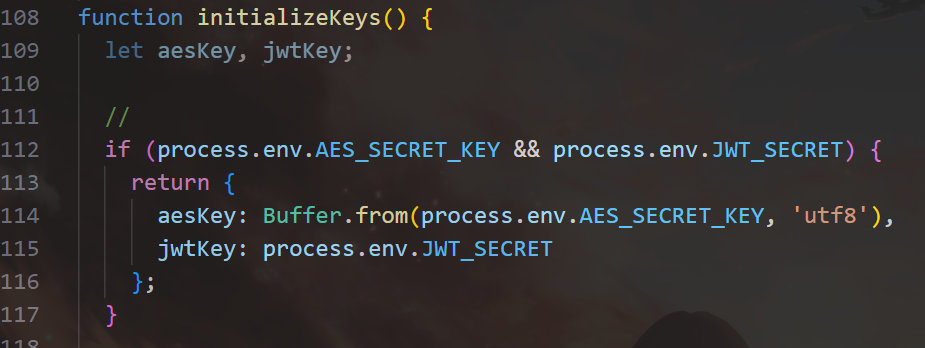
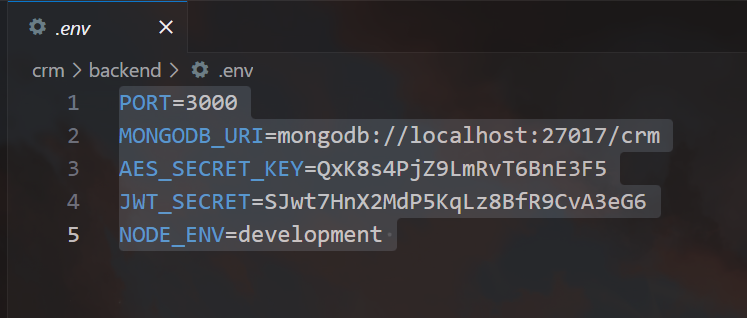
第二个也是 .env 里面的,叫 MASTER_PASSWORD,如果没有,就随机生成密钥。
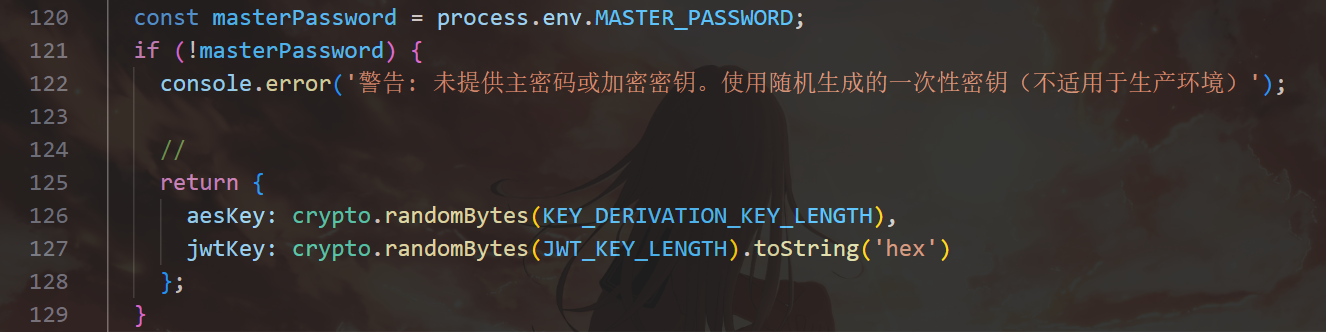
AES_SECRET_KEY>JWT_SECRET>MASTER_PASSWORD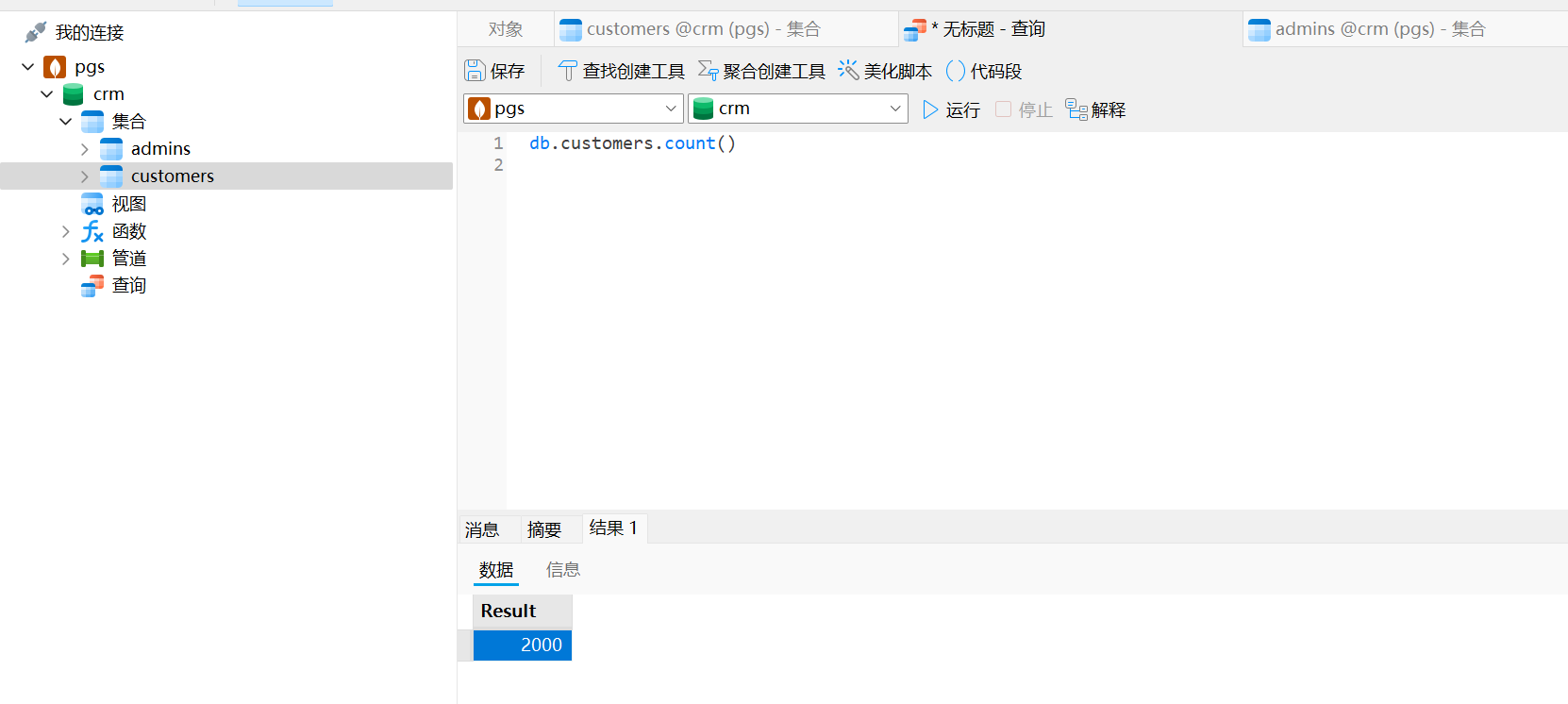
2000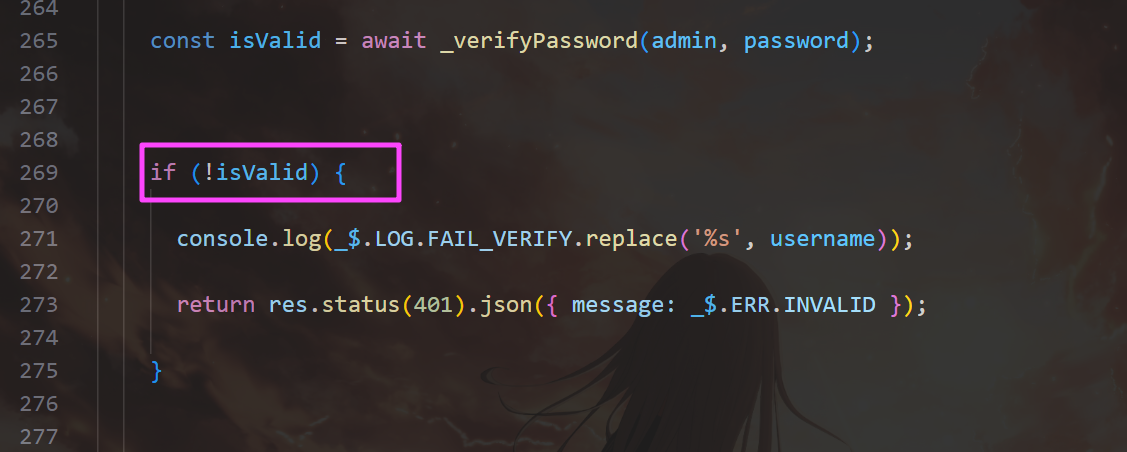
把 ! 去掉,这样可以任意密码登录。
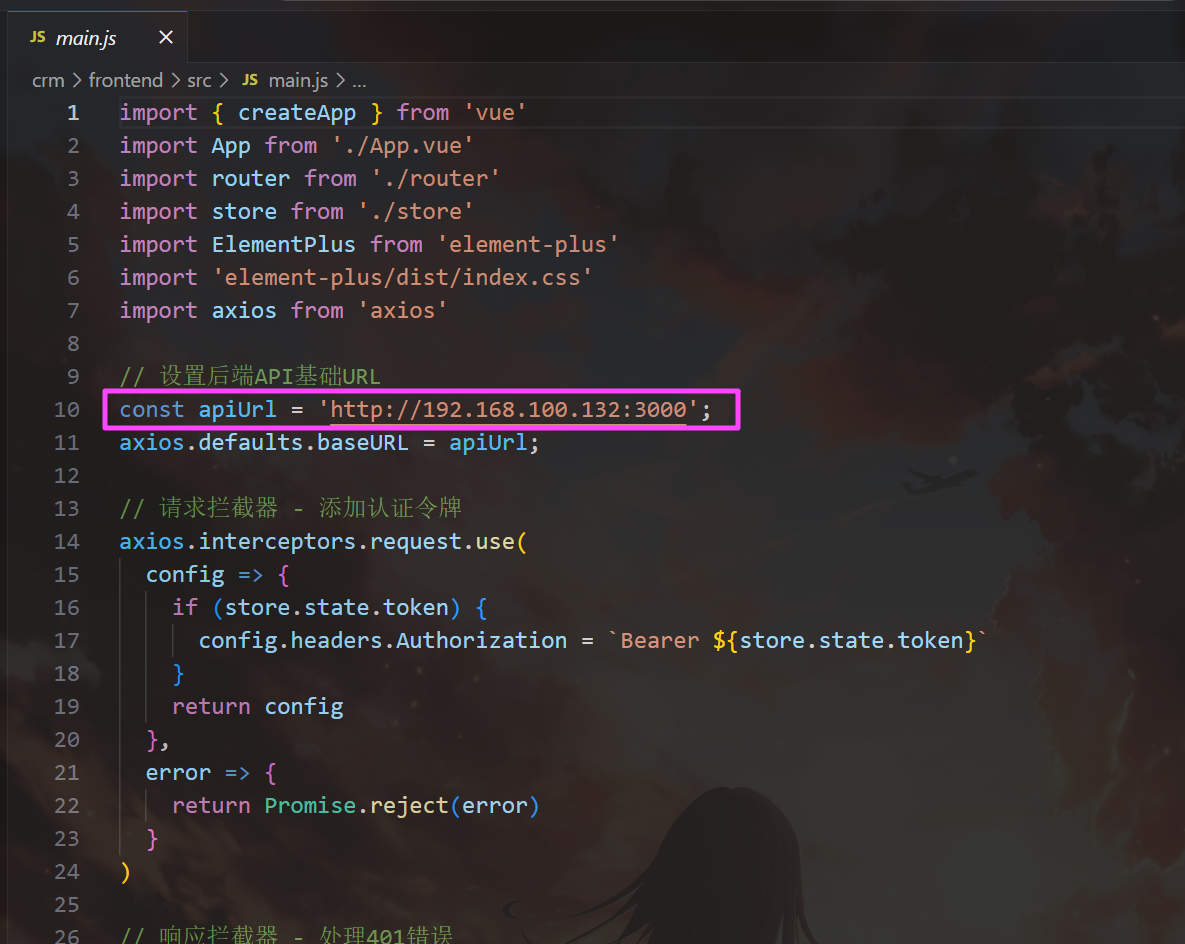
把这个改成 127.0.0.1,这样可以连接到数据库。
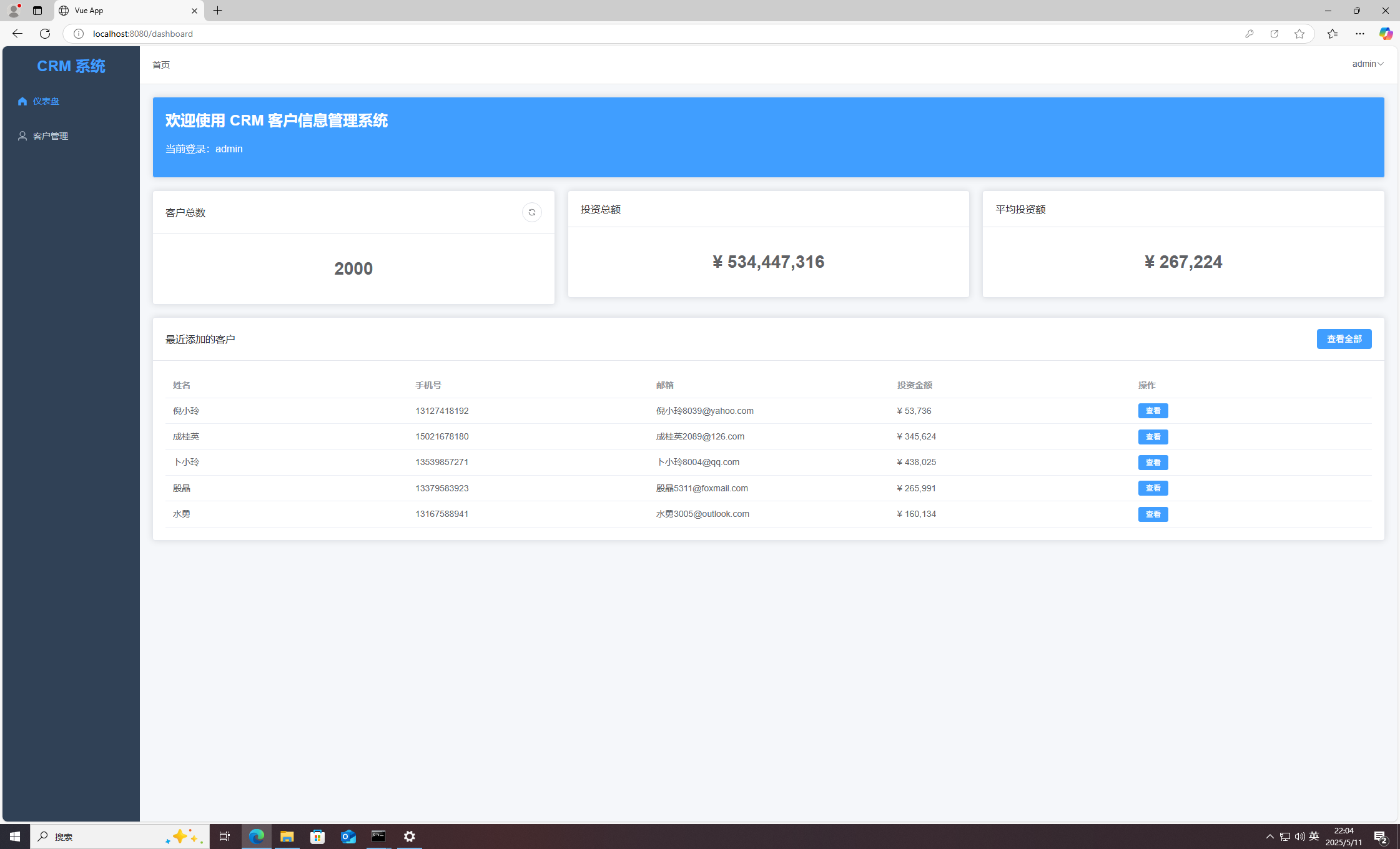
成功进入后台,现在去搜索身份证号。

没有,尝试把指定的身份证号按照加密规则加密,然后丢到数据库里面查,也没查到。
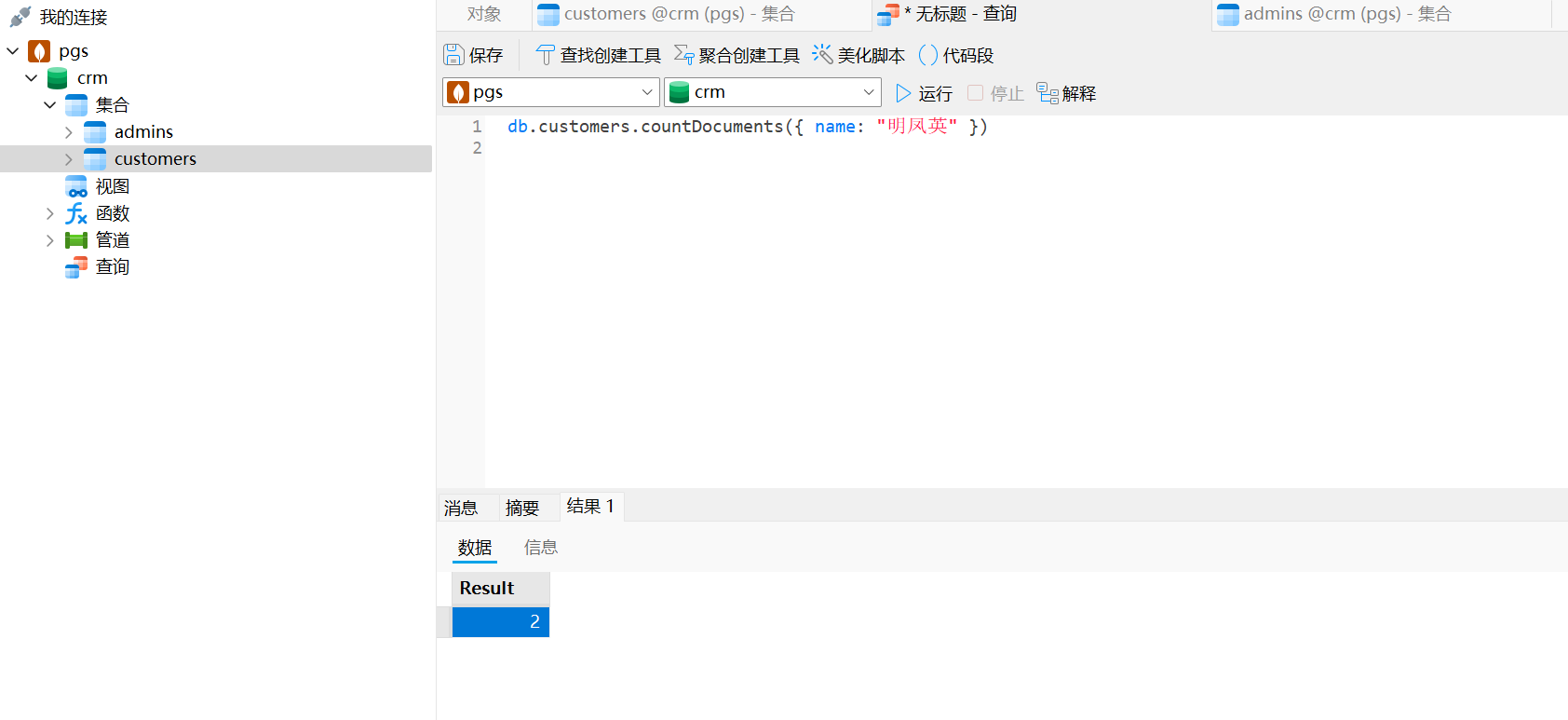
2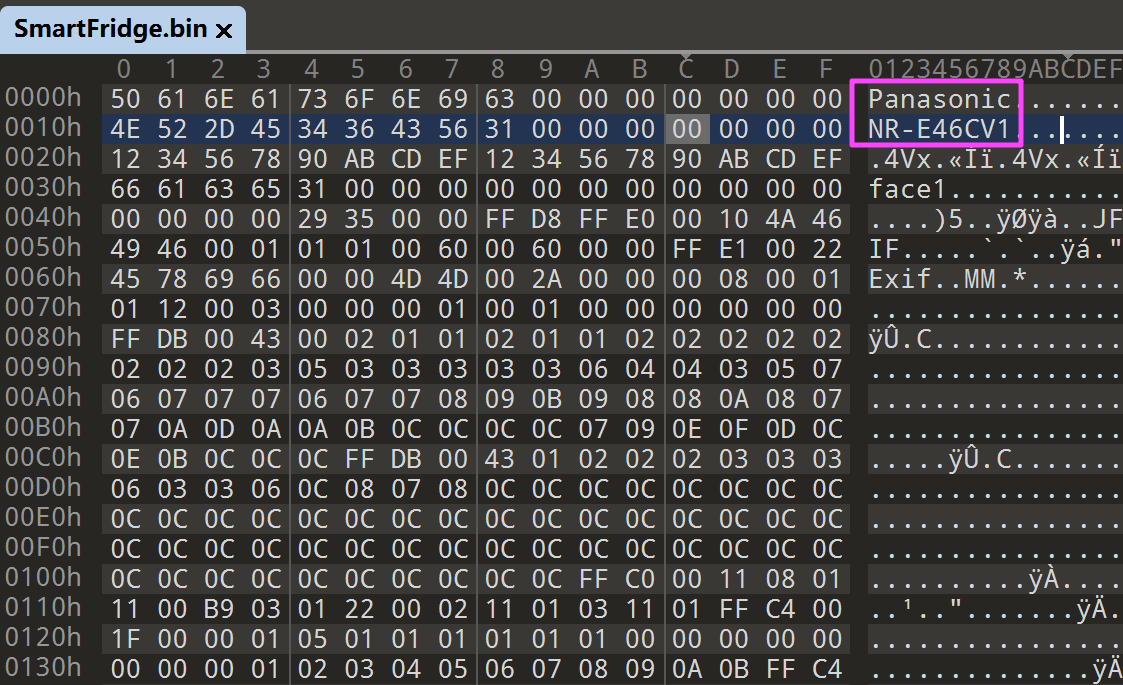
PanasonicNR-E46CV1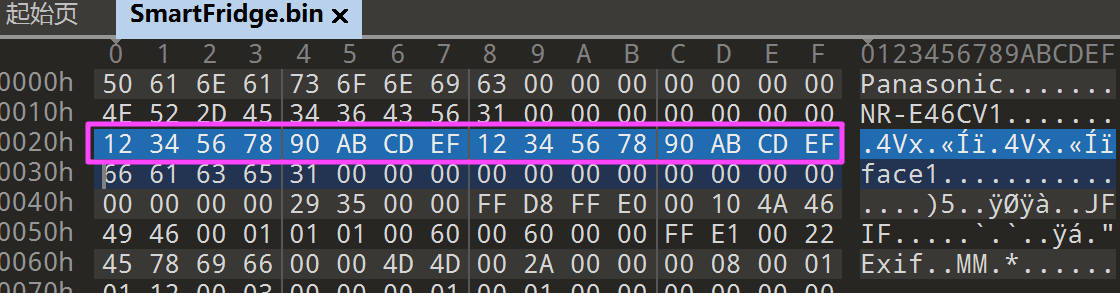
12345678-90ab-cdef-1234-567890abcdef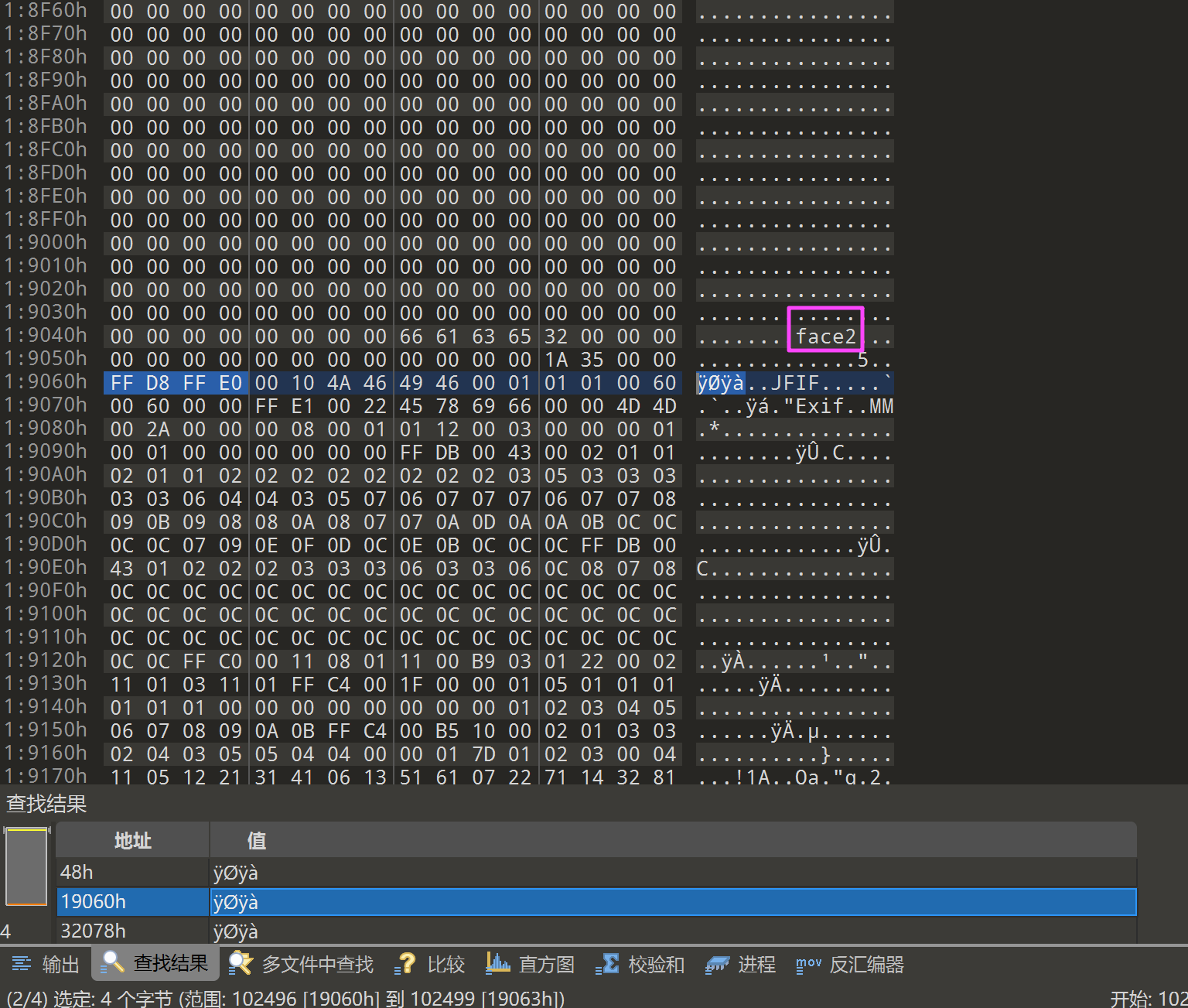
发现基本上每张图片前都有一个 face(n),去搜一下 face。
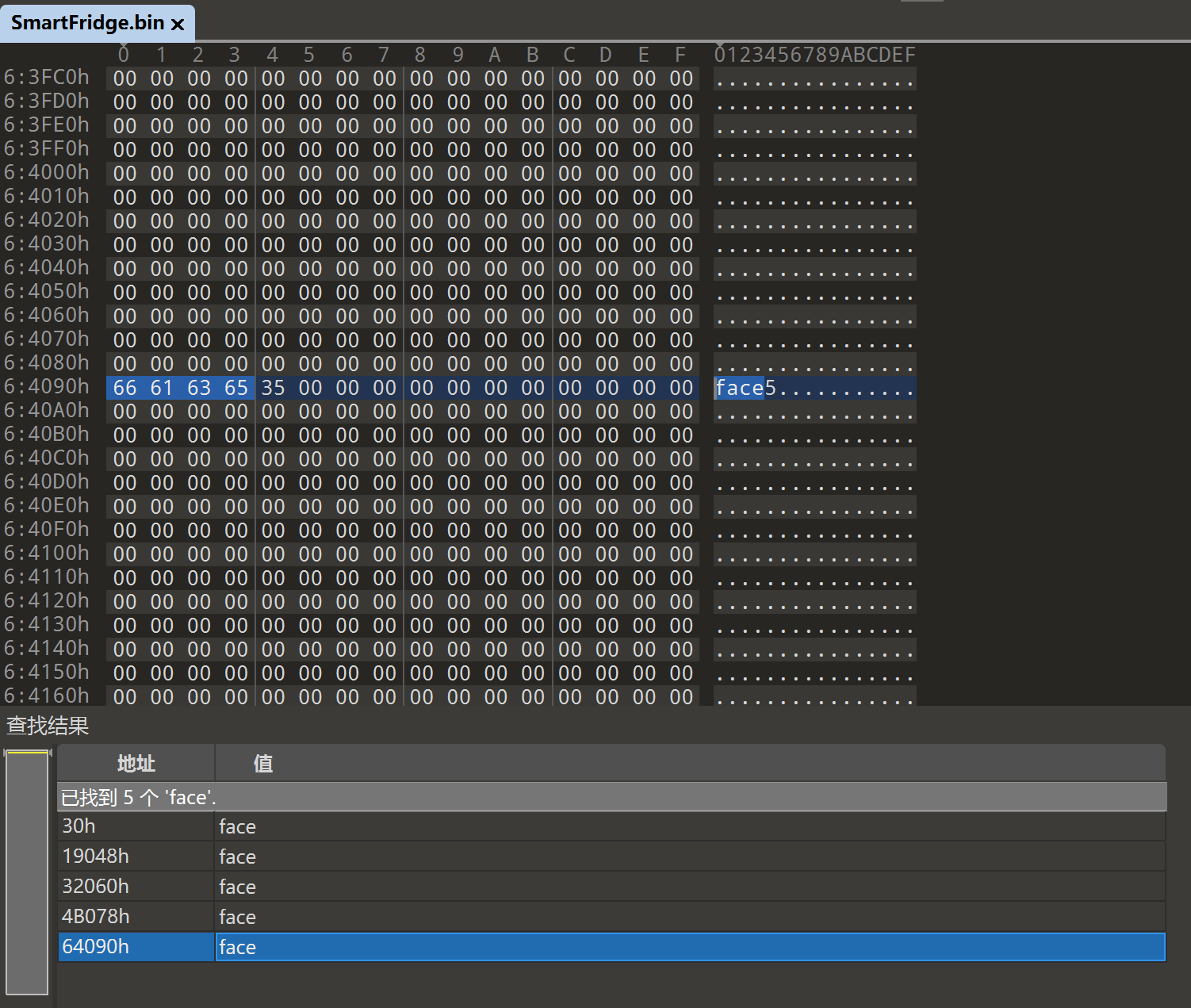
一共有五个,这种可能是开冰箱的时候所保存的图片,符合本题要求。
5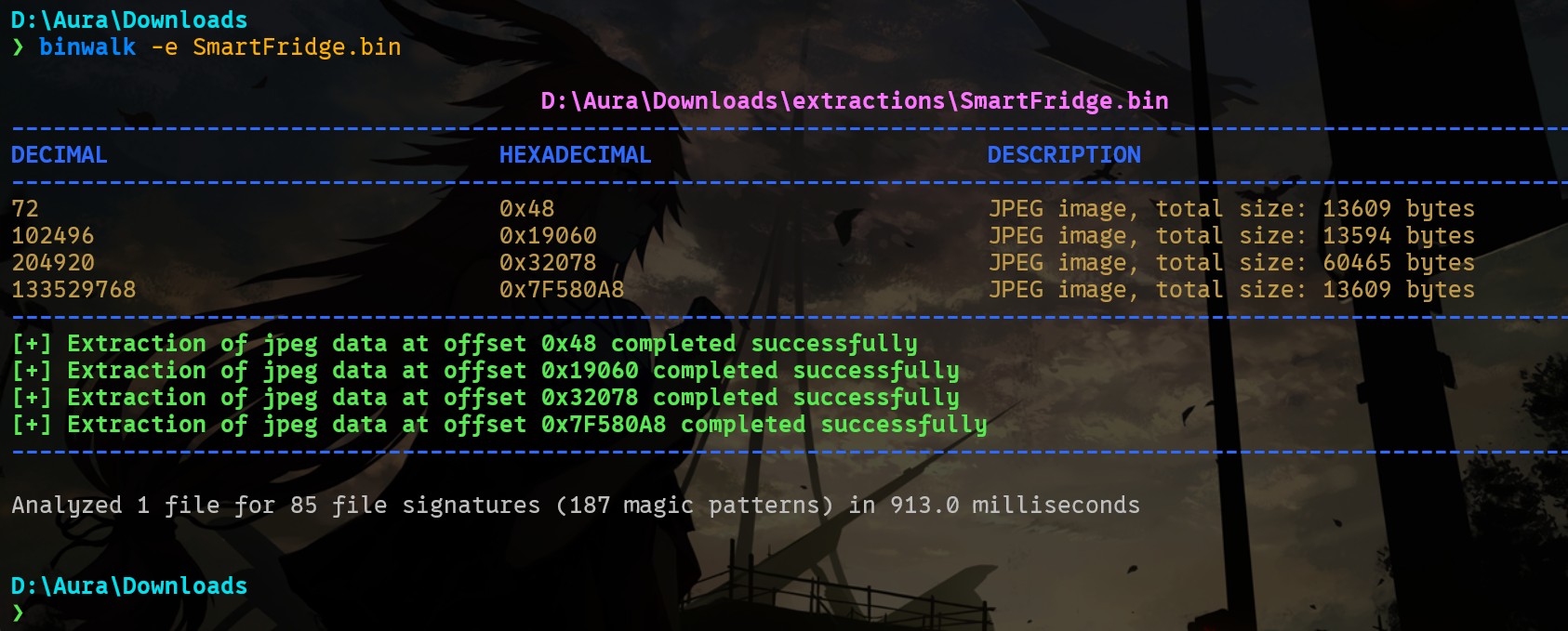
一共 4 张图片,全部提取出来。

这是第一张,写了 “盘古石杯贾韦码”。
盘古石杯贾韦码face2.jpg
pangushicup
答案就是这张图的 MD5 值的后六位。
882564之前在苹果电脑中解密了 贾韦码资料.rar.enc,解压出来一个 face1.jpg 和 资料.docx,这个 face1.jpg 很明显和冰箱有关,就是冰箱保存的图片,这个图片的修改时间就是冰箱开门的时间。

15:48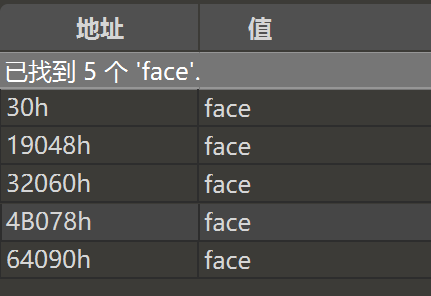
计算一下相邻 face 之间地址相差了多少,发现是 102400 字节,也就是 100 KB。
100KB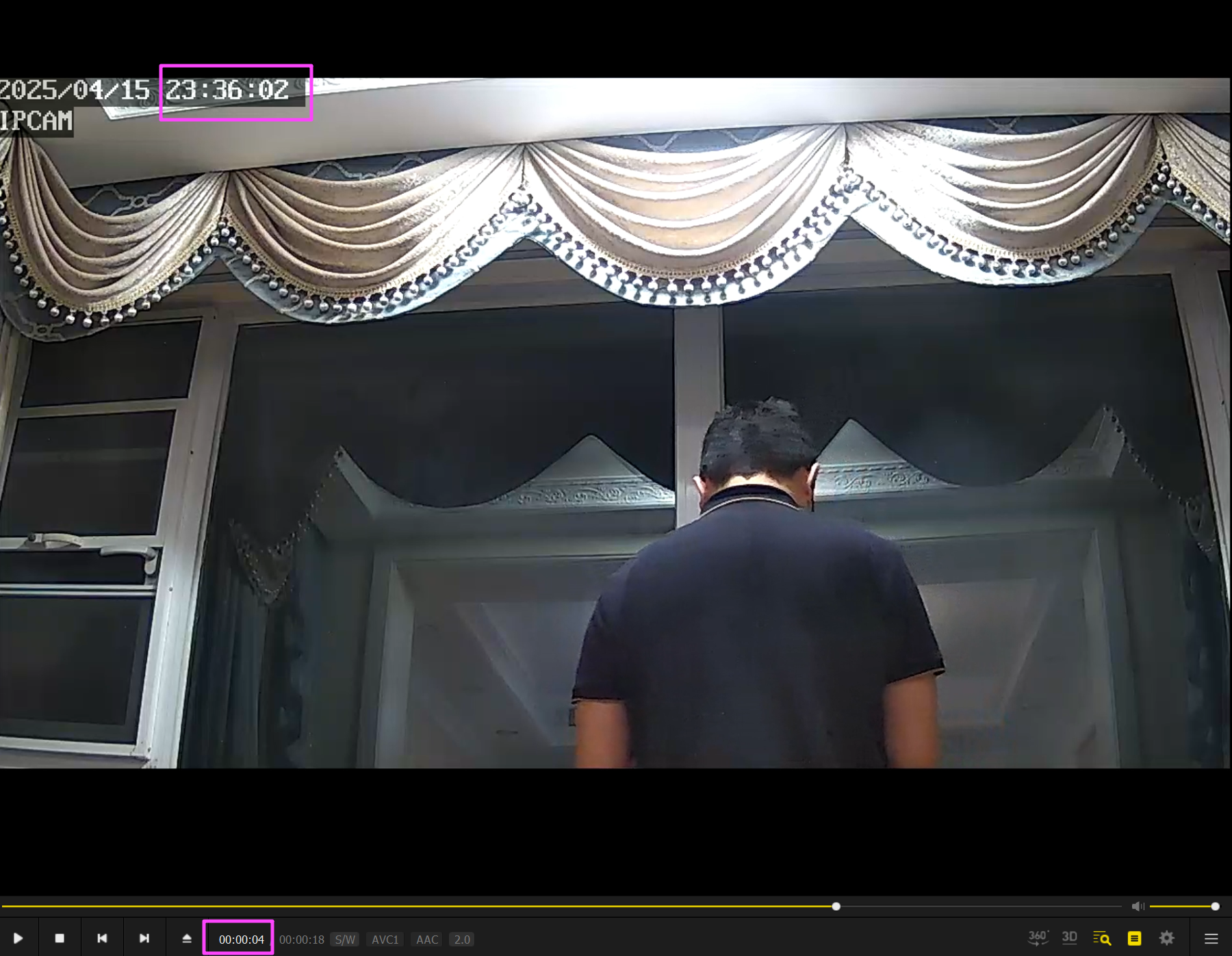
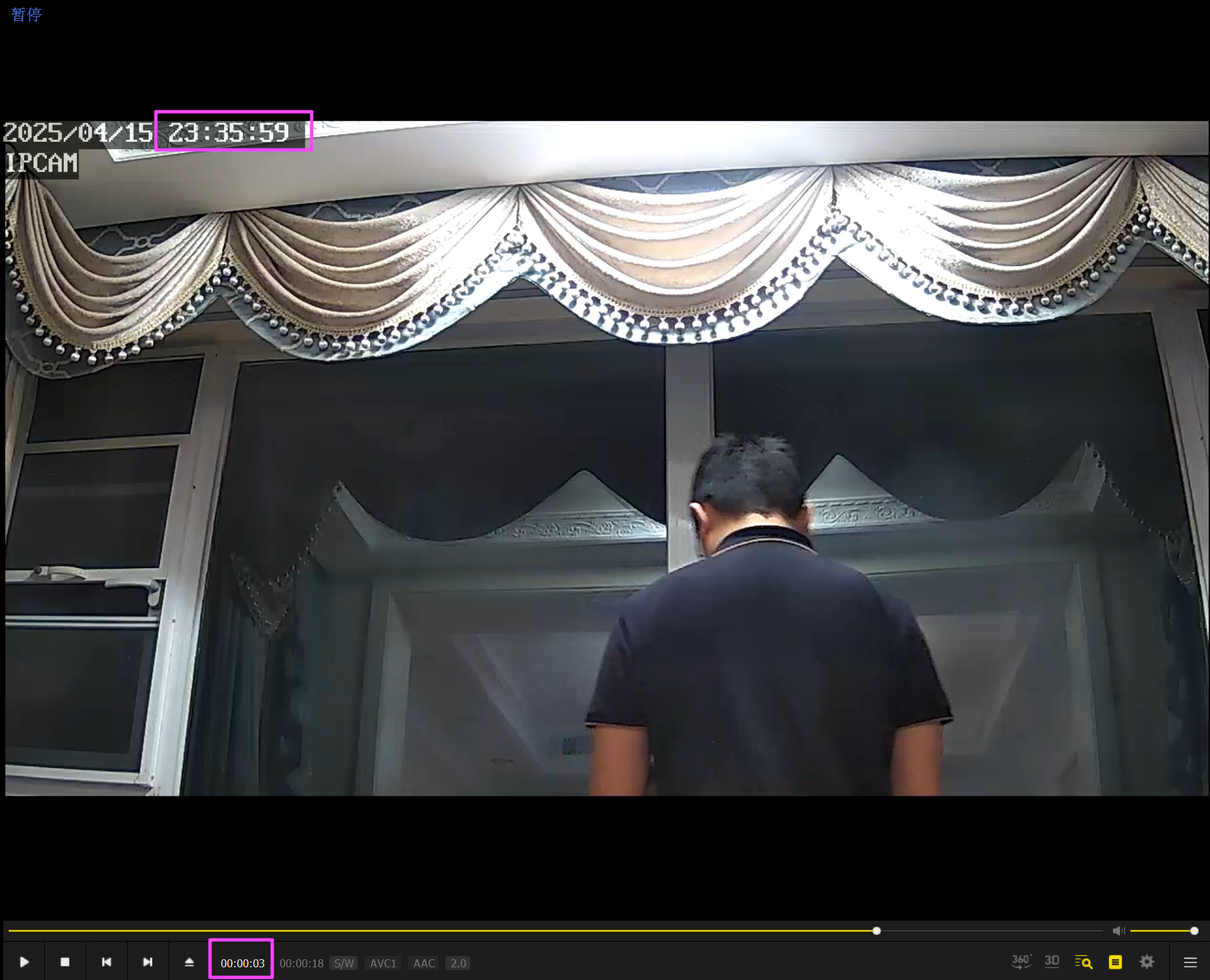
(PotPlayer 左下角显示的是距离播放结束剩余的时间,如果不理解那就看进度条)
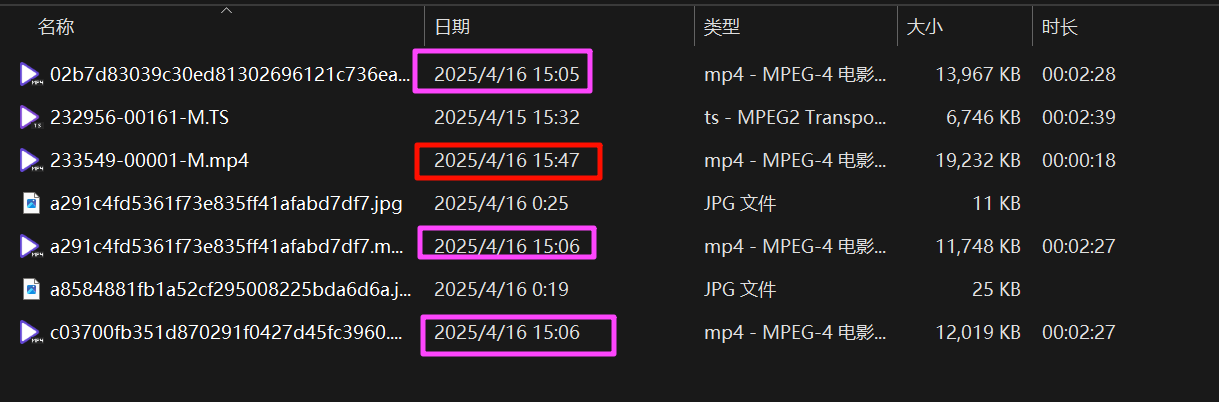
其实看修改时间,文件名,视频时长也可以,但不是特别严谨。
ea7be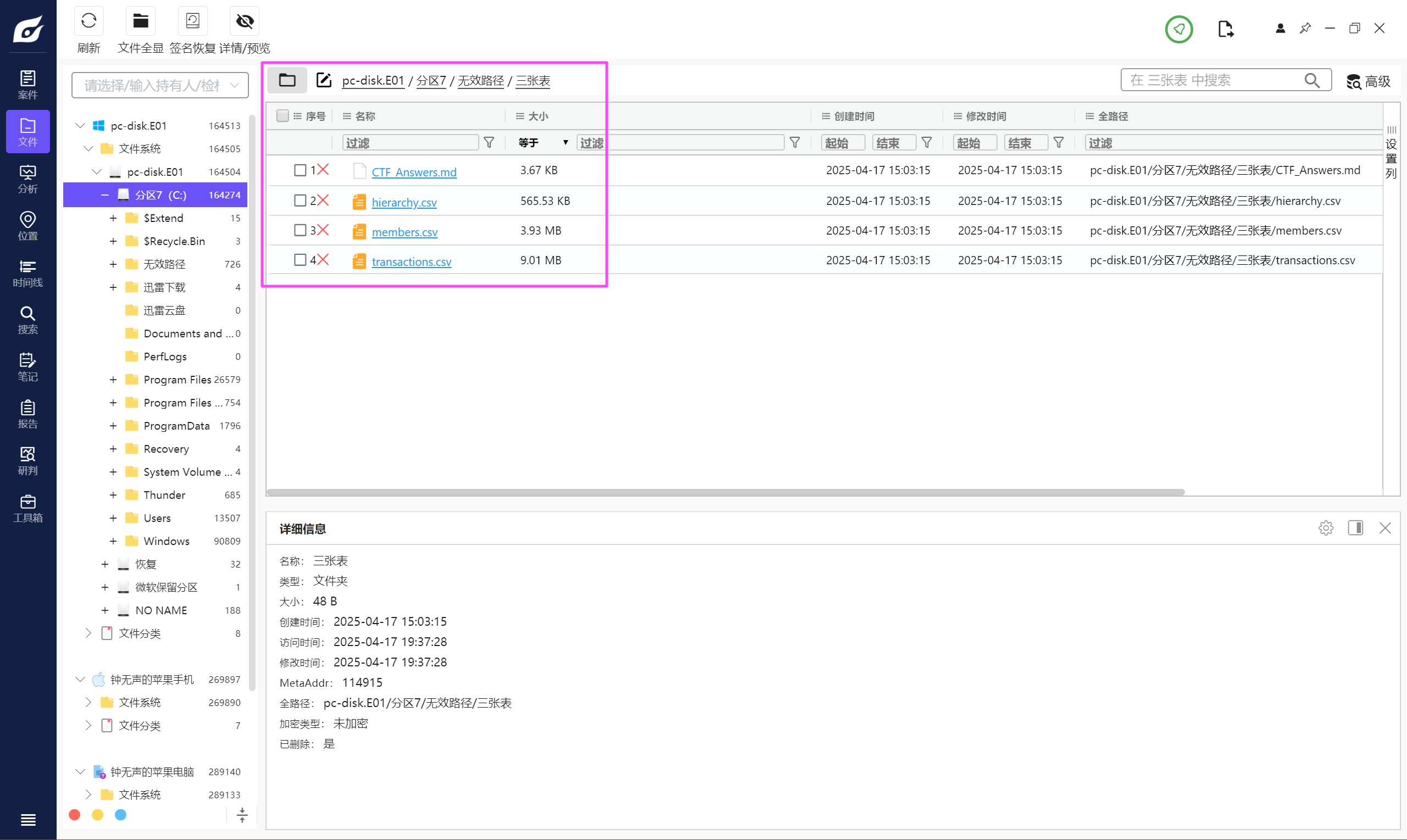
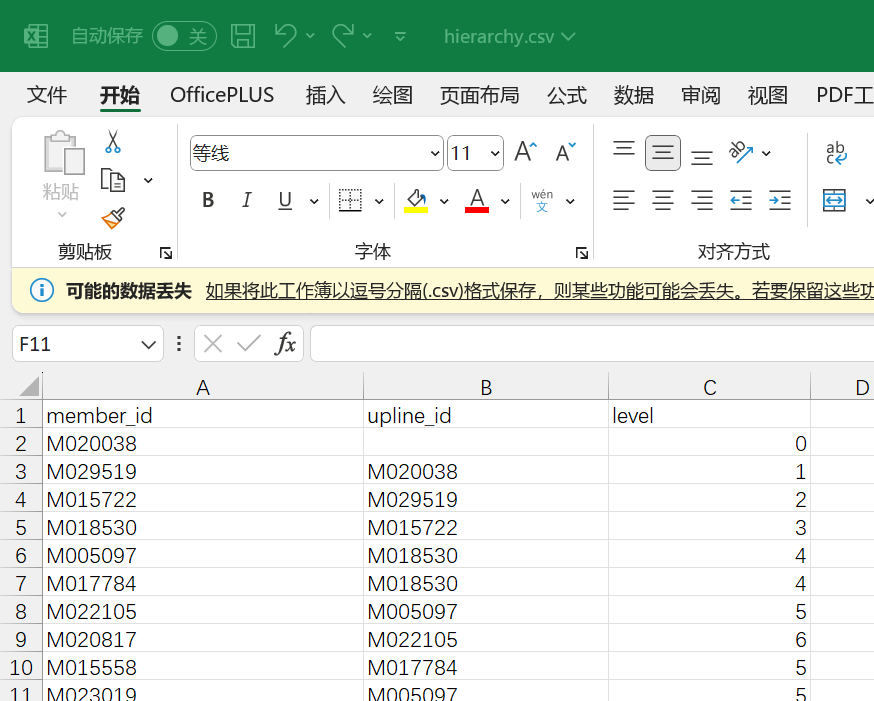
level 是 0,没有 upline_id 的就是最高级,也就是这个 M020038。
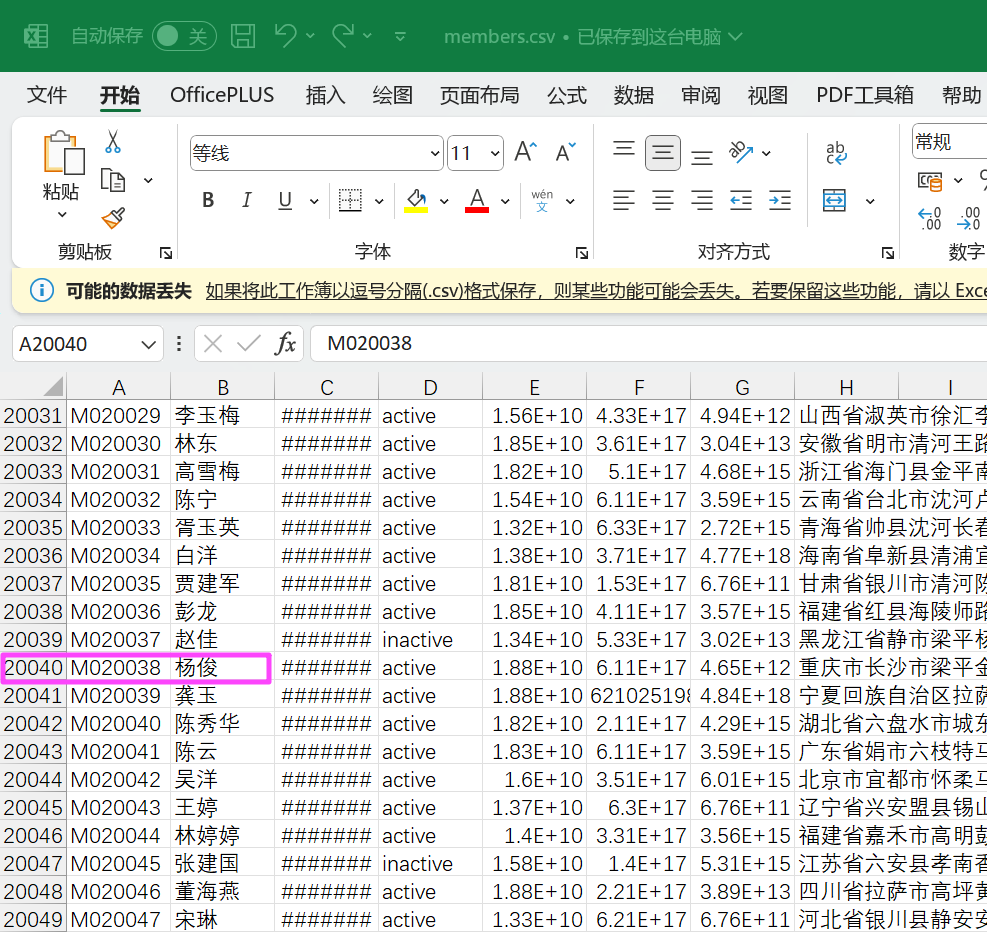
M020038 杨俊import csv
from collections import defaultdict
def get_column(fieldnames, keywords):
"""动态匹配包含关键字的列名"""
for col in fieldnames:
for kw in keywords:
if kw.lower() in col.lower():
return col
return None
# 读取层级数据
hierarchy = defaultdict(list)
top_leader = None
with open('hierarchy.csv', 'r', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
# 动态识别列名
member_col = get_column(reader.fieldnames, ['member'])
upline_col = get_column(reader.fieldnames, ['upline'])
level_col = get_column(reader.fieldnames, ['level'])
# 查找最高领导
for row in reader:
if row[level_col] == '0' and not row[upline_col].strip():
top_leader = row[member_col]
break
# 构建层级关系
f.seek(0)
next(reader) # 跳过标题行
for row in reader:
if row[upline_col].strip():
hierarchy[row[upline_col]].append(row[member_col])
if not top_leader:
raise ValueError("找不到最高领导")
# 收集所有下线成员
subordinates = []
queue = [top_leader]
while queue:
current = queue.pop(0)
if current in hierarchy:
queue.extend(hierarchy[current])
subordinates.extend(hierarchy[current])
# 统计提现金额
withdrawals = defaultdict(float)
with open('transactions.csv', 'r', encoding='utf-8-sig') as f:
reader = csv.DictReader(f)
payer_col = get_column(reader.fieldnames, ['payer'])
type_col = get_column(reader.fieldnames, ['type'])
amount_col = get_column(reader.fieldnames, ['amount'])
for row in reader:
if row[type_col].lower() == 'withdrawal' and row[payer_col] in subordinates:
try:
withdrawals[row[payer_col]] += float(row[amount_col])
except ValueError:
pass
# 输出结果
if withdrawals:
max_member = max(withdrawals.items(), key=lambda x: x[1])
print(max_member[0])
else:
print("无提现记录")
M019024import pandas as pd
# 读取 CSV 文件
hierarchy = pd.read_csv('hierarchy.csv')
members = pd.read_csv('members.csv')
transactions = pd.read_csv('transactions.csv')
# 获取每个成员的直接下线
direct_downlines = hierarchy[['member_id', 'upline_id']]
# 过滤出佣金交易
commission_transactions = transactions[transactions['type'] == 'commission']
# 将交易数据按成员ID分组,计算每个成员的总佣金
commission_received = commission_transactions.groupby('payee_id')['amount'].sum().reset_index()
# 计算每个成员的直接下线
downline_count = hierarchy.groupby('upline_id').size().reset_index(name='num_downlines')
# 合并直接下线数据
direct_downlines = pd.merge(direct_downlines, downline_count, left_on='member_id', right_on='upline_id', how='left')
# 合并佣金数据
merged = pd.merge(direct_downlines, commission_received, left_on='member_id', right_on='payee_id', how='left')
# 计算每个成员的平均佣金
merged['average_commission'] = merged['amount'] / merged['num_downlines']
# 找到佣金最高的成员及其金额
max_commission_member = merged.loc[merged['average_commission'].idxmax()]
# 输出结果
print(f"{max_commission_member['member_id']},{max_commission_member['average_commission']:.2f}")
M003564,2630.70import pandas as pd
import math
# 读取数据
members = pd.read_csv('members.csv')
transactions = pd.read_csv('transactions.csv')
# 转换注册时间为 datetime
members['registration_date'] = pd.to_datetime(members['registration_date'])
# 排序,取前 10% 注册时间最早的成员
members_sorted = members.sort_values(by='registration_date')
top_10_percent_count = math.ceil(len(members_sorted) * 0.1)
top_10_percent_members = members_sorted.head(top_10_percent_count)
# 获取这部分成员的 ID 列表
top_ids = top_10_percent_members['member_id'].tolist()
# 统计交易次数(作为付款人或收款人)
transactions_filtered = transactions[
transactions['payer_id'].isin(top_ids) | transactions['payee_id'].isin(top_ids)
]
# 计算每位成员的交易次数
from collections import Counter
count = Counter(transactions_filtered['payer_id'].tolist() + transactions_filtered['payee_id'].tolist())
# 构造完整的交易次数记录(即使为 0)
transaction_counts = {member_id: count.get(member_id, 0) for member_id in top_ids}
# 找出交易次数最少的 5 位成员
lowest_5 = sorted(transaction_counts.items(), key=lambda x: x[1])[:5]
# 提取并格式化成员 ID
result = ",".join([member_id for member_id, _ in lowest_5])
print(f"结果是: {result}")
M003135,M004208,M018368,M016076,M016119import pandas as pd
# 读取交易数据
transactions = pd.read_csv("transactions.csv", parse_dates=["timestamp"])
# 提取年份
transactions['year'] = transactions['timestamp'].dt.year
# 构建参与成员的交易记录(payer + payee)
payer_counts = transactions.groupby(['year', 'payer_id']).size().reset_index(name='count')
payee_counts = transactions.groupby(['year', 'payee_id']).size().reset_index(name='count')
# 统一列名
payer_counts.rename(columns={'payer_id': 'member_id'}, inplace=True)
payee_counts.rename(columns={'payee_id': 'member_id'}, inplace=True)
# 合并 payer 和 payee 的交易次数
all_counts = pd.concat([payer_counts, payee_counts])
member_year_counts = all_counts.groupby(['member_id', 'year'])['count'].sum().reset_index()
# 计算增长率
member_year_counts.sort_values(['member_id', 'year'], inplace=True)
member_year_counts['prev_count'] = member_year_counts.groupby('member_id')['count'].shift(1)
member_year_counts['growth_rate'] = ((member_year_counts['count'] - member_year_counts['prev_count']) / member_year_counts['prev_count']) * 100
# 去除无法计算增长率的(如前一年为 0 或 NaN)
valid_growth = member_year_counts.dropna(subset=['growth_rate'])
valid_growth = valid_growth[valid_growth['prev_count'] > 0]
# 找到增长率最高的成员
max_growth_row = valid_growth.loc[valid_growth['growth_rate'].idxmax()]
member_id = max_growth_row['member_id']
growth = max_growth_row['growth_rate']
# 输出结果
print(f"{member_id},{growth:.2f}%")
M003288,2100.00%import pandas as pd
from datetime import timedelta
import math
# 读取数据
members = pd.read_csv('members.csv')
transactions = pd.read_csv('transactions.csv', parse_dates=['timestamp'])
# 筛选活跃成员
active_members = members[members['status'] == 'active']['member_id']
# 计算最后交易时间(payer或payee)
payer_records = transactions[['payer_id', 'timestamp']].rename(columns={'payer_id': 'member_id'})
payee_records = transactions[['payee_id', 'timestamp']].rename(columns={'payee_id': 'member_id'})
all_records = pd.concat([payer_records, payee_records])
last_transaction = all_records.groupby('member_id')['timestamp'].max().reset_index()
# 计算购买总额(仅作为payer)
payer_total = transactions.groupby('payer_id')['amount'].sum().reset_index().rename(columns={'payer_id': 'member_id'})
# 合并数据
active_df = pd.merge(
pd.DataFrame({'member_id': active_members}),
last_transaction,
how='left',
on='member_id'
).merge(
payer_total,
how='left',
on='member_id'
).fillna({'amount': 0})
# 设置基准时间
baseline_time = transactions['timestamp'].max() if not transactions.empty else pd.Timestamp.now()
cutoff = baseline_time - timedelta(days=90)
# 标记90天无交易
active_df['no_trade_90d'] = active_df['timestamp'].isna() | (active_df['timestamp'] < cutoff)
# 计算前20%阈值
sorted_amounts = active_df['amount'].sort_values(ascending=False)
threshold = sorted_amounts.iloc[math.ceil(len(active_df)*0.2)-1] if not active_df.empty else 0
# 统计最终结果
result = active_df[(active_df['no_trade_90d']) & (active_df['amount'] >= threshold)]
print(f"[{len(result)}]")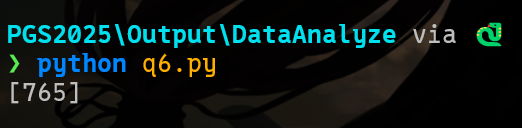
765import pandas as pd
# 读取 hierarchy.csv
hierarchy = pd.read_csv('hierarchy.csv')
# 过滤出有上线的成员(即他们本身有 upline_id)
has_upline = hierarchy[hierarchy['upline_id'].notna()]
# 统计每个成员作为 upline_id 出现的次数(即他们的直接下线数量)
downline_counts = has_upline['upline_id'].value_counts()
# 但题目要求只考虑有上线的人,所以需要交集:
# 先列出所有有上线的成员
members_with_upline = set(hierarchy[hierarchy['upline_id'].notna()]['member_id'])
# 筛选统计中只保留那些本身也有上线的成员
filtered_downline_counts = downline_counts[downline_counts.index.isin(members_with_upline)]
# 找到下线最多的成员
if not filtered_downline_counts.empty:
top_member = filtered_downline_counts.idxmax()
top_count = filtered_downline_counts.max()
print(f"{top_member}:{top_count}")
else:
print("无符合条件的成员。")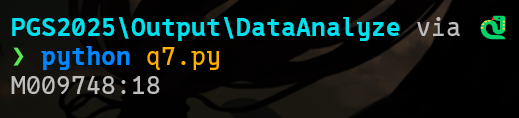
M009748:18import pandas as pd
# 读取 CSV 文件
members = pd.read_csv("members.csv", parse_dates=["registration_date"])
transactions = pd.read_csv("transactions.csv")
# 提取季度信息
members['quarter'] = members['registration_date'].dt.quarter
members['year'] = members['registration_date'].dt.year
# 筛选最早年份
earliest_year = members['year'].min()
q1_members = members[(members['year'] == earliest_year) & (members['quarter'] == 1)]
q4_members = members[(members['year'] == earliest_year) & (members['quarter'] == 4)]
# 获取会员ID列表
q1_ids = set(q1_members['member_id'])
q4_ids = set(q4_members['member_id'])
# 计算Q1总交易额(作为付款方或收款方)
q1_transactions = transactions[
(transactions['payer_id'].isin(q1_ids)) | (transactions['payee_id'].isin(q1_ids))
]
q1_total = q1_transactions['amount'].sum()
# 计算Q4总交易额
q4_transactions = transactions[
(transactions['payer_id'].isin(q4_ids)) | (transactions['payee_id'].isin(q4_ids))
]
q4_total = q4_transactions['amount'].sum()
# 比较并输出结果
if q1_total > q4_total:
print(f"Q1:{q1_total:.2f}")
else:
print(f"Q4:{q4_total:.2f}")
Q1:18161858.93import csv
import re
def extract_province(address):
match = re.match(r'^(.+?(省|市|自治区|特别行政区))', address)
return match.group(1) if match else None
# 读取members.csv,先验证列名
with open('members.csv', 'r', encoding='utf-8-sig') as file: # 处理BOM标记
reader = csv.DictReader(file)
# 打印实际列名用于调试
print("CSV列名:", reader.fieldnames)
# 自动匹配member_id列(处理大小写或空格)
member_id_col = next((col for col in reader.fieldnames if 'member_id' in col.lower()), None)
if not member_id_col:
raise ValueError("CSV文件中找不到member_id列")
province_count = {}
members_province = {}
for row in reader:
province = extract_province(row['address'])
if province:
province_count[province] = province_count.get(province, 0) + 1
members_province[row[member_id_col]] = province # 使用动态匹配的列名
# 找到出现次数最多的省份
max_province = max(province_count, key=lambda k: province_count[k])
# 收集该省份的member_id列表
province_member_ids = [mid for mid, p in members_province.items() if p == max_province]
# 计算总提现金额
total_withdrawal = 0.0
with open('transactions.csv', 'r', encoding='utf-8') as file:
reader = csv.DictReader(file)
for row in reader:
if row['type'] == 'withdrawal' and row['payer_id'] in province_member_ids:
total_withdrawal += float(row['amount'])
# 格式化输出结果
print(province_count)
#print(members_province)
print(f"{max_province},{total_withdrawal:.2f}")
江苏省,2301065.13收入-支出即可。
import pandas as pd
# 读取数据
hierarchy = pd.read_csv("hierarchy.csv")
transactions = pd.read_csv("transactions.csv")
# 找出最高层领导者(level == 0)
top_leaders = hierarchy[hierarchy['level'] == 0]['member_id']
# 过滤他们的交易记录
inflow = transactions[transactions['payee_id'].isin(top_leaders)]['amount'].sum()
outflow = transactions[transactions['payer_id'].isin(top_leaders)]['amount'].sum()
# 计算净资金流
net_flow = inflow - outflow
# 输出结果(保留两位小数)
print(f"{net_flow:.2f}")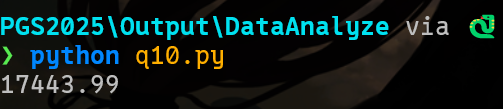
17443.99